Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning
2402.00530
0
0
Abstract
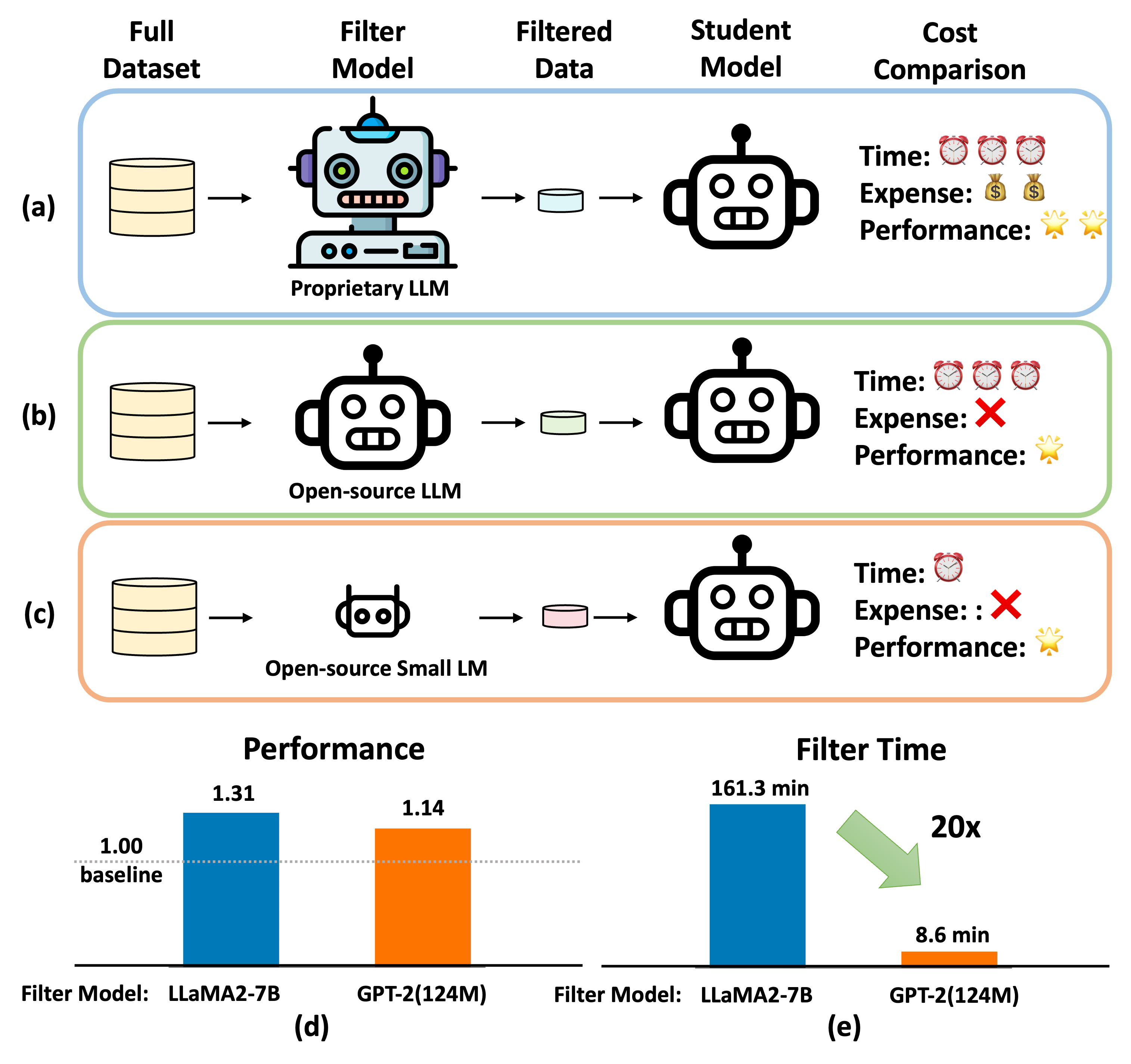
Instruction tuning is critical to improve LLMs but usually suffers from low-quality and redundant data. Data filtering for instruction tuning has proved important in improving both the efficiency and performance of the tuning process. But it also leads to extra cost and computation due to the involvement of LLMs in this process. To reduce the filtering cost, we study Superfiltering: Can we use a smaller and weaker model to select data for finetuning a larger and stronger model? Despite the performance gap between weak and strong language models, we find their highly consistent capability to perceive instruction difficulty and data selection results. This enables us to use a much smaller and more efficient model to filter the instruction data used to train a larger language model. Not only does it largely speed up the data filtering, but the filtered-data-finetuned LLM achieves even better performance on standard benchmarks. Extensive experiments validate the efficacy and efficiency of our approach.
Create account to get full access
Overview
• The provided paper introduces "Superfiltering," a novel approach for fast instruction-tuning of large language models. • Superfiltering is a data filtering method that transitions from weak to strong filters, enabling efficient training on a small subset of the original dataset. • This technique can lead to significant training speedups while maintaining the performance of the final model.
Plain English Explanation
Imagine you're a chef trying to create a new dish. You start with a huge pile of ingredients, but you don't need to use all of them to make a delicious meal. Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning is like a technique that helps you quickly identify the most important ingredients you need, so you can focus on those and create your dish faster, without sacrificing the quality.
In the context of training large language models, the "ingredients" are the massive datasets used for instruction-tuning. Superfiltering helps researchers find the most relevant subset of this data, allowing them to train their models more efficiently. This is especially useful when working with limited computational resources or needing to iterate quickly on model development.
The key idea is to start with a "weak" filter that roughly identifies the useful data, then gradually transition to a "strong" filter that hones in on the most important samples. This step-by-step approach is more effective than using a single, rigid filter, which might miss important information or be too restrictive.
By using Superfiltering, researchers can train their models faster without sacrificing performance, potentially accelerating the pace of progress in natural language processing and other AI fields that rely on large language models.
Technical Explanation
The paper introduces the Superfiltering method, which is a novel data filtering approach for fast instruction-tuning of large language models. The core idea is to transition from a "weak" filter to a "strong" filter during the training process, allowing the model to efficiently focus on the most relevant subset of the original dataset.
The method works as follows:
- Weak Filtering: The authors first apply a weak filter to the dataset, which roughly identifies the potentially useful data samples. This filter is cheap to compute and has high recall, but low precision.
- Strong Filtering: As training progresses, the authors gradually transition to a stronger filter that is more discriminative and focuses on the most important data samples. This filter has higher precision but lower recall.
- Iterative Refinement: The authors alternate between weak and strong filtering, refining the data selection at each stage. This allows the model to converge to a high-performing solution using only a small subset of the original data.
The authors evaluate their approach on several instruction-tuning benchmarks, including PALM, ConTuning, and G-DiG. They demonstrate that Superfiltering can achieve significant training speedups (up to 5x) while maintaining the performance of the final model.
Critical Analysis
The paper presents a compelling approach to improving the efficiency of instruction-tuning for large language models. The key strengths of Superfiltering are its ability to identify the most relevant data samples and the flexibility to adapt the filtering strategy during training.
However, the paper does not fully explore the limitations of the method. For example, the performance of Superfiltering may depend on the quality and characteristics of the initial dataset, and the authors do not investigate how it might perform on more diverse or noisy datasets. Additionally, the paper does not consider the potential trade-offs between training speed and final model performance, which could be an important factor in real-world applications.
Further research could explore the boundaries of Superfiltering's effectiveness, such as investigating its performance on large-language-model-guided document selection or exploring alternative filtering strategies and their impact on the training process.
Conclusion
The Superfiltering approach presented in this paper offers a promising solution for improving the efficiency of instruction-tuning for large language models. By transitioning from weak to strong data filters, the method can significantly reduce training time while maintaining the performance of the final model.
This work has the potential to accelerate the development and adoption of powerful language models, which are increasingly crucial for a wide range of natural language processing tasks. As the field of AI continues to advance, techniques like Superfiltering will likely become increasingly important for managing the growing complexity and scale of language model training.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LESS: Selecting Influential Data for Targeted Instruction Tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, Danqi Chen
0
0
Instruction tuning has unlocked powerful capabilities in large language models (LLMs), effectively using combined datasets to develop generalpurpose chatbots. However, real-world applications often require a specialized suite of skills (e.g., reasoning). The challenge lies in identifying the most relevant data from these extensive datasets to effectively develop specific capabilities, a setting we frame as targeted instruction tuning. We propose LESS, an optimizer-aware and practically efficient algorithm to effectively estimate data influences and perform Low-rank gradiEnt Similarity Search for instruction data selection. Crucially, LESS adapts existing influence formulations to work with the Adam optimizer and variable-length instruction data. LESS first constructs a highly reusable and transferable gradient datastore with low-dimensional gradient features and then selects examples based on their similarity to few-shot examples embodying a specific capability. Experiments show that training on a LESS-selected 5% of the data can often outperform training on the full dataset across diverse downstream tasks. Furthermore, the selected data is highly transferable: smaller models can be leveraged to select useful data for larger models and models from different families. Our qualitative analysis shows that our method goes beyond surface form cues to identify data that exemplifies the necessary reasoning skills for the intended downstream application.
6/14/2024
Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning
Ming Li, Lichang Chen, Jiuhai Chen, Shwai He, Jiuxiang Gu, Tianyi Zhou
0
0
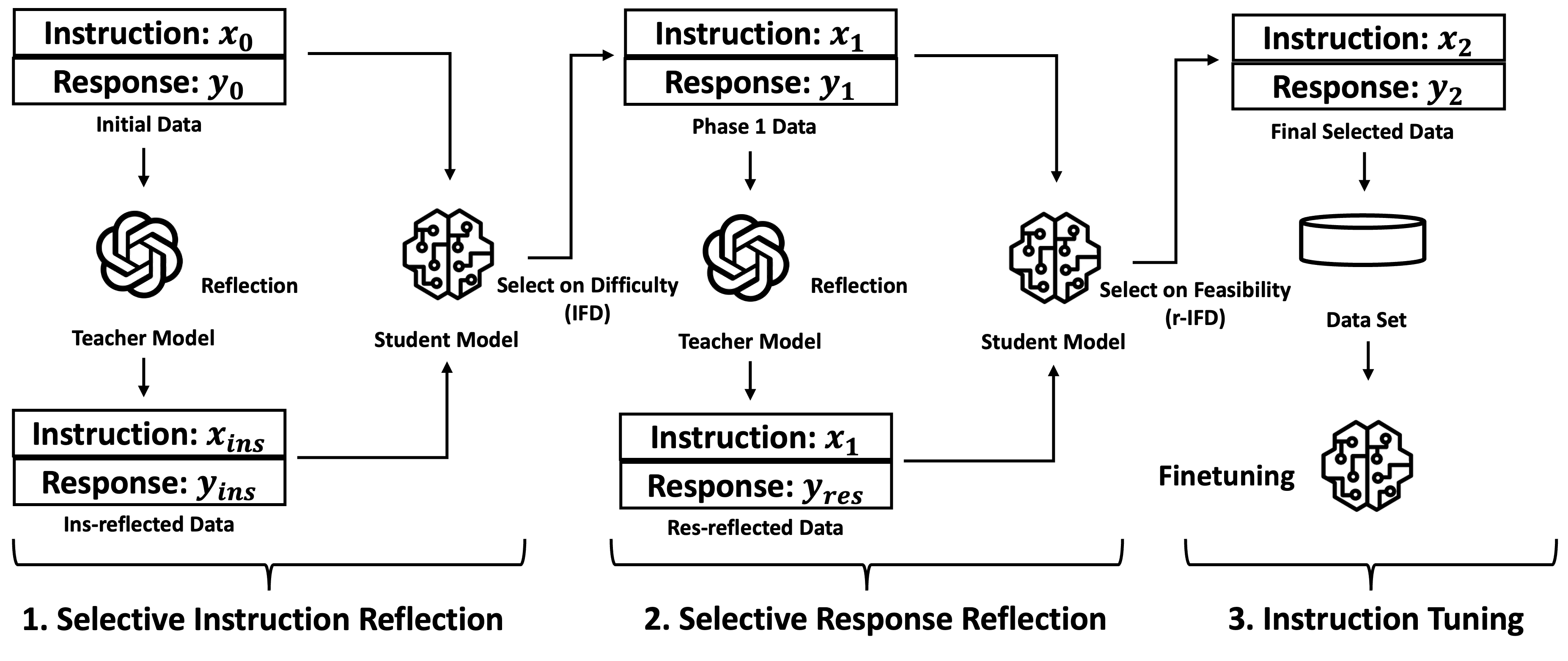
Instruction tuning is critical to large language models (LLMs) for achieving better instruction following and task adaptation capabilities but its success heavily relies on the training data quality. Many recent methods focus on improving the data quality but often overlook the compatibility of the data with the student model being finetuned. This paper introduces Selective Reflection-Tuning, a novel paradigm that synergizes a teacher LLM's reflection and introspection for improving existing data quality with the data selection capability of the student LLM, to automatically refine existing instruction-tuning data. This teacher-student collaboration produces high-quality and student-compatible instruction-response pairs, resulting in sample-efficient instruction tuning and LLMs of superior performance. Selective Reflection-Tuning is a data augmentation and synthesis that generally improves LLM finetuning and self-improvement without collecting brand-new data. We apply our method to Alpaca and WizardLM data and achieve much stronger and top-tier 7B and 13B LLMs.
6/11/2024
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
0
0
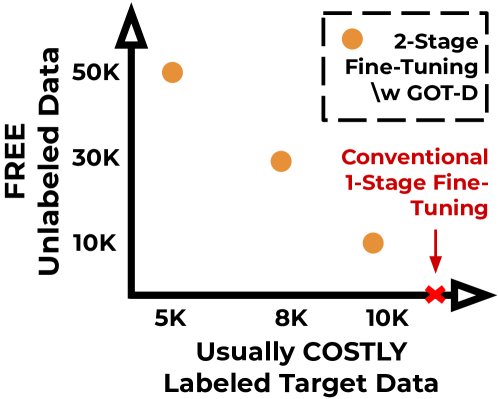
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
5/7/2024
Take the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models
Ziche Liu, Rui Ke, Feng Jiang, Haizhou Li
0
0
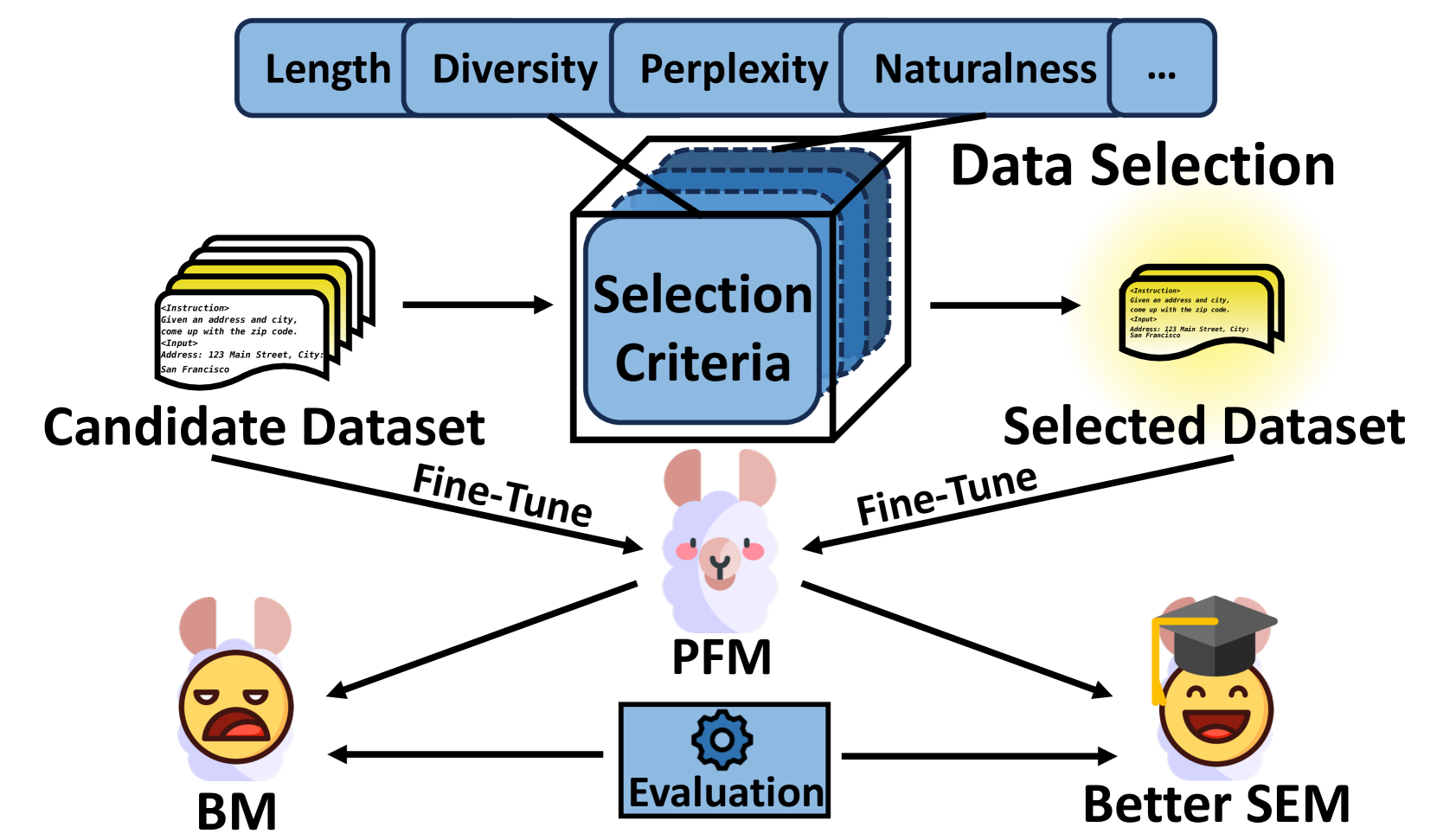
Data selection for fine-tuning Large Language Models (LLMs) aims to select a high-quality subset from a given candidate dataset to train a Pending Fine-tune Model (PFM) into a Selective-Enhanced Model (SEM). It can improve the model performance and accelerate the training process. Although a few surveys have investigated related works of data selection, there is a lack of comprehensive comparison between existing methods due to their various experimental settings. To address this issue, we first propose a three-stage scheme for data selection and comprehensively review existing works according to this scheme. Then, we design a unified comparing method with ratio-based efficiency indicators and ranking-based feasibility indicators to overcome the difficulty of comparing various models with diverse experimental settings. After an in-depth comparative analysis, we find that the more targeted method with data-specific and model-specific quality labels has higher efficiency, but the introduction of additional noise information should be avoided when designing selection algorithms. Finally, we summarize the trends in data selection and highlight the short-term and long-term challenges to guide future research.
6/21/2024