Supervised Representation Learning towards Generalizable Assembly State Recognition

0
Sign in to get full access
Overview
- Supervised representation learning for assembly state recognition
- Generalizable approach to detect assembly states from visual data
- Focuses on learning robust and transferable visual representations
Plain English Explanation
This research paper proposes a supervised representation learning approach for assembly state recognition. The goal is to develop a generalizable system that can accurately detect the current state of an assembly process from visual data, like camera footage.
The key idea is to learn visual representations that are robust and transferable, allowing the model to work well across different assembly tasks and environments. This is achieved through a semi-supervised training approach that leverages both labeled and unlabeled data.
The researchers demonstrate the effectiveness of their approach on a range of assembly state recognition tasks, showing improved performance compared to previous methods. This work has the potential to enhance computer vision for manufacturing applications, enabling more reliable and adaptable assembly monitoring systems.
Technical Explanation
The paper proposes a supervised representation learning framework for assembly state recognition. The approach involves training a deep neural network to learn visual representations that are both discriminative for the assembly state classification task and generalizable across different assembly scenarios.
The framework consists of three key components:
- Visual Backbone: A convolutional neural network that extracts visual features from input images.
- State Classifier: A classification head that maps the visual features to assembly state predictions.
- Representation Regularizer: An additional objective that encourages the learned representations to be invariant to task-irrelevant factors, such as viewpoint or background.
The model is trained in a semi-supervised manner, utilizing both labeled assembly state data and unlabeled visual data. This helps the model learn more robust and transferable representations that can generalize to new assembly tasks and environments.
The researchers evaluate their approach on several assembly state recognition benchmarks, demonstrating improved performance compared to previous methods. The learned representations also show strong transfer learning capabilities, allowing the model to achieve high accuracy on novel assembly tasks with limited training data.
Critical Analysis
The paper presents a well-designed and thorough approach to supervised representation learning for assembly state recognition. The proposed framework is theoretically sound and the experimental results are convincing.
One potential limitation is the reliance on labeled assembly state data, which can be costly and time-consuming to acquire in practice. While the semi-supervised aspect helps mitigate this, further research could explore unsupervised or self-supervised representation learning approaches to reduce the need for manual labeling.
Additionally, the paper focuses on visual-based assembly state recognition, but it may be beneficial to explore multimodal approaches that incorporate other sensor data, such as force, torque, or audio, to further improve the robustness and generalization of the system.
Conclusion
This research paper presents a supervised representation learning framework for assembly state recognition, with a focus on developing generalizable visual representations. The proposed approach demonstrates strong performance on various assembly state recognition tasks, showcasing its potential to enhance computer vision for manufacturing applications.
By learning robust and transferable visual representations, the system can be more easily deployed across different assembly scenarios, reducing the need for costly manual labeling and retraining. This work contributes to the ongoing efforts in the field of representation learning and its applications in industrial and manufacturing domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Supervised Representation Learning towards Generalizable Assembly State Recognition
Tim J. Schoonbeek, Goutham Balachandran, Hans Onvlee, Tim Houben, Shao-Hsuan Hung, Jacek Kustra, Peter H. N. de With, Fons van der Sommen
Assembly state recognition facilitates the execution of assembly procedures, offering feedback to enhance efficiency and minimize errors. However, recognizing assembly states poses challenges in scalability, since parts are frequently updated, and the robustness to execution errors remains underexplored. To address these challenges, this paper proposes an approach based on representation learning and the novel intermediate-state informed loss function modification (ISIL). ISIL leverages unlabeled transitions between states and demonstrates significant improvements in clustering and classification performance for all tested architectures and losses. Despite being trained exclusively on images without execution errors, thorough analysis on error states demonstrates that our approach accurately distinguishes between correct states and states with various types of execution errors. The integration of the proposed algorithm can offer meaningful assistance to workers and mitigate unexpected losses due to procedural mishaps in industrial settings. The code is available at: https://timschoonbeek.github.io/state_rec
Read more8/22/2024

0
Find the Assembly Mistakes: Error Segmentation for Industrial Applications
Dan Lehman, Tim J. Schoonbeek, Shao-Hsuan Hung, Jacek Kustra, Peter H. N. de With, Fons van der Sommen
Recognizing errors in assembly and maintenance procedures is valuable for industrial applications, since it can increase worker efficiency and prevent unplanned down-time. Although assembly state recognition is gaining attention, none of the current works investigate assembly error localization. Therefore, we propose StateDiffNet, which localizes assembly errors based on detecting the differences between a (correct) intended assembly state and a test image from a similar viewpoint. StateDiffNet is trained on synthetically generated image pairs, providing full control over the type of meaningful change that should be detected. The proposed approach is the first to correctly localize assembly errors taken from real ego-centric video data for both states and error types that are never presented during training. Furthermore, the deployment of change detection to this industrial application provides valuable insights and considerations into the mechanisms of state-of-the-art change detection algorithms. The code and data generation pipeline are publicly available at: https://timschoonbeek.github.io/error_seg.
Read more8/26/2024
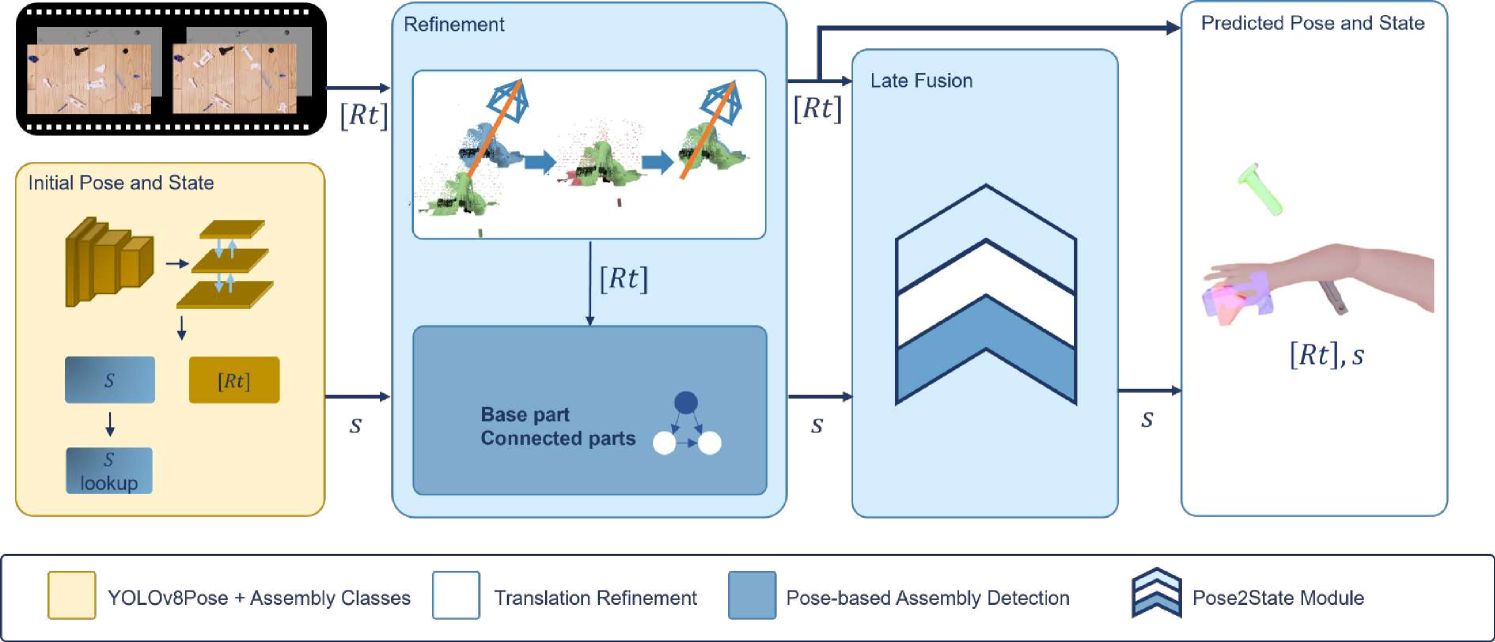
0
ASDF: Assembly State Detection Utilizing Late Fusion by Integrating 6D Pose Estimation
Hannah Schieber, Shiyu Li, Niklas Corell, Philipp Beckerle, Julian Kreimeier, Daniel Roth
In medical and industrial domains, providing guidance for assembly processes can be critical to ensure efficiency and safety. Errors in assembly can lead to significant consequences such as extended surgery times and prolonged manufacturing or maintenance times in industry. Assembly scenarios can benefit from in-situ augmented reality visualization, i.e., augmentations in close proximity to the target object, to provide guidance, reduce assembly times, and minimize errors. In order to enable in-situ visualization, 6D pose estimation can be leveraged to identify the correct location for an augmentation. Existing 6D pose estimation techniques primarily focus on individual objects and static captures. However, assembly scenarios have various dynamics, including occlusion during assembly and dynamics in the appearance of assembly objects. Existing work focus either on object detection combined with state detection, or focus purely on the pose estimation. To address the challenges of 6D pose estimation in combination with assembly state detection, our approach ASDF builds upon the strengths of YOLOv8, a real-time capable object detection framework. We extend this framework, refine the object pose, and fuse pose knowledge with network-detected pose information. Utilizing our late fusion in our Pose2State module results in refined 6D pose estimation and assembly state detection. By combining both pose and state information, our Pose2State module predicts the final assembly state with precision. The evaluation of our ASDF dataset shows that our Pose2State module leads to an improved assembly state detection and that the improvement of the assembly state further leads to a more robust 6D pose estimation. Moreover, on the GBOT dataset, we outperform the pure deep learning-based network and even outperform the hybrid and pure tracking-based approaches.
Read more8/12/2024

0
LLM-Empowered State Representation for Reinforcement Learning
Boyuan Wang, Yun Qu, Yuhang Jiang, Jianzhun Shao, Chang Liu, Wenming Yang, Xiangyang Ji
Conventional state representations in reinforcement learning often omit critical task-related details, presenting a significant challenge for value networks in establishing accurate mappings from states to task rewards. Traditional methods typically depend on extensive sample learning to enrich state representations with task-specific information, which leads to low sample efficiency and high time costs. Recently, surging knowledgeable large language models (LLM) have provided promising substitutes for prior injection with minimal human intervention. Motivated by this, we propose LLM-Empowered State Representation (LESR), a novel approach that utilizes LLM to autonomously generate task-related state representation codes which help to enhance the continuity of network mappings and facilitate efficient training. Experimental results demonstrate LESR exhibits high sample efficiency and outperforms state-of-the-art baselines by an average of 29% in accumulated reward in Mujoco tasks and 30% in success rates in Gym-Robotics tasks.
Read more7/19/2024