On Suppressing Range of Adaptive Stepsizes of Adam to Improve Generalisation Performance

0
🚀
Sign in to get full access
Overview
- The paper proposes a new adaptive optimizer called SET-Adam, which aims to improve the generalization performance of the popular Adam optimizer.
- SET-Adam applies three consecutive operations to the second momentum (v_t) of Adam: down-scaling, epsilon-embedding, and down-translating.
- The authors claim that SET-Adam outperforms eight other adaptive optimizers on a variety of natural language processing and computer vision tasks.
Plain English Explanation
The paper introduces a new algorithm called SET-Adam, which is an enhanced version of the popular Adam optimizer. The key idea behind SET-Adam is to better control the range of the adaptive step sizes used by Adam, which can sometimes lead to poor generalization performance.
The authors achieve this by performing three consecutive operations on the second momentum (v_t) of Adam before using it to update the model parameters. First, they "down-scale" the values in v_t by considering the angles between the layer-wise sub-vectors of v_t and corresponding all-one sub-vectors. This helps reduce the variance of the adaptive step sizes. Second, they "embed" a small constant (epsilon) into v_t to ensure the step sizes don't get too small. Finally, they "down-translate" v_t to further suppress the range of the step sizes.
The authors claim that these modifications to Adam's update rule lead to improved generalization performance on a variety of natural language processing and computer vision tasks, including training transformer and LSTM models for NLP, and VGG and ResNet models for image classification. They also show that SET-Adam can match the best performance of other adaptive methods on generative adversarial network (GAN) training tasks.
Technical Explanation
The paper proposes a new adaptive optimization algorithm called SET-Adam, which builds upon the popular Adam optimizer. The key motivation behind SET-Adam is to address the issue of poor generalization performance sometimes observed with Adam, which is thought to be due to the high variance of its adaptive step sizes.
To mitigate this problem, the authors propose three consecutive operations to be performed on the second momentum (v_t) of Adam before using it to update the model parameters:
-
Down-scaling: The authors down-scale the layer-wise sub-vectors of v_t based on the angles between these sub-vectors and the corresponding all-one sub-vectors. This helps reduce the variance of the adaptive step sizes.
-
Epsilon-embedding: The authors embed a small constant (epsilon) into v_t to ensure the step sizes don't get too small, which can cause optimization issues.
-
Down-translating: The authors down-translate v_t to further suppress the range of the adaptive step sizes.
The authors refer to this modified version of Adam as SET-Adam, where SET stands for the three operations performed on v_t.
The authors evaluate SET-Adam on a variety of natural language processing and computer vision tasks, including transformer and LSTM models for NLP, and VGG and ResNet models for image classification on CIFAR10 and CIFAR100 datasets. They also compare SET-Adam to eight other adaptive optimizers and show that it consistently outperforms them on these tasks. Additionally, the authors demonstrate that SET-Adam can match the best performance of the other adaptive methods when training WGAN-GP models for image generation tasks.
Critical Analysis
The paper presents a thoughtful approach to improving the generalization performance of the Adam optimizer by modifying the update rule to better control the range of the adaptive step sizes. The authors' theoretical motivation and experimental results are compelling, and the proposed SET-Adam algorithm seems promising.
However, the paper does not provide a comprehensive theoretical analysis of the convergence properties of SET-Adam, which would be helpful to understand its theoretical guarantees and limitations. Additionally, the authors do not discuss the computational overhead introduced by the three additional operations performed on the second momentum, which could be a concern for large-scale or real-time applications.
Furthermore, the paper does not explore the sensitivity of SET-Adam to hyperparameter settings, such as the choice of the epsilon value or the down-scaling and down-translating factors. Investigating the robustness of SET-Adam to these hyperparameters would be valuable for practitioners who may want to apply the algorithm to their own tasks.
Overall, the paper presents a promising new adaptive optimizer that appears to improve upon the generalization performance of Adam, but there are still some open questions and areas for further research that the authors could address in future work.
Conclusion
The paper introduces a new adaptive optimizer called SET-Adam, which aims to improve the generalization performance of the popular Adam optimizer by better controlling the range of its adaptive step sizes. The key idea behind SET-Adam is to perform three consecutive operations on the second momentum (v_t) of Adam: down-scaling, epsilon-embedding, and down-translating.
The authors' extensive experimental results show that SET-Adam outperforms eight other adaptive optimizers on a variety of natural language processing and computer vision tasks, while matching the best performance of these methods on generative adversarial network (GAN) training tasks. The paper provides a valuable contribution to the ongoing research on improving the effectiveness of adaptive optimization algorithms for deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
On Suppressing Range of Adaptive Stepsizes of Adam to Improve Generalisation Performance
Guoqiang Zhang
A number of recent adaptive optimizers improve the generalisation performance of Adam by essentially reducing the variance of adaptive stepsizes to get closer to SGD with momentum. Following the above motivation, we suppress the range of the adaptive stepsizes of Adam by exploiting the layerwise gradient statistics. In particular, at each iteration, we propose to perform three consecutive operations on the second momentum v_t before using it to update a DNN model: (1): down-scaling, (2): epsilon-embedding, and (3): down-translating. The resulting algorithm is referred to as SET-Adam, where SET is a brief notation of the three operations. The down-scaling operation on v_t is performed layerwise by making use of the angles between the layerwise subvectors of v_t and the corresponding all-one subvectors. Extensive experimental results show that SET-Adam outperforms eight adaptive optimizers when training transformers and LSTMs for NLP, and VGG and ResNet for image classification over CIAF10 and CIFAR100 while matching the best performance of the eight adaptive methods when training WGAN-GP models for image generation tasks. Furthermore, SET-Adam produces higher validation accuracies than Adam and AdaBelief for training ResNet18 over ImageNet.
Read more7/15/2024
0
Deconstructing What Makes a Good Optimizer for Language Models
Rosie Zhao, Depen Morwani, David Brandfonbrener, Nikhil Vyas, Sham Kakade
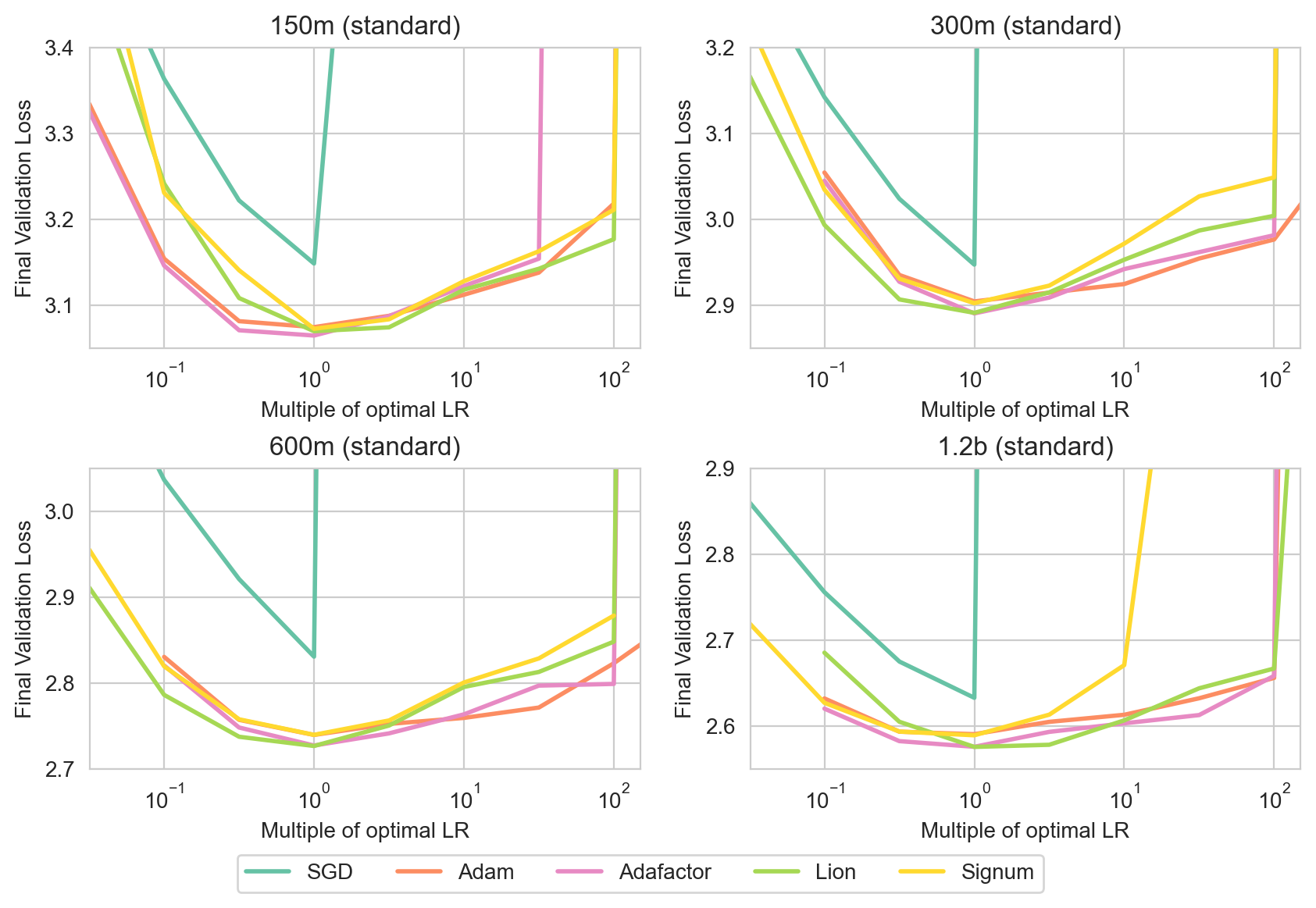
Training language models becomes increasingly expensive with scale, prompting numerous attempts to improve optimization efficiency. Despite these efforts, the Adam optimizer remains the most widely used, due to a prevailing view that it is the most effective approach. We aim to compare several optimization algorithms, including SGD, Adafactor, Adam, and Lion, in the context of autoregressive language modeling across a range of model sizes, hyperparameters, and architecture variants. Our findings indicate that, except for SGD, these algorithms all perform comparably both in their optimal performance and also in terms of how they fare across a wide range of hyperparameter choices. Our results suggest to practitioners that the choice of optimizer can be guided by practical considerations like memory constraints and ease of implementation, as no single algorithm emerged as a clear winner in terms of performance or stability to hyperparameter misspecification. Given our findings, we further dissect these approaches, examining two simplified versions of Adam: a) signed momentum (Signum) which we see recovers both the performance and hyperparameter stability of Adam and b) Adalayer, a layerwise variant of Adam which we introduce to study Adam's preconditioning. Examining Adalayer leads us to the conclusion that the largest impact of Adam's preconditioning is restricted to the last layer and LayerNorm parameters, and, perhaps surprisingly, the remaining layers can be trained with SGD.
Read more7/12/2024
0
Adam-mini: Use Fewer Learning Rates To Gain More
Yushun Zhang, Congliang Chen, Ziniu Li, Tian Ding, Chenwei Wu, Yinyu Ye, Zhi-Quan Luo, Ruoyu Sun
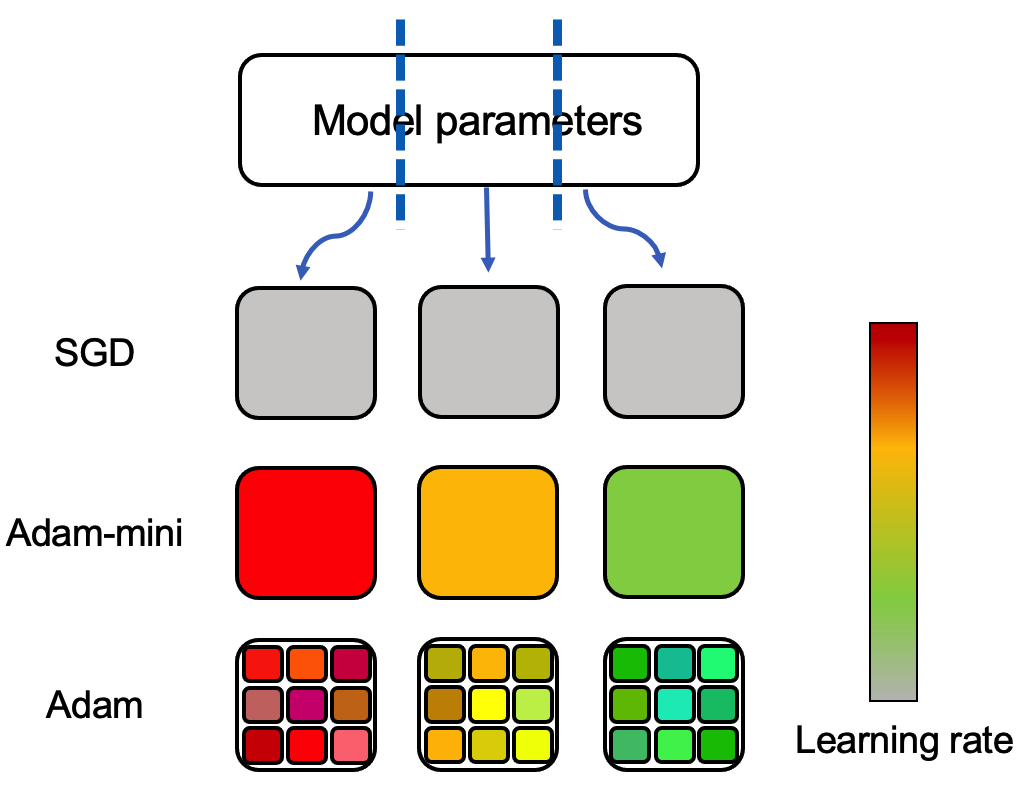
We propose Adam-mini, an optimizer that achieves on-par or better performance than AdamW with 45% to 50% less memory footprint. Adam-mini reduces memory by cutting down the learning rate resources in Adam (i.e., $1/sqrt{v}$). We find that $geq$ 90% of these learning rates in $v$ could be harmlessly removed if we (1) carefully partition the parameters into blocks following our proposed principle on Hessian structure; (2) assign a single but good learning rate to each parameter block. We further find that, for each of these parameter blocks, there exists a single high-quality learning rate that can outperform Adam, provided that sufficient resources are available to search it out. We then provide one cost-effective way to find good learning rates and propose Adam-mini. Empirically, we verify that Adam-mini performs on par or better than AdamW on various language models sized from 125M to 7B for pre-training, supervised fine-tuning, and RLHF. The reduced memory footprint of Adam-mini also alleviates communication overheads among GPUs and CPUs, thereby increasing throughput. For instance, Adam-mini achieves 49.6% higher throughput than AdamW when pre-training Llama2-7B on $2times$ A800-80GB GPUs, which saves 33% wall-clock time for pre-training.
Read more7/4/2024
⚙️
0
Convergence rates for the Adam optimizer
Steffen Dereich, Arnulf Jentzen
Stochastic gradient descent (SGD) optimization methods are nowadays the method of choice for the training of deep neural networks (DNNs) in artificial intelligence systems. In practically relevant training problems, usually not the plain vanilla standard SGD method is the employed optimization scheme but instead suitably accelerated and adaptive SGD optimization methods are applied. As of today, maybe the most popular variant of such accelerated and adaptive SGD optimization methods is the famous Adam optimizer proposed by Kingma & Ba in 2014. Despite the popularity of the Adam optimizer in implementations, it remained an open problem of research to provide a convergence analysis for the Adam optimizer even in the situation of simple quadratic stochastic optimization problems where the objective function (the function one intends to minimize) is strongly convex. In this work we solve this problem by establishing optimal convergence rates for the Adam optimizer for a large class of stochastic optimization problems, in particular, covering simple quadratic stochastic optimization problems. The key ingredient of our convergence analysis is a new vector field function which we propose to refer to as the Adam vector field. This Adam vector field accurately describes the macroscopic behaviour of the Adam optimization process but differs from the negative gradient of the objective function (the function we intend to minimize) of the considered stochastic optimization problem. In particular, our convergence analysis reveals that the Adam optimizer does typically not converge to critical points of the objective function (zeros of the gradient of the objective function) of the considered optimization problem but converges with rates to zeros of this Adam vector field.
Read more8/1/2024