Deconstructing What Makes a Good Optimizer for Language Models

0
Sign in to get full access
Overview
- Examines the key factors that make a good optimizer for training large language models
- Compares various optimizers, including AdaLomo, Efficiency Optimization, MADA, ADAM-Mini, and BADAM
- Evaluates the optimizers on measures like training time, memory usage, and performance on language modeling tasks
Plain English Explanation
This paper looks at what makes a good optimizer for training large language models, which are AI systems that can generate human-like text. The researchers compared different optimizers - the algorithms that update the model's parameters during training. They evaluated factors like how quickly the models trained, how much memory they used, and how well they performed on language tasks.
Some key optimizers they looked at include AdaLomo, which aims to use less memory, and MADA, which adapts its own hyperparameters during training. The goal was to find optimizers that can efficiently train large, powerful language models without requiring huge amounts of computing power and memory.
Technical Explanation
The paper compares the performance of several optimizers for training large language models. These include:
- AdaLomo: An optimizer designed to use less memory by maintaining a smaller set of per-parameter statistics.
- Efficiency Optimization: An approach that explicitly optimizes for training efficiency by dynamically adjusting hyperparameters.
- MADA: A "meta-adaptive" optimizer that can adapt its own hyperparameters during training using hypergradients.
- ADAM-Mini: A variant of the popular ADAM optimizer that uses fewer individual learning rates.
- BADAM: A memory-efficient full-parameter optimization method.
The researchers evaluate these optimizers on measures like training time, memory usage, and performance on language modeling tasks. They find that different optimizers exhibit different tradeoffs - some are more efficient in terms of memory usage, while others are faster to converge. The goal is to identify optimizers that can effectively train large, powerful language models without excessive computing requirements.
Critical Analysis
The paper provides a thorough and thoughtful comparison of several optimizers for training large language models. The researchers do a good job of highlighting the key strengths and weaknesses of each approach, and the experimental setup seems rigorous.
One potential limitation is that the comparisons are done on a relatively narrow set of language modeling tasks. It would be interesting to see how the optimizers perform on a broader range of natural language processing benchmarks. Additionally, the paper does not delve too deeply into the specific mechanics and hyperparameter settings of the different optimizers, which could make it harder for readers to fully understand the tradeoffs.
Overall, this is a valuable contribution to the ongoing research on efficient training of large-scale language models. The insights provided can help guide the development of more powerful and resource-efficient AI systems in the future.
Conclusion
This paper takes a deep dive into what makes a good optimizer for training large language models. By comparing the performance of various optimizers across metrics like training time, memory usage, and task-specific accuracy, the researchers shed light on the key factors to consider when selecting an optimizer for this challenging problem.
The findings suggest that there is no one-size-fits-all solution, and that different optimizers may be better suited for different scenarios and requirements. This underscores the importance of developing a diverse ecosystem of optimization techniques that can be tailored to the specific needs of each language modeling application.
As the field of natural language processing continues to advance, research like this will be crucial in enabling the development of ever-larger and more capable language models without exponential increases in computational costs. The insights and trade-offs examined in this paper can help guide the next generation of efficient and high-performing AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deconstructing What Makes a Good Optimizer for Language Models
Rosie Zhao, Depen Morwani, David Brandfonbrener, Nikhil Vyas, Sham Kakade
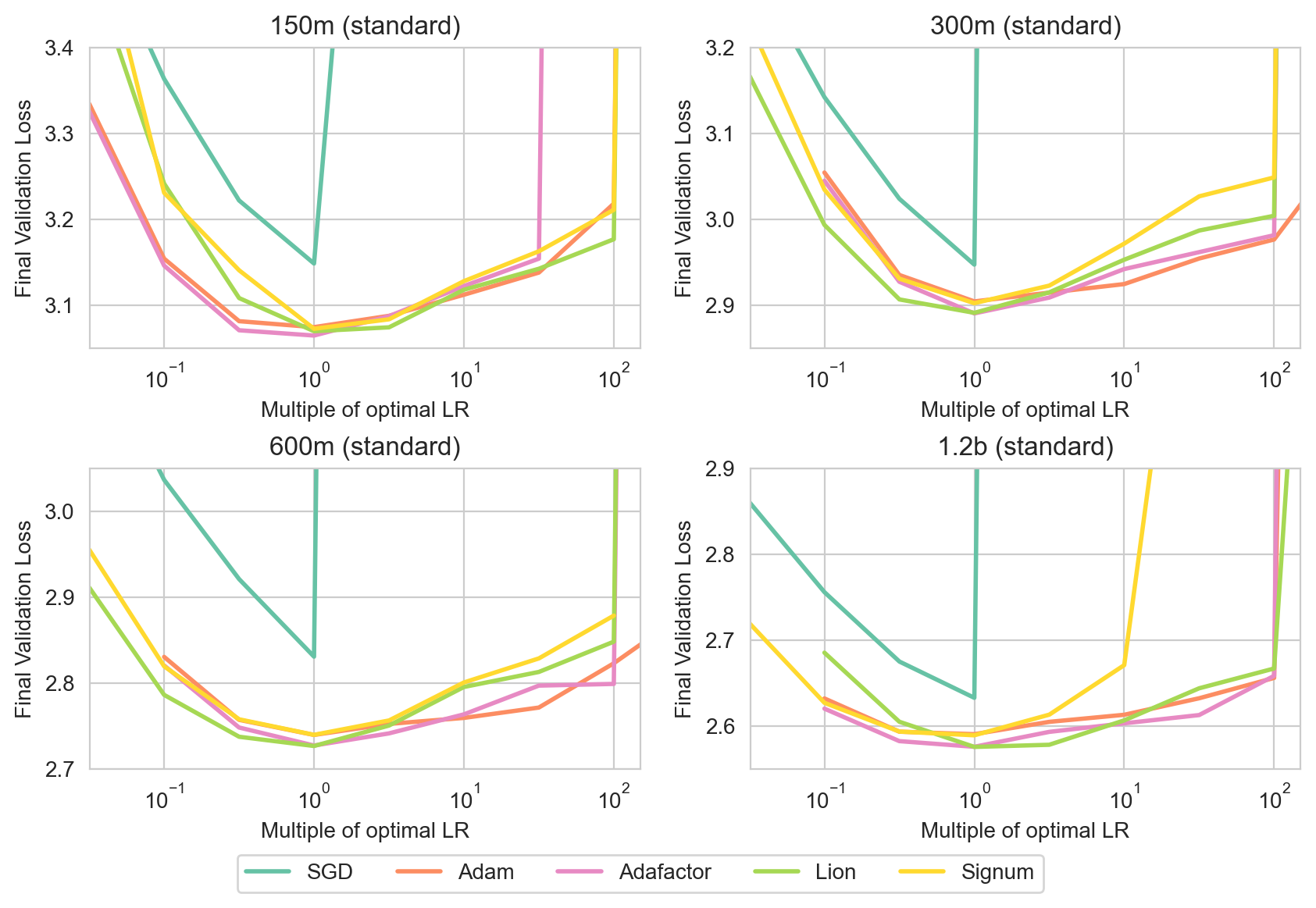
Training language models becomes increasingly expensive with scale, prompting numerous attempts to improve optimization efficiency. Despite these efforts, the Adam optimizer remains the most widely used, due to a prevailing view that it is the most effective approach. We aim to compare several optimization algorithms, including SGD, Adafactor, Adam, and Lion, in the context of autoregressive language modeling across a range of model sizes, hyperparameters, and architecture variants. Our findings indicate that, except for SGD, these algorithms all perform comparably both in their optimal performance and also in terms of how they fare across a wide range of hyperparameter choices. Our results suggest to practitioners that the choice of optimizer can be guided by practical considerations like memory constraints and ease of implementation, as no single algorithm emerged as a clear winner in terms of performance or stability to hyperparameter misspecification. Given our findings, we further dissect these approaches, examining two simplified versions of Adam: a) signed momentum (Signum) which we see recovers both the performance and hyperparameter stability of Adam and b) Adalayer, a layerwise variant of Adam which we introduce to study Adam's preconditioning. Examining Adalayer leads us to the conclusion that the largest impact of Adam's preconditioning is restricted to the last layer and LayerNorm parameters, and, perhaps surprisingly, the remaining layers can be trained with SGD.
Read more7/12/2024
🚀
0
On Suppressing Range of Adaptive Stepsizes of Adam to Improve Generalisation Performance
Guoqiang Zhang
A number of recent adaptive optimizers improve the generalisation performance of Adam by essentially reducing the variance of adaptive stepsizes to get closer to SGD with momentum. Following the above motivation, we suppress the range of the adaptive stepsizes of Adam by exploiting the layerwise gradient statistics. In particular, at each iteration, we propose to perform three consecutive operations on the second momentum v_t before using it to update a DNN model: (1): down-scaling, (2): epsilon-embedding, and (3): down-translating. The resulting algorithm is referred to as SET-Adam, where SET is a brief notation of the three operations. The down-scaling operation on v_t is performed layerwise by making use of the angles between the layerwise subvectors of v_t and the corresponding all-one subvectors. Extensive experimental results show that SET-Adam outperforms eight adaptive optimizers when training transformers and LSTMs for NLP, and VGG and ResNet for image classification over CIAF10 and CIFAR100 while matching the best performance of the eight adaptive methods when training WGAN-GP models for image generation tasks. Furthermore, SET-Adam produces higher validation accuracies than Adam and AdaBelief for training ResNet18 over ImageNet.
Read more7/15/2024
⚙️
0
Convergence rates for the Adam optimizer
Steffen Dereich, Arnulf Jentzen
Stochastic gradient descent (SGD) optimization methods are nowadays the method of choice for the training of deep neural networks (DNNs) in artificial intelligence systems. In practically relevant training problems, usually not the plain vanilla standard SGD method is the employed optimization scheme but instead suitably accelerated and adaptive SGD optimization methods are applied. As of today, maybe the most popular variant of such accelerated and adaptive SGD optimization methods is the famous Adam optimizer proposed by Kingma & Ba in 2014. Despite the popularity of the Adam optimizer in implementations, it remained an open problem of research to provide a convergence analysis for the Adam optimizer even in the situation of simple quadratic stochastic optimization problems where the objective function (the function one intends to minimize) is strongly convex. In this work we solve this problem by establishing optimal convergence rates for the Adam optimizer for a large class of stochastic optimization problems, in particular, covering simple quadratic stochastic optimization problems. The key ingredient of our convergence analysis is a new vector field function which we propose to refer to as the Adam vector field. This Adam vector field accurately describes the macroscopic behaviour of the Adam optimization process but differs from the negative gradient of the objective function (the function we intend to minimize) of the considered stochastic optimization problem. In particular, our convergence analysis reveals that the Adam optimizer does typically not converge to critical points of the objective function (zeros of the gradient of the objective function) of the considered optimization problem but converges with rates to zeros of this Adam vector field.
Read more8/1/2024

0
AdaLomo: Low-memory Optimization with Adaptive Learning Rate
Kai Lv, Hang Yan, Qipeng Guo, Haijun Lv, Xipeng Qiu
Large language models have achieved remarkable success, but their extensive parameter size necessitates substantial memory for training, thereby setting a high threshold. While the recently proposed low-memory optimization (LOMO) reduces memory footprint, its optimization technique, akin to stochastic gradient descent, is sensitive to hyper-parameters and exhibits suboptimal convergence, failing to match the performance of the prevailing optimizer for large language models, AdamW. Through empirical analysis of the Adam optimizer, we found that, compared to momentum, the adaptive learning rate is more critical for bridging the gap. Building on this insight, we introduce the low-memory optimization with adaptive learning rate (AdaLomo), which offers an adaptive learning rate for each parameter. To maintain memory efficiency, we employ non-negative matrix factorization for the second-order moment estimation in the optimizer state. Additionally, we suggest the use of a grouped update normalization to stabilize convergence. Our experiments with instruction-tuning and further pre-training demonstrate that AdaLomo achieves results on par with AdamW, while significantly reducing memory requirements, thereby lowering the hardware barrier to training large language models. The code is accessible at https://github.com/OpenLMLab/LOMO.
Read more6/7/2024