A Survey on Incomplete Multi-label Learning: Recent Advances and Future Trends
2406.06119
0
0

Abstract
In reality, data often exhibit associations with multiple labels, making multi-label learning (MLL) become a prominent research topic. The last two decades have witnessed the success of MLL, which is indispensable from complete and accurate supervised information. However, obtaining such information in practice is always laborious and sometimes even impossible. To circumvent this dilemma, incomplete multi-label learning (InMLL) has emerged, aiming to learn from incomplete labeled data. To date, enormous InMLL works have been proposed to narrow the performance gap with complete MLL, whereas a systematic review for InMLL is still absent. In this paper, we not only attempt to fill the lacuna but also strive to pave the way for innovative research. Specifically, we retrospect the origin of InMLL, analyze the challenges of InMLL, and make a taxonomy of InMLL from the data-oriented and algorithm-oriented perspectives, respectively. Besides, we also present real applications of InMLL in various domains. More importantly, we highlight several potential future trends, including four open problems that are more in line with practice and three under-explored/unexplored techniques in addressing the challenges of InMLL, which may shed new light on developing novel research directions in the field of InMLL.
Create account to get full access
Overview
- Discusses the field of Incomplete Multi-Label Learning (InMLL), which deals with datasets where some labels are missing for certain instances
- Provides a comprehensive survey of recent advances and future trends in InMLL
- Covers key topics such as the definition of InMLL, challenge formulations, evaluation metrics, and state-of-the-art methods
Plain English Explanation
Incomplete Multi-Label Learning (InMLL) is a machine learning problem where datasets have missing label information. In a typical multi-label learning task, each data point can have multiple labels associated with it. However, in real-world scenarios, it's common for some of these labels to be unknown or unobserved.
The paper surveys the recent progress and future directions in this field. It first defines the InMLL problem and outlines the key challenges, such as how to handle the missing labels and learn effective models. The paper then discusses various evaluation metrics used to assess InMLL models, as well as state-of-the-art techniques that have been developed to address the problem. These methods leverage ideas like transfer learning, probabilistic modeling, and multi-task learning to improve performance on datasets with incomplete label information.
Overall, the survey provides a comprehensive overview of the InMLL field, highlighting the importance of handling missing labels in real-world applications and the progress made in developing effective solutions. It also outlines promising future research directions, such as incorporating large language models and lifelong learning to further advance the state-of-the-art in this area.
Technical Explanation
The paper first defines the Incomplete Multi-Label Learning (InMLL) problem, which involves learning from datasets where some labels are missing for certain instances. This is in contrast to the traditional multi-label learning setting, where the complete set of labels is observed for all data points.
The authors then discuss various challenge formulations for InMLL, such as transductive and inductive settings, as well as the associated evaluation metrics. They review a wide range of state-of-the-art methods for addressing InMLL, including probabilistic models, transfer learning approaches, and multi-task learning techniques.
The paper provides a detailed analysis of these InMLL algorithms, highlighting their strengths, weaknesses, and the underlying principles. For example, some methods focus on recovering the missing labels through matrix completion or label propagation, while others leverage auxiliary information or transfer knowledge from related tasks to improve performance on the incomplete data.
Critical Analysis
The survey provides a comprehensive overview of the InMLL field, but it also acknowledges several limitations and areas for future research. For instance, the authors note that most existing methods assume the missing labels are missing at random, which may not always be the case in real-world scenarios. Developing techniques that can handle more complex missing label patterns is an important direction for future work.
Additionally, the paper suggests that incorporating large language models and lifelong learning capabilities into InMLL models could lead to significant performance improvements. However, the specific challenges and opportunities in integrating these advanced techniques are not discussed in depth.
Overall, the survey provides a solid foundation for understanding the InMLL problem and the state-of-the-art solutions, but there is still room for further research to address the limitations and expand the capabilities of InMLL models, especially in the context of emerging AI technologies.
Conclusion
This comprehensive survey paper on Incomplete Multi-Label Learning (InMLL) provides a valuable overview of the recent advances and future trends in this important machine learning field. By defining the problem, outlining the key challenges, and reviewing the state-of-the-art methods, the authors have created a useful resource for researchers and practitioners working on learning from datasets with missing label information.
The paper highlights the practical relevance of the InMLL problem, as incomplete or noisy label data is a common occurrence in real-world applications. The survey also points to promising future research directions, such as incorporating large language models and lifelong learning capabilities, which could lead to significant advancements in the field. Overall, this work provides a solid foundation for understanding and advancing the state-of-the-art in Incomplete Multi-Label Learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Deep Learning for Multi-Label Learning: A Comprehensive Survey
Adane Nega Tarekegn, Mohib Ullah, Faouzi Alaya Cheikh
0
0
Multi-label learning is a rapidly growing research area that aims to predict multiple labels from a single input data point. In the era of big data, tasks involving multi-label classification (MLC) or ranking present significant and intricate challenges, capturing considerable attention in diverse domains. Inherent difficulties in MLC include dealing with high-dimensional data, addressing label correlations, and handling partial labels, for which conventional methods prove ineffective. Recent years have witnessed a notable increase in adopting deep learning (DL) techniques to address these challenges more effectively in MLC. Notably, there is a burgeoning effort to harness the robust learning capabilities of DL for improved modelling of label dependencies and other challenges in MLC. However, it is noteworthy that comprehensive studies specifically dedicated to DL for multi-label learning are limited. Thus, this survey aims to thoroughly review recent progress in DL for multi-label learning, along with a summary of open research problems in MLC. The review consolidates existing research efforts in DL for MLC,including deep neural networks, transformers, autoencoders, and convolutional and recurrent architectures. Finally, the study presents a comparative analysis of the existing methods to provide insightful observations and stimulate future research directions in this domain.
6/27/2024

Combining Supervised Learning and Reinforcement Learning for Multi-Label Classification Tasks with Partial Labels
Zixia Jia, Junpeng Li, Shichuan Zhang, Anji Liu, Zilong Zheng
0
0
Traditional supervised learning heavily relies on human-annotated datasets, especially in data-hungry neural approaches. However, various tasks, especially multi-label tasks like document-level relation extraction, pose challenges in fully manual annotation due to the specific domain knowledge and large class sets. Therefore, we address the multi-label positive-unlabelled learning (MLPUL) problem, where only a subset of positive classes is annotated. We propose Mixture Learner for Partially Annotated Classification (MLPAC), an RL-based framework combining the exploration ability of reinforcement learning and the exploitation ability of supervised learning. Experimental results across various tasks, including document-level relation extraction, multi-label image classification, and binary PU learning, demonstrate the generalization and effectiveness of our framework.
6/26/2024
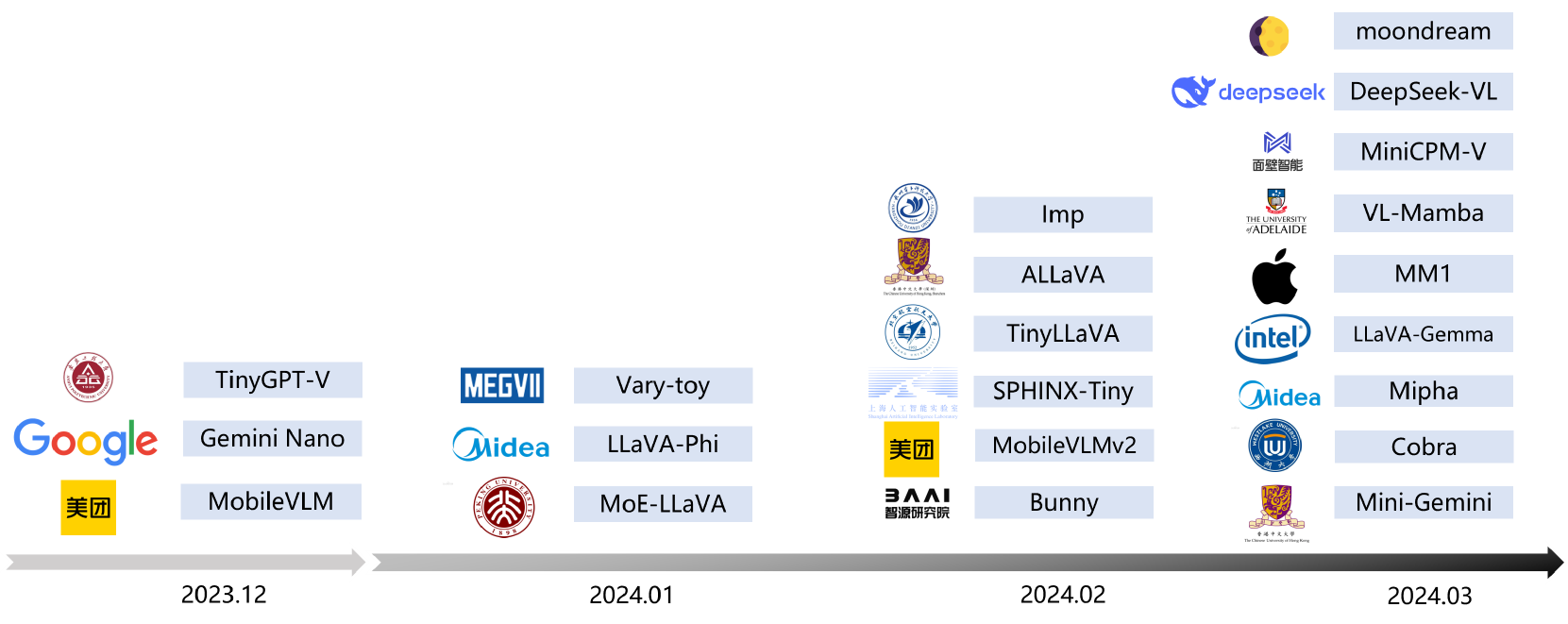
Efficient Multimodal Large Language Models: A Survey
Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, Yabiao Wang, Chengjie Wang, Lizhuang Ma
0
0
In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions. Please refer to our GitHub repository for more details: https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
5/20/2024
A Survey on Large Language Models with Multilingualism: Recent Advances and New Frontiers
Kaiyu Huang, Fengran Mo, Hongliang Li, You Li, Yuanchi Zhang, Weijian Yi, Yulong Mao, Jinchen Liu, Yuzhuang Xu, Jinan Xu, Jian-Yun Nie, Yang Liu
0
0
The rapid development of Large Language Models (LLMs) demonstrates remarkable multilingual capabilities in natural language processing, attracting global attention in both academia and industry. To mitigate potential discrimination and enhance the overall usability and accessibility for diverse language user groups, it is important for the development of language-fair technology. Despite the breakthroughs of LLMs, the investigation into the multilingual scenario remains insufficient, where a comprehensive survey to summarize recent approaches, developments, limitations, and potential solutions is desirable. To this end, we provide a survey with multiple perspectives on the utilization of LLMs in the multilingual scenario. We first rethink the transitions between previous and current research on pre-trained language models. Then we introduce several perspectives on the multilingualism of LLMs, including training and inference methods, model security, multi-domain with language culture, and usage of datasets. We also discuss the major challenges that arise in these aspects, along with possible solutions. Besides, we highlight future research directions that aim at further enhancing LLMs with multilingualism. The survey aims to help the research community address multilingual problems and provide a comprehensive understanding of the core concepts, key techniques, and latest developments in multilingual natural language processing based on LLMs.
5/20/2024