A Survey of Privacy-Preserving Model Explanations: Privacy Risks, Attacks, and Countermeasures

0
Sign in to get full access
Overview
- This paper provides a comprehensive survey of privacy-preserving model explanations, including the privacy risks, attacks, and countermeasures.
- It discusses the growing importance of explainable AI (XAI) and the potential privacy concerns that can arise when model explanations are generated and shared.
- The paper covers a range of attacks that can be used to exploit model explanations to infer sensitive information about the underlying data or model.
- It also reviews various countermeasures and techniques that have been proposed to enhance the privacy of model explanations.
Plain English Explanation
Model explanations are descriptions that help us understand how machine learning models make their decisions. As machine learning models become more advanced and widespread, there is a growing need to make these models more transparent and explainable. This is where explainable AI (XAI) comes in - it focuses on developing techniques to explain how models work.
However, providing model explanations can also create privacy risks. Attackers could potentially use these explanations to infer sensitive information about the data or model that was used to train the model. For example, they might be able to figure out details about the people or organizations whose data was used.
This paper looks at the different types of privacy risks and attacks that can target model explanations. It also reviews various approaches that have been developed to protect the privacy of model explanations, such as techniques to obfuscate or perturb the explanations in a way that preserves their utility while reducing the risk of privacy breaches.
Understanding these privacy-preserving techniques for model explanations is important as AI systems become more prevalent in our lives. We want to be able to enjoy the benefits of explainable AI without compromising individual privacy.
Technical Explanation
The paper begins by discussing the growing importance of explainable AI (XAI) and the potential privacy risks that can arise from generating and sharing model explanations. It notes that as machine learning models become more complex and widely deployed, there is an increasing need to make them more transparent and interpretable.
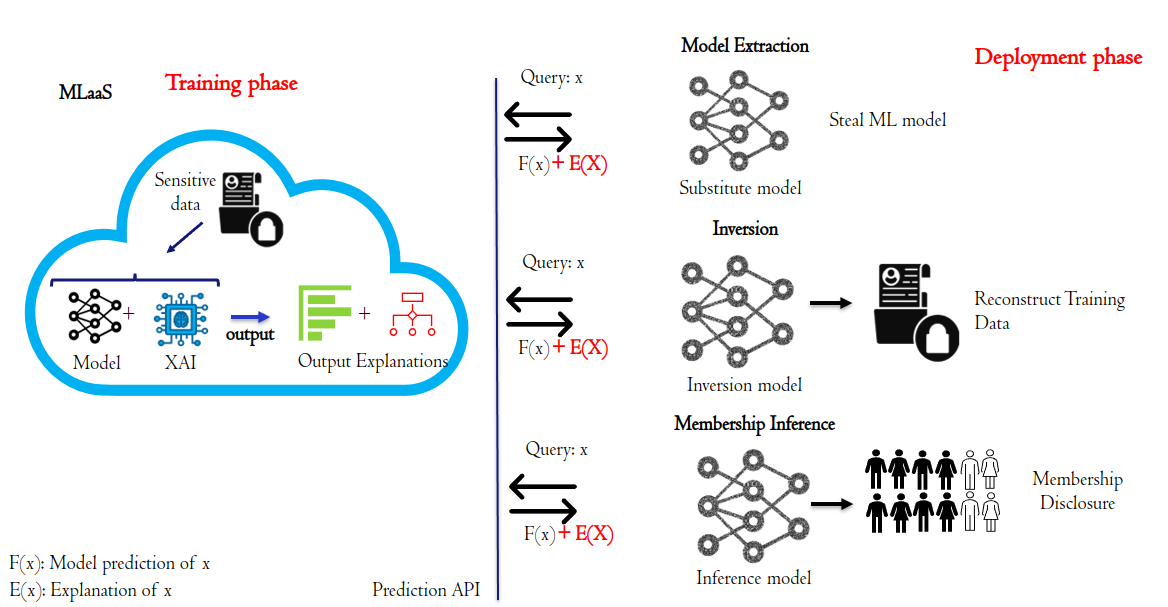
The authors then provide an overview of different types of model explanations, including feature importance, counterfactual explanations, and example-based explanations. They explain how these explanations can potentially be exploited by attackers to infer sensitive information about the training data or model parameters, leading to various privacy attacks.
The paper reviews several key privacy attacks that have been proposed in the literature, such as model extraction attacks and membership inference attacks. The authors discuss how these attacks work and the types of information they can potentially uncover from model explanations.
In response to these privacy risks, the paper examines different countermeasures and privacy-preserving techniques that have been developed. This includes approaches like differentially private explanations, watermarking explanations, and other methods to obfuscate or perturb the explanations in a way that preserves their utility while reducing the risk of privacy breaches.
Critical Analysis
The paper provides a thorough and well-researched overview of the privacy implications of model explanations. It does a good job of highlighting the core privacy risks and the types of attacks that can target these explanations.
One potential limitation is that the paper focuses primarily on technical attacks and countermeasures, without delving too deeply into the broader societal and ethical implications of privacy-preserving XAI. As AI systems become more prevalent, there will likely be important questions around balancing transparency, interpretability, and individual privacy that merit further discussion.
Additionally, while the paper reviews a range of proposed countermeasures, it does not provide a comprehensive evaluation of their relative strengths, weaknesses, and practical feasibility. More research may be needed to understand the tradeoffs and identify the most effective privacy-preserving techniques for real-world deployment of XAI systems.
Overall, this paper serves as a valuable reference for researchers and practitioners working in the field of explainable AI. By shedding light on the privacy risks and potential mitigation strategies, it can help inform the development of more responsible and trustworthy AI systems.
Conclusion
This survey paper provides a comprehensive overview of the privacy implications of model explanations in the context of explainable AI. It highlights the growing importance of XAI and the potential privacy risks that can arise when model explanations are generated and shared.
The paper reviews a range of privacy attacks that can target model explanations, as well as various countermeasures and privacy-preserving techniques that have been proposed to enhance the privacy of these explanations. By understanding these issues, researchers and practitioners can work towards developing XAI systems that are both transparent and respectful of individual privacy.
As AI continues to play a larger role in our lives, finding the right balance between explainability and privacy will be crucial. This paper lays the groundwork for further research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey of Privacy-Preserving Model Explanations: Privacy Risks, Attacks, and Countermeasures
Thanh Tam Nguyen, Thanh Trung Huynh, Zhao Ren, Thanh Toan Nguyen, Phi Le Nguyen, Hongzhi Yin, Quoc Viet Hung Nguyen
As the adoption of explainable AI (XAI) continues to expand, the urgency to address its privacy implications intensifies. Despite a growing corpus of research in AI privacy and explainability, there is little attention on privacy-preserving model explanations. This article presents the first thorough survey about privacy attacks on model explanations and their countermeasures. Our contribution to this field comprises a thorough analysis of research papers with a connected taxonomy that facilitates the categorisation of privacy attacks and countermeasures based on the targeted explanations. This work also includes an initial investigation into the causes of privacy leaks. Finally, we discuss unresolved issues and prospective research directions uncovered in our analysis. This survey aims to be a valuable resource for the research community and offers clear insights for those new to this domain. To support ongoing research, we have established an online resource repository, which will be continuously updated with new and relevant findings. Interested readers are encouraged to access our repository at https://github.com/tamlhp/awesome-privex.
Read more6/27/2024
0
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
Read more6/26/2024

0
Knowledge Distillation-Based Model Extraction Attack using Private Counterfactual Explanations
Fatima Ezzeddine, Omran Ayoub, Silvia Giordano
In recent years, there has been a notable increase in the deployment of machine learning (ML) models as services (MLaaS) across diverse production software applications. In parallel, explainable AI (XAI) continues to evolve, addressing the necessity for transparency and trustworthiness in ML models. XAI techniques aim to enhance the transparency of ML models by providing insights, in terms of the model's explanations, into their decision-making process. Simultaneously, some MLaaS platforms now offer explanations alongside the ML prediction outputs. This setup has elevated concerns regarding vulnerabilities in MLaaS, particularly in relation to privacy leakage attacks such as model extraction attacks (MEA). This is due to the fact that explanations can unveil insights about the inner workings of the model which could be exploited by malicious users. In this work, we focus on investigating how model explanations, particularly Generative adversarial networks (GANs)-based counterfactual explanations (CFs), can be exploited for performing MEA within the MLaaS platform. We also delve into assessing the effectiveness of incorporating differential privacy (DP) as a mitigation strategy. To this end, we first propose a novel MEA methodology based on Knowledge Distillation (KD) to enhance the efficiency of extracting a substitute model of a target model exploiting CFs. Then, we advise an approach for training CF generators incorporating DP to generate private CFs. We conduct thorough experimental evaluations on real-world datasets and demonstrate that our proposed KD-based MEA can yield a high-fidelity substitute model with reduced queries with respect to baseline approaches. Furthermore, our findings reveal that the inclusion of a privacy layer impacts the performance of the explainer, the quality of CFs, and results in a reduction in the MEA performance.
Read more4/5/2024

0
Explaining the Model, Protecting Your Data: Revealing and Mitigating the Data Privacy Risks of Post-Hoc Model Explanations via Membership Inference
Catherine Huang, Martin Pawelczyk, Himabindu Lakkaraju
Predictive machine learning models are becoming increasingly deployed in high-stakes contexts involving sensitive personal data; in these contexts, there is a trade-off between model explainability and data privacy. In this work, we push the boundaries of this trade-off: with a focus on foundation models for image classification fine-tuning, we reveal unforeseen privacy risks of post-hoc model explanations and subsequently offer mitigation strategies for such risks. First, we construct VAR-LRT and L1/L2-LRT, two new membership inference attacks based on feature attribution explanations that are significantly more successful than existing explanation-leveraging attacks, particularly in the low false-positive rate regime that allows an adversary to identify specific training set members with confidence. Second, we find empirically that optimized differentially private fine-tuning substantially diminishes the success of the aforementioned attacks, while maintaining high model accuracy. We carry out a systematic empirical investigation of our 2 new attacks with 5 vision transformer architectures, 5 benchmark datasets, 4 state-of-the-art post-hoc explanation methods, and 4 privacy strength settings.
Read more7/29/2024