SVGEditBench: A Benchmark Dataset for Quantitative Assessment of LLM's SVG Editing Capabilities

0

Sign in to get full access
Overview
• This paper introduces SVGEditBench, a new benchmark dataset for evaluating the ability of large language models (LLMs) to edit Scalable Vector Graphics (SVG) content.
• SVG is a widely-used format for creating and manipulating vector graphics on the web, and the ability to edit SVG programmatically is an important skill for various applications, such as data visualization, web design, and multimodal AI.
• The paper presents the dataset, its creation process, and a set of baseline experiments to assess the performance of LLMs on SVG editing tasks.
Plain English Explanation
The paper introduces a new dataset called SVGEditBench, which is designed to test the ability of large language models (LLMs) to edit Scalable Vector Graphics (SVG) files. SVG is a common format used on the web to create and manipulate vector-based images, and the ability to edit SVG files programmatically is important for a variety of applications, such as data visualization, web design, and multimodal AI systems that work with both text and images.
The dataset is created by collecting a large number of SVG files from various sources and then annotating them with different types of editing tasks, such as modifying the size, color, or position of specific elements within the SVG. The researchers then use this dataset to evaluate the performance of different LLMs on these SVG editing tasks, providing a way to quantify and compare their capabilities in this area.
The key significance of this work is that it fills an important gap in the evaluation of LLMs, which have primarily been assessed on text-based tasks, but not on their ability to interact with and manipulate visual content like SVG files. By creating a benchmark dataset and establishing baseline performance, the researchers hope to spur further research and development in this area, ultimately leading to more capable and versatile AI systems that can seamlessly integrate text and visual processing.
Technical Explanation
The paper presents SVGEditBench, a new benchmark dataset for evaluating the ability of large language models (LLMs) to edit Scalable Vector Graphics (SVG) content. SVG is a widely-used vector graphics format on the web, and the ability to edit SVG programmatically is an important skill for various applications, such as data visualization, web design, and multimodal AI.
The dataset is constructed by collecting a large number of SVG files from various online sources, such as Wikipedia, Wikimedia Commons, and GitHub repositories. These SVG files are then annotated with different types of editing tasks, including modifying the size, color, or position of specific elements within the SVG. The dataset covers a wide range of complexity, from simple edits to more involved transformations.
The researchers conduct a set of baseline experiments using the SVGEditBench dataset to evaluate the performance of several state-of-the-art LLMs, including GPT-3, DALL-E 2, and Imagen, on SVG editing tasks. The models are given natural language instructions and the original SVG file, and their outputs are compared to the target edited SVG files using various metrics, such as pixel-level accuracy, vector graphic similarity, and task-specific evaluation criteria.
The results of these experiments demonstrate that existing LLMs can perform SVG editing to some extent, but their capabilities are still limited compared to human-level performance. The paper identifies several challenges and opportunities for future research, including the need for better multimodal reasoning, stronger understanding of vector graphics, and the development of specialized architectures and training approaches for SVG editing.
Critical Analysis
The SVGEditBench dataset and the associated experiments represent an important step forward in the evaluation of LLMs' capabilities beyond text-based tasks. By focusing on the ability to edit SVG content, the researchers are addressing a relevant and practical skill that is essential for a wide range of real-world applications.
One potential limitation of the current work is the reliance on a relatively small set of baseline LLMs, which may not fully capture the rapid advancements in this field. As new and more capable LLMs are developed, it would be valuable to expand the evaluation to a broader range of models, potentially including specialized architectures or fine-tuning approaches tailored for SVG editing, as suggested by the authors.
Additionally, the paper could benefit from a deeper analysis of the types of editing tasks that pose the greatest challenges for LLMs, as well as the factors that contribute to their performance, such as the complexity of the SVG content, the specificity of the editing instructions, or the availability of relevant training data. Exploring these aspects could help guide future research and development in this area.
It would also be interesting to see how the SVGEditBench dataset and evaluation framework could be extended to other types of visual content, such as raster images or 3D models, to provide a more comprehensive understanding of LLMs' multimodal capabilities.
Conclusion
The SVGEditBench dataset and the associated research presented in this paper represent an important contribution to the field of large language model evaluation, expanding the focus beyond text-based tasks to include the editing of Scalable Vector Graphics (SVG) content. This work highlights the growing importance of multimodal AI systems that can seamlessly integrate text and visual processing, and it provides a valuable benchmark for assessing the capabilities of LLMs in this domain.
The baseline experiments conducted by the researchers demonstrate both the potential and the current limitations of existing LLMs in SVG editing tasks, identifying areas for future research and development. By creating a standardized dataset and evaluation framework, the authors have laid the groundwork for continued progress in this field, ultimately leading to more capable and versatile AI systems that can better interact with and manipulate visual content on the web and in various applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SVGEditBench: A Benchmark Dataset for Quantitative Assessment of LLM's SVG Editing Capabilities
Kunato Nishina, Yusuke Matsui
Text-to-image models have shown progress in recent years. Along with this progress, generating vector graphics from text has also advanced. SVG is a popular format for vector graphics, and SVG represents a scene with XML text. Therefore, Large Language Models can directly process SVG code. Taking this into account, we focused on editing SVG with LLMs. For quantitative evaluation of LLMs' ability to edit SVG, we propose SVGEditBench. SVGEditBench is a benchmark for assessing the LLMs' ability to edit SVG code. We also show the GPT-4 and GPT-3.5 results when evaluated on the proposed benchmark. In the experiments, GPT-4 showed superior performance to GPT-3.5 both quantitatively and qualitatively. The dataset is available at https://github.com/mti-lab/SVGEditBench.
Read more4/23/2024

0
VGBench: Evaluating Large Language Models on Vector Graphics Understanding and Generation
Bocheng Zou, Mu Cai, Jianrui Zhang, Yong Jae Lee
In the realm of vision models, the primary mode of representation is using pixels to rasterize the visual world. Yet this is not always the best or unique way to represent visual content, especially for designers and artists who depict the world using geometry primitives such as polygons. Vector graphics (VG), on the other hand, offer a textual representation of visual content, which can be more concise and powerful for content like cartoons, sketches and scientific figures. Recent studies have shown promising results on processing vector graphics with capable Large Language Models (LLMs). However, such works focus solely on qualitative results, understanding, or a specific type of vector graphics. We propose VGBench, a comprehensive benchmark for LLMs on handling vector graphics through diverse aspects, including (a) both visual understanding and generation, (b) evaluation of various vector graphics formats, (c) diverse question types, (d) wide range of prompting techniques, (e) under multiple LLMs and (f) comparison with VLMs on rasterized representations. Evaluating on our collected 4279 understanding and 5845 generation samples, we find that LLMs show strong capability on both aspects while exhibiting less desirable performance on low-level formats (SVG). Both data and evaluation pipeline will be open-sourced at https://vgbench.github.io.
Read more8/30/2024

0
Exploring the Capability of LLMs in Performing Low-Level Visual Analytic Tasks on SVG Data Visualizations
Zhongzheng Xu, Emily Wall
Data visualizations help extract insights from datasets, but reaching these insights requires decomposing high level goals into low-level analytic tasks that can be complex due to varying degrees of data literacy and visualization experience. Recent advancements in large language models (LLMs) have shown promise for lowering barriers for users to achieve tasks such as writing code and may likewise facilitate visualization insight. Scalable Vector Graphics (SVG), a text-based image format common in data visualizations, matches well with the text sequence processing of transformer-based LLMs. In this paper, we explore the capability of LLMs to perform 10 low-level visual analytic tasks defined by Amar, Eagan, and Stasko directly on SVG-based visualizations. Using zero-shot prompts, we instruct the models to provide responses or modify the SVG code based on given visualizations. Our findings demonstrate that LLMs can effectively modify existing SVG visualizations for some tasks like Cluster but perform poorly on tasks requiring mathematical operations like Compute Derived Value. We also discovered that LLM performance can vary based on factors such as the number of data points, the presence of value labels, and the chart type. Our findings contribute to gauging the general capabilities of LLMs and highlight the need for further exploration and development to fully harness their potential in supporting visual analytic tasks.
Read more5/2/2024
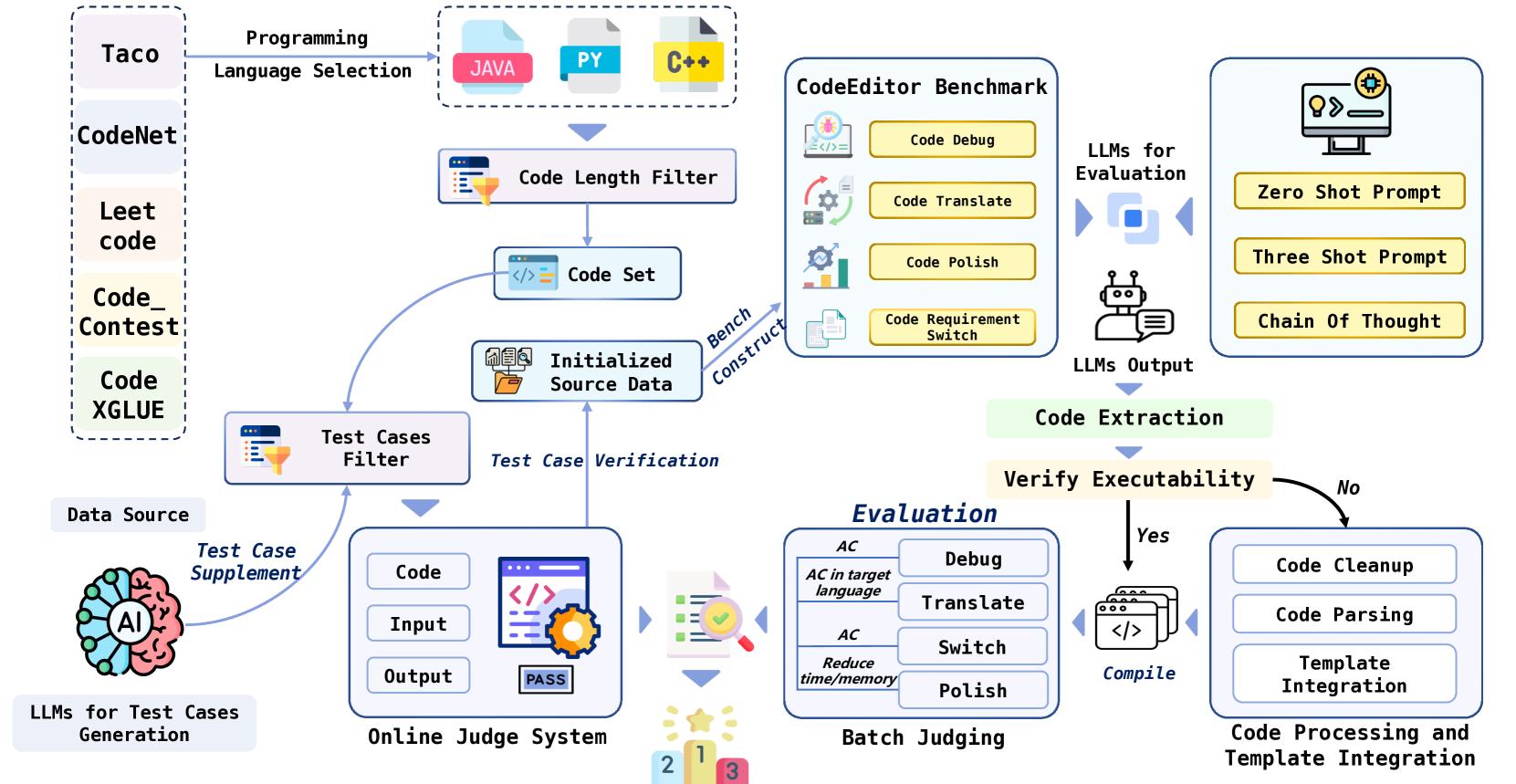
0
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Read more4/9/2024