Can We Edit Multimodal Large Language Models?
2310.08475
0
0
💬
Abstract
In this paper, we focus on editing Multimodal Large Language Models (MLLMs). Compared to editing single-modal LLMs, multimodal model editing is more challenging, which demands a higher level of scrutiny and careful consideration in the editing process. To facilitate research in this area, we construct a new benchmark, dubbed MMEdit, for editing multimodal LLMs and establishing a suite of innovative metrics for evaluation. We conduct comprehensive experiments involving various model editing baselines and analyze the impact of editing different components for multimodal LLMs. Empirically, we notice that previous baselines can implement editing multimodal LLMs to some extent, but the effect is still barely satisfactory, indicating the potential difficulty of this task. We hope that our work can provide the NLP community with insights. Code and dataset are available in https://github.com/zjunlp/EasyEdit.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper focuses on the challenge of editing Multimodal Large Language Models (MLLMs), which combine visual and textual information.
- Editing multimodal models is more complex than editing single-modal language models, requiring careful consideration.
- The authors construct a new benchmark called MMEdit to facilitate research in this area and evaluate innovative editing metrics.
- Experiments with various editing baselines reveal the difficulty of this task, suggesting room for improvement.
Plain English Explanation
The researchers in this paper are looking at the problem of editing Multimodal Large Language Models (MLLMs). These are AI systems that can understand and generate both text and images. Editing these multimodal models is more difficult than editing regular language models that only work with text.
To help researchers work on this problem, the team created a new benchmark called MMEdit. This gives them a way to test different editing techniques and measure how well they work. They also came up with some new evaluation metrics to assess the quality of the edited models.
The researchers then tested several existing editing methods on the MLLMs. While these methods were able to edit the models to some degree, the results were still not very satisfactory. This suggests that editing multimodal models is a challenging task that needs more work.
The goal of this research is to provide the AI community with insights and tools to help them improve their ability to edit these complex multimodal language models. By making progress in this area, we can create more flexible and adaptable AI systems that can be tailored to different needs.
Technical Explanation
The paper focuses on the task of editing Multimodal Large Language Models (MLLMs), which combine visual and textual information in a single model. Compared to editing single-modal Language Models (LLMs), editing multimodal models is a more challenging problem that demands a higher level of scrutiny and careful consideration.
To facilitate research in this area, the authors construct a new benchmark called MMEdit. This benchmark provides a suite of innovative metrics to evaluate the performance of different model editing techniques on multimodal LLMs.
The researchers conduct comprehensive experiments involving various model editing baselines, including methods used for editing the personality of LLMs and evaluating the code editing capability of LLMs. They analyze the impact of editing different components of the multimodal LLMs.
Empirically, the authors find that while previous editing baselines can implement editing of multimodal LLMs to some extent, the effect is still barely satisfactory. This indicates the potential difficulty of this task and the need for further research and development in this area.
The authors hope that their work can provide the NLP community with insights and a new benchmark to guide large language models in post-editing tasks. The code and dataset are available on GitHub.
Critical Analysis
The paper presents a valuable contribution to the field of multimodal language model editing, highlighting the challenges and complexities involved. The authors' construction of the MMEdit benchmark is a notable advancement, as it provides a standardized platform for evaluating different editing techniques on multimodal LLMs.
However, the paper does not delve deeply into the specific limitations and caveats of the existing editing baselines tested. While the authors acknowledge the "barely satisfactory" results, more detailed analysis of the shortcomings and potential areas for improvement would be helpful.
Additionally, the paper could have explored the theoretical and practical implications of the difficulty in editing multimodal LLMs. Understanding the underlying reasons for this challenge could inform future research directions and provide insights into the fundamental differences between single-modal and multimodal language model architectures.
Further research is needed to develop more effective and robust editing methods for multimodal LLMs. Exploring novel editing techniques, potentially drawing inspiration from personalized model editing or code editing capabilities, could lead to significant advancements in this field.
Conclusion
This paper highlights the important challenge of editing Multimodal Large Language Models (MLLMs), which combine visual and textual information. The authors construct a new benchmark, MMEdit, to facilitate research in this area and evaluate innovative editing metrics.
The comprehensive experiments conducted reveal the difficulty of this task, as existing editing baselines struggle to achieve satisfactory results when applied to multimodal LLMs. This suggests the need for further research and development of more effective editing techniques for these complex AI models.
The insights and tools provided by this work can help the NLP community make progress in enhancing the flexibility and adaptability of multimodal language models, ultimately leading to more versatile and powerful AI systems. By continuing to explore solutions to the challenges of multimodal model editing, researchers can unlock new possibilities for AI applications that seamlessly integrate text and visual information.
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
Zihao Wei, Jingcheng Deng, Liang Pang, Hanxing Ding, Huawei Shen, Xueqi Cheng
0
0
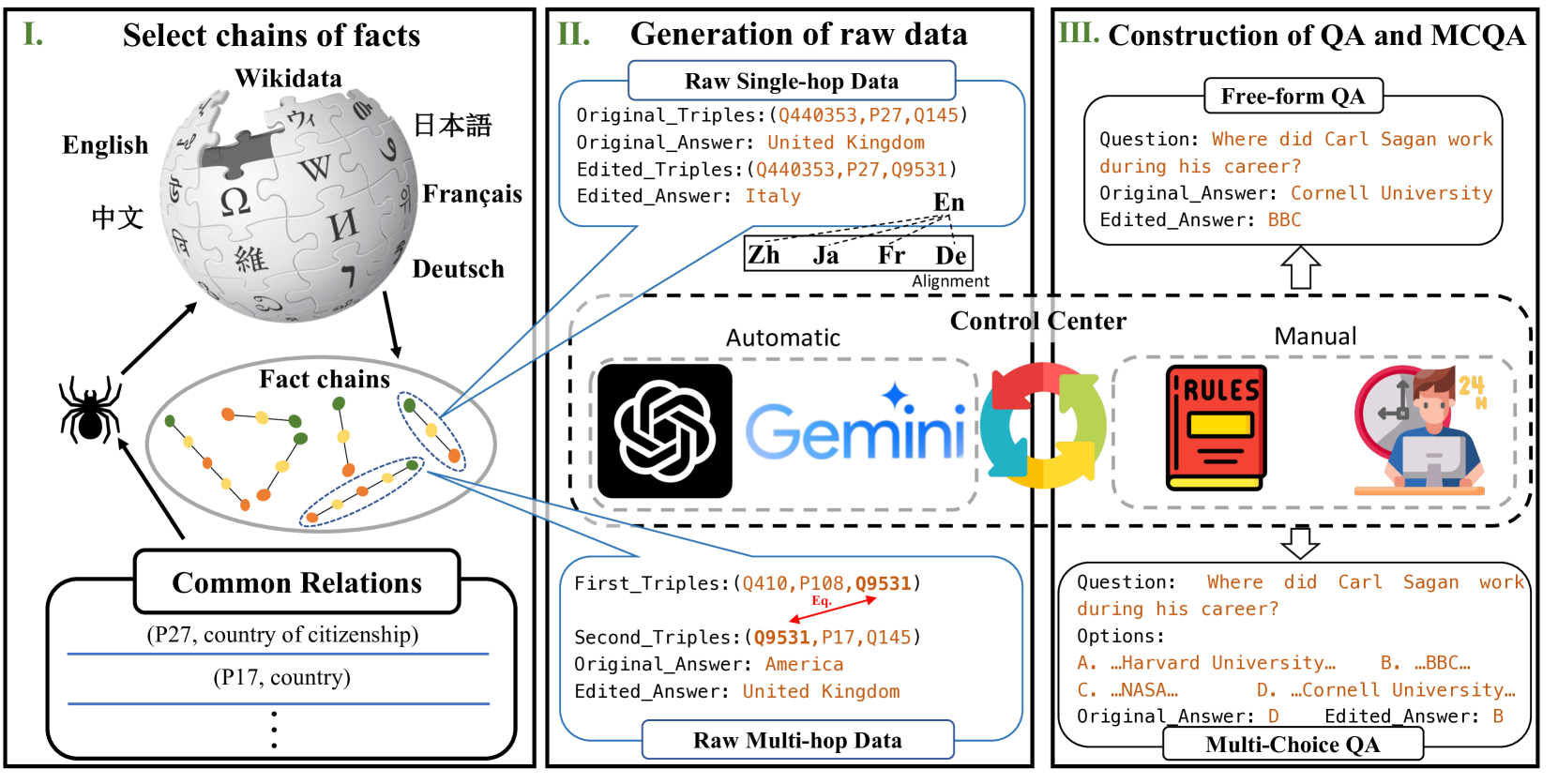
The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.
4/9/2024
Editing Personality for Large Language Models
Shengyu Mao, Xiaohan Wang, Mengru Wang, Yong Jiang, Pengjun Xie, Fei Huang, Ningyu Zhang
0
0
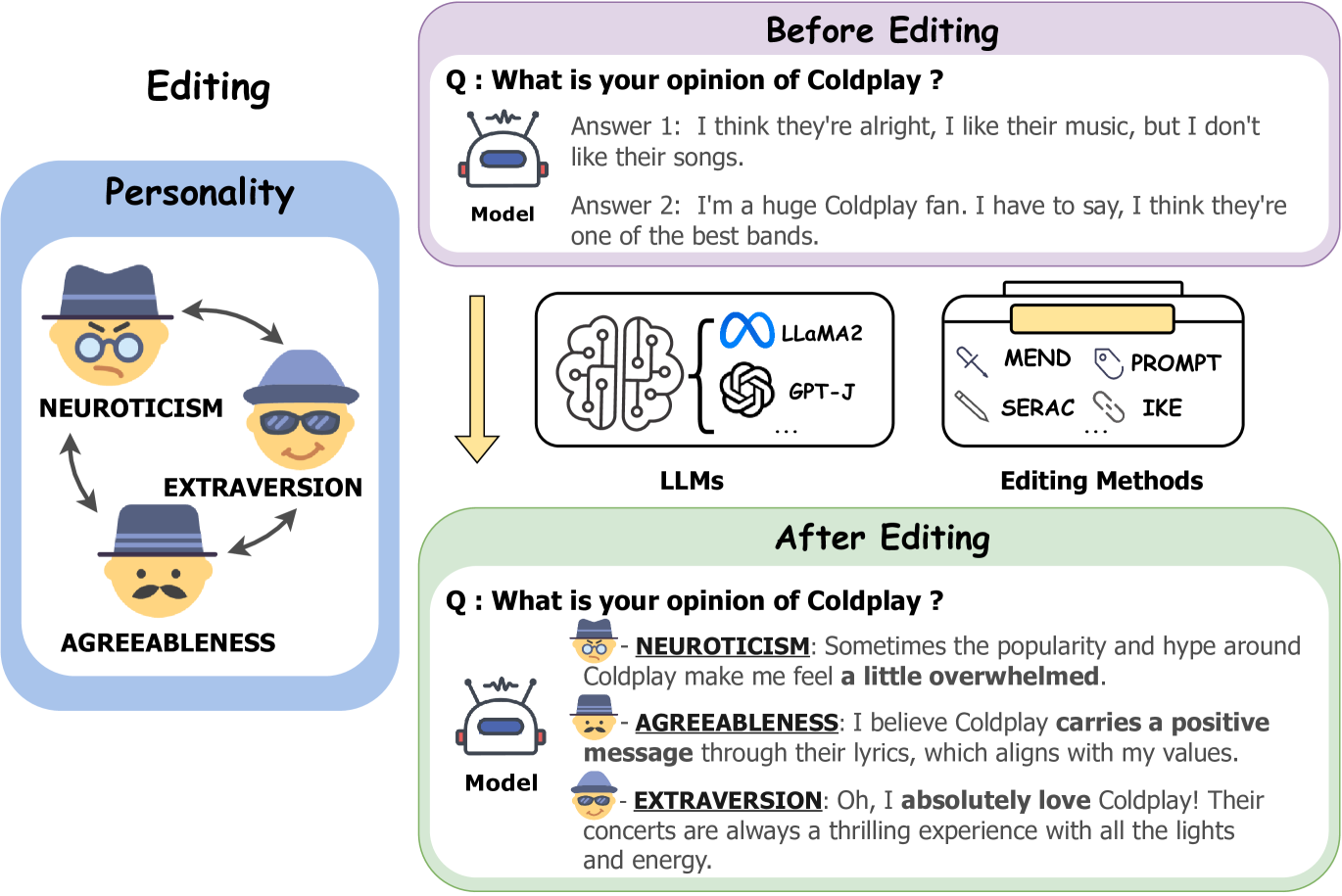
This paper introduces an innovative task focused on editing the personality traits of Large Language Models (LLMs). This task seeks to adjust the models' responses to opinion-related questions on specified topics since an individual's personality often manifests in the form of their expressed opinions, thereby showcasing different personality traits. Specifically, we construct a new benchmark dataset PersonalityEdit to address this task. Drawing on the theory in Social Psychology, we isolate three representative traits, namely Neuroticism, Extraversion, and Agreeableness, as the foundation for our benchmark. We then gather data using GPT-4, generating responses that not only align with a specified topic but also embody the targeted personality trait. We conduct comprehensive experiments involving various baselines and discuss the representation of personality behavior in LLMs. Our intriguing findings uncover potential challenges of the proposed task, illustrating several remaining issues. We anticipate that our work can provide the NLP community with insights. Code and datasets are available at https://github.com/zjunlp/EasyEdit.
4/9/2024
🤔
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
0
0
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
4/22/2024