SWAG: Splatting in the Wild images with Appearance-conditioned Gaussians
2403.10427
0
0

Abstract
Implicit neural representation methods have shown impressive advancements in learning 3D scenes from unstructured in-the-wild photo collections but are still limited by the large computational cost of volumetric rendering. More recently, 3D Gaussian Splatting emerged as a much faster alternative with superior rendering quality and training efficiency, especially for small-scale and object-centric scenarios. Nevertheless, this technique suffers from poor performance on unstructured in-the-wild data. To tackle this, we extend over 3D Gaussian Splatting to handle unstructured image collections. We achieve this by modeling appearance to seize photometric variations in the rendered images. Additionally, we introduce a new mechanism to train transient Gaussians to handle the presence of scene occluders in an unsupervised manner. Experiments on diverse photo collection scenes and multi-pass acquisition of outdoor landmarks show the effectiveness of our method over prior works achieving state-of-the-art results with improved efficiency.
Create account to get full access
Overview
- Presents a novel technique called SWAG (Splatting in the Wild images with Appearance-conditioned Gaussians) for generating 3D representations from unconstrained photo collections
- Leverages a deep learning architecture to model object appearance and geometry using Gaussian splatting
- Enables real-time rendering, transient object removal, and novel view synthesis from these 3D representations
Plain English Explanation
The paper introduces a new method called SWAG that can create 3D models from regular photos. Rather than relying on specialized 3D scanning or constrained photo capture setups, SWAG can work with ordinary, unconstrained photo collections.
At the core of SWAG is the use of Gaussian "splatting" - representing objects as a collection of overlapping 3D Gaussian distributions. This allows the method to effectively model both the appearance and geometry of objects. The paper describes a deep learning architecture that can learn how to generate these Gaussian-based 3D representations directly from 2D photos.
The key benefits of SWAG are that it enables real-time rendering of the 3D models, allows for the removal of transient objects (like people walking through a scene), and supports the synthesis of novel views not present in the original photo collection. This makes it a versatile tool for applications like 3D reconstruction, augmented reality, and computational photography.
Technical Explanation
The SWAG technique builds on prior work in Gaussian splatting and Gaussian feature representations to create a deep learning-based pipeline for reconstructing 3D object representations from unconstrained photo collections.
At the heart of SWAG is the use of appearance-conditioned Gaussians to model both the geometry and appearance of objects. Rather than representing objects with rigid 3D meshes, SWAG uses a collection of 3D Gaussian distributions, where each Gaussian has associated appearance information like color and texture. This Gaussian splatting approach allows for efficient rendering and supports novel view synthesis.
The paper presents a deep neural network architecture that can take a set of input photos and directly regress the parameters of these appearance-conditioned Gaussians. This includes the 3D position, size, and orientation of each Gaussian, as well as its associated appearance properties. By learning this mapping from 2D photos to 3D Gaussian representations, SWAG can reconstruct 3D object models without requiring specialized 3D data or sensor inputs.
Critical Analysis
The SWAG paper makes a compelling contribution by demonstrating how Gaussian splatting can be effectively leveraged for 3D reconstruction from unconstrained photo collections. The ability to model both geometry and appearance in a unified representation is a key strength, enabling applications like real-time rendering, transient object removal, and novel view synthesis.
However, the paper also notes some limitations of the current SWAG approach. For example, the method may struggle with highly complex or occluded scenes, and the quality of the reconstructed 3D models is still not on par with specialized 3D scanning techniques. Additionally, the training process requires a significant amount of annotated 3D data, which may limit the scalability of the approach.
Further research could explore ways to improve the robustness and generalization of the SWAG model, potentially by incorporating additional priors or weakly-supervised learning techniques. Investigating the integration of SWAG with other 3D reconstruction methods, such as the GAVATAR approach for animatable 3D avatars, could also be a fruitful avenue for future work.
Conclusion
The SWAG technique presented in this paper represents a significant step forward in the field of 3D reconstruction from unconstrained photo collections. By leveraging appearance-conditioned Gaussians and a deep learning-based architecture, SWAG can generate 3D object representations that enable a range of useful applications, from real-time rendering to transient object removal and novel view synthesis.
While the current approach has some limitations, the underlying ideas and techniques hold great promise for advancing the state of the art in computational photography, augmented reality, and other domains that require robust and versatile 3D modeling capabilities. As the field continues to evolve, further research building on the foundations laid by SWAG could lead to even more powerful and accessible 3D reconstruction solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Deblurring 3D Gaussian Splatting
Byeonghyeon Lee, Howoong Lee, Xiangyu Sun, Usman Ali, Eunbyung Park
0
0
Recent studies in Radiance Fields have paved the robust way for novel view synthesis with their photorealistic rendering quality. Nevertheless, they usually employ neural networks and volumetric rendering, which are costly to train and impede their broad use in various real-time applications due to the lengthy rendering time. Lately 3D Gaussians splatting-based approach has been proposed to model the 3D scene, and it achieves remarkable visual quality while rendering the images in real-time. However, it suffers from severe degradation in the rendering quality if the training images are blurry. Blurriness commonly occurs due to the lens defocusing, object motion, and camera shake, and it inevitably intervenes in clean image acquisition. Several previous studies have attempted to render clean and sharp images from blurry input images using neural fields. The majority of those works, however, are designed only for volumetric rendering-based neural radiance fields and are not straightforwardly applicable to rasterization-based 3D Gaussian splatting methods. Thus, we propose a novel real-time deblurring framework, Deblurring 3D Gaussian Splatting, using a small Multi-Layer Perceptron (MLP) that manipulates the covariance of each 3D Gaussian to model the scene blurriness. While Deblurring 3D Gaussian Splatting can still enjoy real-time rendering, it can reconstruct fine and sharp details from blurry images. A variety of experiments have been conducted on the benchmark, and the results have revealed the effectiveness of our approach for deblurring. Qualitative results are available at https://benhenryl.github.io/Deblurring-3D-Gaussian-Splatting/
5/28/2024
Recent Advances in 3D Gaussian Splatting
Tong Wu, Yu-Jie Yuan, Ling-Xiao Zhang, Jie Yang, Yan-Pei Cao, Ling-Qi Yan, Lin Gao
0
0
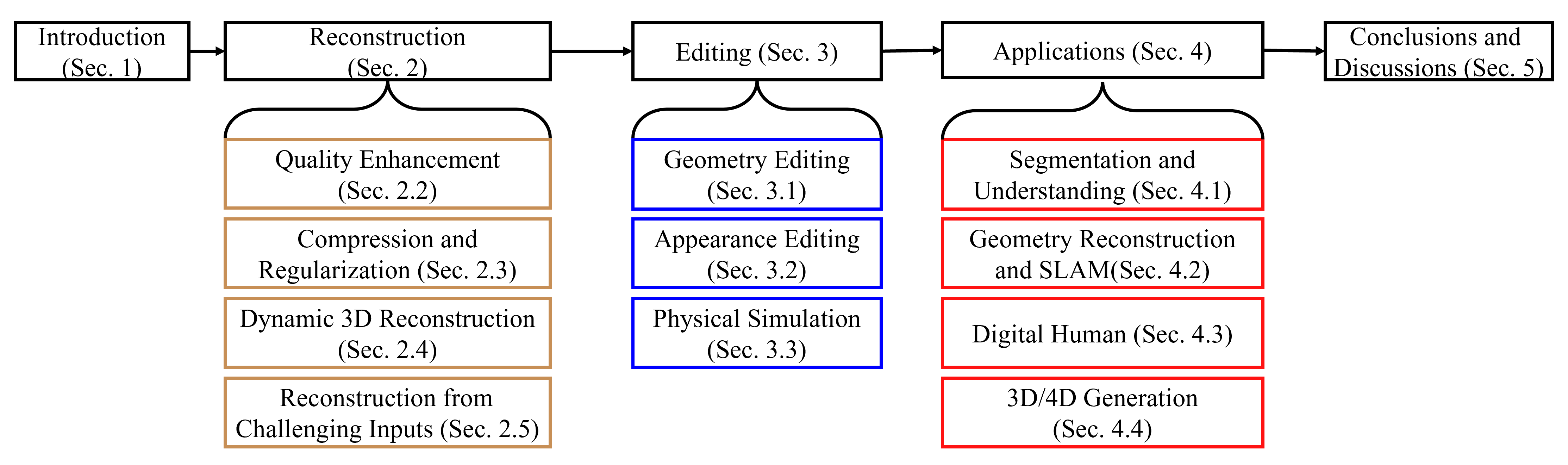
The emergence of 3D Gaussian Splatting (3DGS) has greatly accelerated the rendering speed of novel view synthesis. Unlike neural implicit representations like Neural Radiance Fields (NeRF) that represent a 3D scene with position and viewpoint-conditioned neural networks, 3D Gaussian Splatting utilizes a set of Gaussian ellipsoids to model the scene so that efficient rendering can be accomplished by rasterizing Gaussian ellipsoids into images. Apart from the fast rendering speed, the explicit representation of 3D Gaussian Splatting facilitates editing tasks like dynamic reconstruction, geometry editing, and physical simulation. Considering the rapid change and growing number of works in this field, we present a literature review of recent 3D Gaussian Splatting methods, which can be roughly classified into 3D reconstruction, 3D editing, and other downstream applications by functionality. Traditional point-based rendering methods and the rendering formulation of 3D Gaussian Splatting are also illustrated for a better understanding of this technique. This survey aims to help beginners get into this field quickly and provide experienced researchers with a comprehensive overview, which can stimulate the future development of the 3D Gaussian Splatting representation.
4/16/2024
WE-GS: An In-the-wild Efficient 3D Gaussian Representation for Unconstrained Photo Collections
Yuze Wang, Junyi Wang, Yue Qi
0
0
Novel View Synthesis (NVS) from unconstrained photo collections is challenging in computer graphics. Recently, 3D Gaussian Splatting (3DGS) has shown promise for photorealistic and real-time NVS of static scenes. Building on 3DGS, we propose an efficient point-based differentiable rendering framework for scene reconstruction from photo collections. Our key innovation is a residual-based spherical harmonic coefficients transfer module that adapts 3DGS to varying lighting conditions and photometric post-processing. This lightweight module can be pre-computed and ensures efficient gradient propagation from rendered images to 3D Gaussian attributes. Additionally, we observe that the appearance encoder and the transient mask predictor, the two most critical parts of NVS from unconstrained photo collections, can be mutually beneficial. We introduce a plug-and-play lightweight spatial attention module to simultaneously predict transient occluders and latent appearance representation for each image. After training and preprocessing, our method aligns with the standard 3DGS format and rendering pipeline, facilitating seamlessly integration into various 3DGS applications. Extensive experiments on diverse datasets show our approach outperforms existing approaches on the rendering quality of novel view and appearance synthesis with high converge and rendering speed.
6/5/2024

Compact 3D Scene Representation via Self-Organizing Gaussian Grids
Wieland Morgenstern, Florian Barthel, Anna Hilsmann, Peter Eisert
0
0
3D Gaussian Splatting has recently emerged as a highly promising technique for modeling of static 3D scenes. In contrast to Neural Radiance Fields, it utilizes efficient rasterization allowing for very fast rendering at high-quality. However, the storage size is significantly higher, which hinders practical deployment, e.g. on resource constrained devices. In this paper, we introduce a compact scene representation organizing the parameters of 3D Gaussian Splatting (3DGS) into a 2D grid with local homogeneity, ensuring a drastic reduction in storage requirements without compromising visual quality during rendering. Central to our idea is the explicit exploitation of perceptual redundancies present in natural scenes. In essence, the inherent nature of a scene allows for numerous permutations of Gaussian parameters to equivalently represent it. To this end, we propose a novel highly parallel algorithm that regularly arranges the high-dimensional Gaussian parameters into a 2D grid while preserving their neighborhood structure. During training, we further enforce local smoothness between the sorted parameters in the grid. The uncompressed Gaussians use the same structure as 3DGS, ensuring a seamless integration with established renderers. Our method achieves a reduction factor of 17x to 42x in size for complex scenes with no increase in training time, marking a substantial leap forward in the domain of 3D scene distribution and consumption. Additional information can be found on our project page: https://fraunhoferhhi.github.io/Self-Organizing-Gaussians/
5/3/2024