SwarmRL: Building the Future of Smart Active Systems

0
🎲
Sign in to get full access
Overview
- Introduces SwarmRL, a Python package for studying intelligent active particles
- Provides an easy-to-use interface for developing models to control microscopic colloids using classical control and deep reinforcement learning
- Models can be deployed in simulations or real-world environments under a common framework
- Aims to streamline research into micro-robotic control and bridge the gap between experimental and simulation-driven sciences
Plain English Explanation
SwarmRL is a software tool that makes it easier for researchers to study and control tiny, microscopic particles. These particles, called "colloids," can be designed to move and behave in interesting ways, and researchers want to figure out how to control them using computer algorithms.
SwarmRL provides a common platform for researchers to develop and test different control methods, including classical control techniques and deep reinforcement learning. This means they can try out various approaches for controlling the colloids, both in computer simulations and in the real world.
The goal of SwarmRL is to help speed up research into micro-robotics, which is the field of making tiny, intelligent machines. By providing a unified system for testing control algorithms, SwarmRL aims to bridge the gap between experiments done in the real world and the computer simulations that researchers use to model and predict how these micro-scale systems will behave.
Technical Explanation
SwarmRL is a Python software package designed to facilitate research into the control of intelligent active particles. It provides an easy-to-use interface for developing models to control microscopic colloids using both classical control and deep reinforcement learning approaches. These models can then be deployed in simulations or real-world environments under a common framework.
The software is structured to allow researchers to quickly set up experiments, define colloid behaviors, and test control algorithms. It includes features for managing simulation environments, collecting and analyzing data, and deploying trained models. SwarmRL aims to streamline the research process and enable more efficient exploration of micro-robotic control strategies.
By providing a standardized platform for this type of research, SwarmRL hopes to bridge the gap between experimental and simulation-driven sciences in the field of micro-robotics. This could lead to faster progress in developing effective control methods for microscale robotic systems.
Critical Analysis
The paper introducing SwarmRL provides a clear and compelling motivation for the development of this software tool. By creating a common framework for researchers to work within, SwarmRL has the potential to accelerate progress in the field of micro-robotics.
However, the paper does not go into significant detail about the specific technical implementation of SwarmRL. While the high-level features and goals are described, more information about the underlying architecture, algorithms, and capabilities of the software would be helpful for researchers evaluating its usefulness.
Additionally, the paper does not address potential limitations or challenges that may arise in deploying SwarmRL in real-world environments. Factors such as sensor noise, environmental uncertainty, and hardware constraints could introduce complexities that are not fully captured in simulations.
Further research and user feedback will be crucial for identifying areas where SwarmRL can be improved or extended to better meet the needs of the micro-robotics research community. Robust testing and validation of the software's performance in diverse scenarios will also be important for establishing its reliability and widespread adoption.
Conclusion
SwarmRL is a promising software tool that aims to streamline research into the control of microscopic colloids and other intelligent active particles. By providing a unified platform for developing and testing control algorithms using both classical and deep reinforcement learning techniques, SwarmRL has the potential to accelerate progress in the field of micro-robotics.
The open-source availability of SwarmRL and its focus on bridging the gap between experimental and simulation-driven sciences suggest that it could become a valuable resource for researchers working at the intersection of robotics, physics, and materials science. As the software matures and gains more user feedback, it may lead to significant advancements in our ability to manipulate and control microscale systems with increasing precision and sophistication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
SwarmRL: Building the Future of Smart Active Systems
Samuel Tovey, Christoph Lohrmann, Tobias Merkt, David Zimmer, Konstantin Nikolaou, Simon Koppenhofer, Anna Bushmakina, Jonas Scheunemann, Christian Holm
This work introduces SwarmRL, a Python package designed to study intelligent active particles. SwarmRL provides an easy-to-use interface for developing models to control microscopic colloids using classical control and deep reinforcement learning approaches. These models may be deployed in simulations or real-world environments under a common framework. We explain the structure of the software and its key features and demonstrate how it can be used to accelerate research. With SwarmRL, we aim to streamline research into micro-robotic control while bridging the gap between experimental and simulation-driven sciences. SwarmRL is available open-source on GitHub at https://github.com/SwarmRL/SwarmRL.
Read more4/26/2024

0
ROS2swarm - A ROS 2 Package for Swarm Robot Behaviors
Tanja Katharina Kaiser, Marian Johannes Begemann, Tavia Plattenteich, Lars Schilling, Georg Schildbach, Heiko Hamann
Developing reusable software for mobile robots is still challenging. Even more so for swarm robots, despite the desired simplicity of the robot controllers. Prototyping and experimenting are difficult due to the multi-robot setting and often require robot-robot communication. Also, the diversity of swarm robot hardware platforms increases the need for hardware-independent software concepts. The main advantages of the commonly used robot software architecture ROS 2 are modularity and platform independence. We propose a new ROS 2 package, ROS2swarm, for applications of swarm robotics that provides a library of ready-to-use swarm behavioral primitives. We show the successful application of our approach on three different platforms, the TurtleBot3 Burger, the TurtleBot3 Waffle Pi, and the Jackal UGV, and with a set of different behavioral primitives, such as aggregation, dispersion, and collective decision-making. The proposed approach is easy to maintain, extendable, and has good potential for simplifying swarm robotics experiments in future applications.
Read more5/7/2024
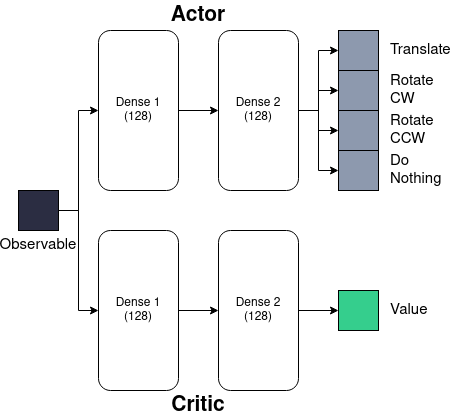
0
Emergence of Chemotactic Strategies with Multi-Agent Reinforcement Learning
Samuel Tovey, Christoph Lohrmann, Christian Holm
Reinforcement learning (RL) is a flexible and efficient method for programming micro-robots in complex environments. Here we investigate whether reinforcement learning can provide insights into biological systems when trained to perform chemotaxis. Namely, whether we can learn about how intelligent agents process given information in order to swim towards a target. We run simulations covering a range of agent shapes, sizes, and swim speeds to determine if the physical constraints on biological swimmers, namely Brownian motion, lead to regions where reinforcement learners' training fails. We find that the RL agents can perform chemotaxis as soon as it is physically possible and, in some cases, even before the active swimming overpowers the stochastic environment. We study the efficiency of the emergent policy and identify convergence in agent size and swim speeds. Finally, we study the strategy adopted by the reinforcement learning algorithm to explain how the agents perform their tasks. To this end, we identify three emerging dominant strategies and several rare approaches taken. These strategies, whilst producing almost identical trajectories in simulation, are distinct and give insight into the possible mechanisms behind which biological agents explore their environment and respond to changing conditions.
Read more4/3/2024

0
SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores
Zhiyu Mei, Wei Fu, Jiaxuan Gao, Guangju Wang, Huanchen Zhang, Yi Wu
The ever-growing complexity of reinforcement learning (RL) tasks demands a distributed system to efficiently generate and process a massive amount of data. However, existing open-source libraries suffer from various limitations, which impede their practical use in challenging scenarios where large-scale training is necessary. In this paper, we present a novel abstraction on the dataflows of RL training, which unifies diverse RL training applications into a general framework. Following this abstraction, we develop a scalable, efficient, and extensible distributed RL system called ReaLlyScalableRL, which allows efficient and massively parallelized training and easy development of customized algorithms. Our evaluation shows that SRL outperforms existing academic libraries, reaching at most 21x higher training throughput in a distributed setting. On learning performance, beyond performing and scaling well on common RL benchmarks with different RL algorithms, SRL can reproduce the same solution in the challenging hide-and-seek environment as reported by OpenAI with up to 5x speedup in wall-clock time. Notably, SRL is the first in the academic community to perform RL experiments at a large scale with over 15k CPU cores. SRL source code is available at: https://github.com/openpsi-project/srl .
Read more6/24/2024