S3Eval: A Synthetic, Scalable, Systematic Evaluation Suite for Large Language Models
2310.15147
0
0
💬
Abstract
The rapid development of Large Language Models (LLMs) has led to great strides in model capabilities like long-context understanding and reasoning. However, as LLMs are able to process longer contexts, it becomes more challenging to evaluate whether they have acquired certain capabilities, since the length of text (e.g., 200K tokens) they can process far exceeds what humans can reliably assess in a reasonable duration. In this paper, we propose using complex synthetic tasks as a proxy evaluation method, and present S3Eval, a Synthetic, Scalable, Systematic evaluation suite for LLMs evaluation. The synthetic nature of S3Eval provides users full control over the dataset, allowing them to systematically probe LLM capabilities by scaling text length and varying task difficulty across diverse scenarios. The strong correlation between S3Eval and real-world benchmarks demonstrates the soundness of using S3Eval for evaluation of LLMs. S3Eval provides a flexible and infinite long-context data generation method. We have generated a comprehensive dataset called S3Eval-Standard, and experimental results have shown that it poses significant challenges for all existing LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The rapid development of Large Language Models (LLMs) has led to significant advancements in their capabilities, including long-context understanding and reasoning.
- However, as LLMs can process longer text (up to 200K tokens), it becomes more challenging to evaluate whether they have truly acquired certain capabilities, as the length of text exceeds what humans can reliably assess.
- To address this, the authors propose using complex synthetic tasks as a proxy evaluation method and present S3Eval, a Synthetic, Scalable, Systematic evaluation suite for LLMs.
Plain English Explanation
The paper discusses the challenges of evaluating the capabilities of large language models, which are artificial intelligence systems that can understand and generate human-like text. As these models become more advanced, they can process longer and longer pieces of text, sometimes as long as 200,000 words. This makes it difficult for human researchers to thoroughly assess whether the models have truly mastered certain skills, since it's hard for people to reliably evaluate such lengthy text.
To overcome this, the researchers created a new evaluation method called S3Eval. Instead of using real-world text, S3Eval generates synthetic (artificial) tasks that are designed to systematically test the models' capabilities. This gives the researchers full control over the content and difficulty of the tasks, allowing them to explore the limits of what the models can do.
The authors found that the results from S3Eval correlate well with the models' performance on real-world benchmarks, suggesting that this synthetic approach is a valid and useful way to evaluate long-context language models. They also created a comprehensive dataset called S3Eval-Standard, which they found poses significant challenges for all existing large language models.
Technical Explanation
The paper presents S3Eval, a new evaluation suite for assessing the capabilities of large language models (LLMs). As LLMs become more advanced, they can process longer and longer pieces of text, sometimes up to 200,000 tokens. This makes it difficult for human researchers to reliably evaluate the models' abilities, as the length of text exceeds what people can easily assess.
To address this, the authors propose using complex synthetic tasks as a proxy for evaluating LLM capabilities. S3Eval provides a flexible and scalable method for generating long-context data, allowing researchers to systematically probe the models' skills by varying the length and difficulty of the tasks.
The synthetic nature of S3Eval gives the researchers full control over the dataset, enabling them to design tasks that specifically target different capabilities, such as long-context understanding and reasoning. The authors demonstrate that the results from S3Eval correlate well with the models' performance on real-world benchmarks, validating the use of this synthetic approach for LLM evaluation.
Additionally, the researchers have generated a comprehensive dataset called S3Eval-Standard, which they show poses significant challenges for all existing LLMs. This dataset provides a valuable tool for benchmarking the capabilities of large language models and tracking their progress over time.
Critical Analysis
The paper presents a novel and promising approach to evaluating the capabilities of large language models. By using synthetic tasks as a proxy for real-world performance, the authors are able to systematically probe the models' skills in a way that overcomes the limitations of human assessment.
However, the paper does not fully address the potential limitations of this synthetic approach. While the authors demonstrate a strong correlation between S3Eval and real-world benchmarks, it's possible that the synthetic tasks may not fully capture the nuances and complexities of natural language use. There may be aspects of language understanding and generation that are not adequately reflected in the artificial tasks.
Additionally, the paper does not discuss the potential biases or other issues that may arise from the process of generating the synthetic data. It's important to consider whether the generated tasks may inadvertently favor certain model architectures or training approaches over others.
Further research is needed to explore the long-term validity and generalizability of the S3Eval approach, as well as to investigate potential ways to enhance the realism and complexity of the synthetic tasks.
Conclusion
The rapid development of large language models has led to significant advancements in their capabilities, but it has also introduced new challenges in evaluating these models. The paper presents S3Eval, a novel approach that uses complex synthetic tasks as a proxy for assessing LLM capabilities, particularly in the context of long-context understanding and reasoning.
The authors demonstrate the soundness of the S3Eval approach through its strong correlation with real-world benchmarks, and they have also generated a comprehensive dataset called S3Eval-Standard that poses significant challenges for existing language models. This work provides a valuable tool for researchers and developers to systematically evaluate and track the progress of large language models, ultimately contributing to the advancement of this rapidly evolving field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
0
0
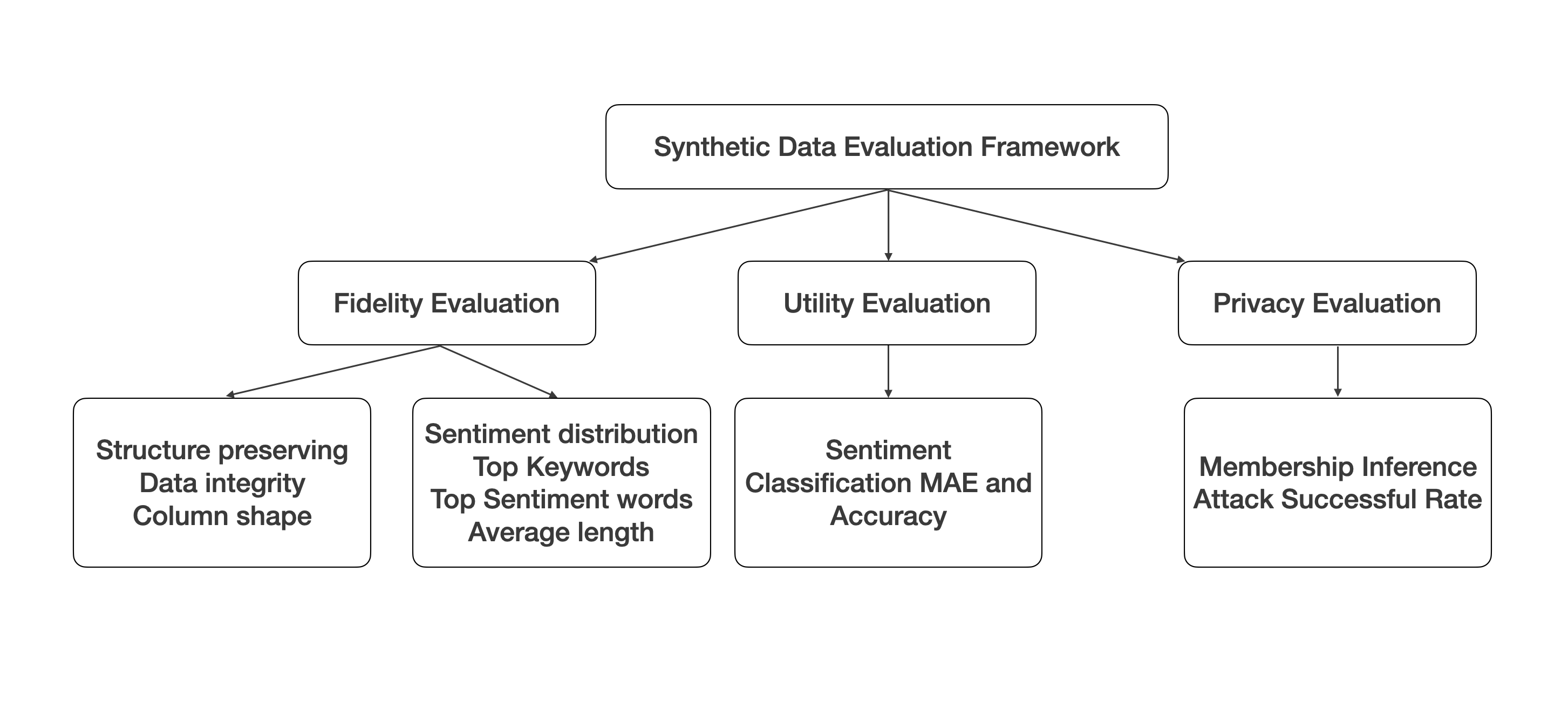
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
4/24/2024
Ada-LEval: Evaluating long-context LLMs with length-adaptable benchmarks
Chonghua Wang, Haodong Duan, Songyang Zhang, Dahua Lin, Kai Chen
0
0
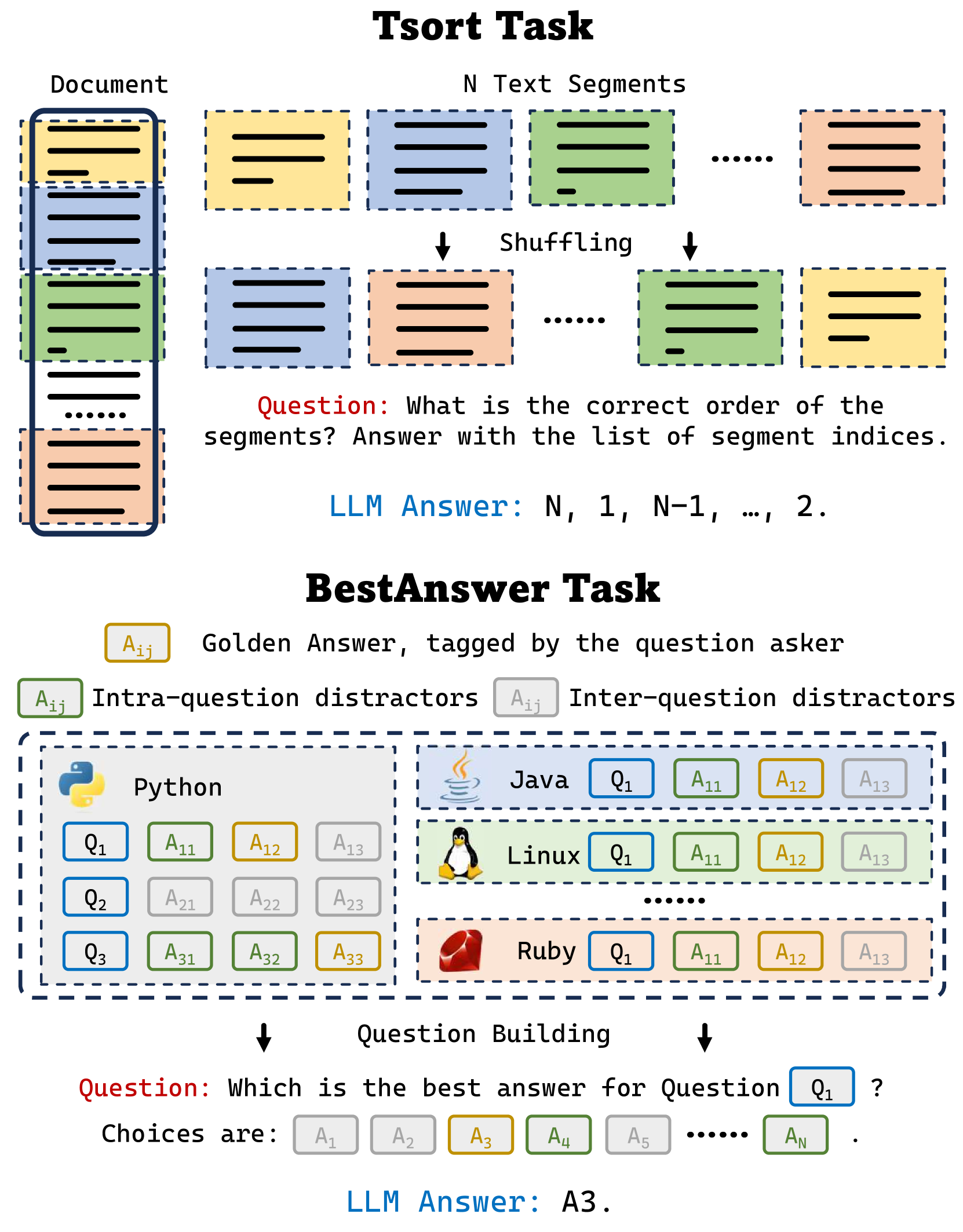
Recently, the large language model (LLM) community has shown increasing interest in enhancing LLMs' capability to handle extremely long documents. As various long-text techniques and model architectures emerge, the precise and detailed evaluation of models' long-text capabilities has become increasingly important. Existing long-text evaluation benchmarks, such as L-Eval and LongBench, construct long-text test sets based on open-source datasets, focusing mainly on QA and summarization tasks. These datasets include test samples of varying lengths (from 2k to 32k+) entangled together, making it challenging to assess model capabilities across different length ranges. Moreover, they do not cover the ultralong settings (100k+ tokens) that the latest LLMs claim to achieve. In this paper, we introduce Ada-LEval, a length-adaptable benchmark for evaluating the long-context understanding of LLMs. Ada-LEval includes two challenging subsets, TSort and BestAnswer, which enable a more reliable evaluation of LLMs' long context capabilities. These benchmarks support intricate manipulation of the length of test cases, and can easily produce text samples up to 128k tokens. We evaluate 4 state-of-the-art closed-source API models and 6 open-source models with Ada-LEval. The evaluation results demonstrate the limitations of current LLMs, especially in ultra-long-context settings. Our code is available at https://github.com/open-compass/Ada-LEval.
4/11/2024
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
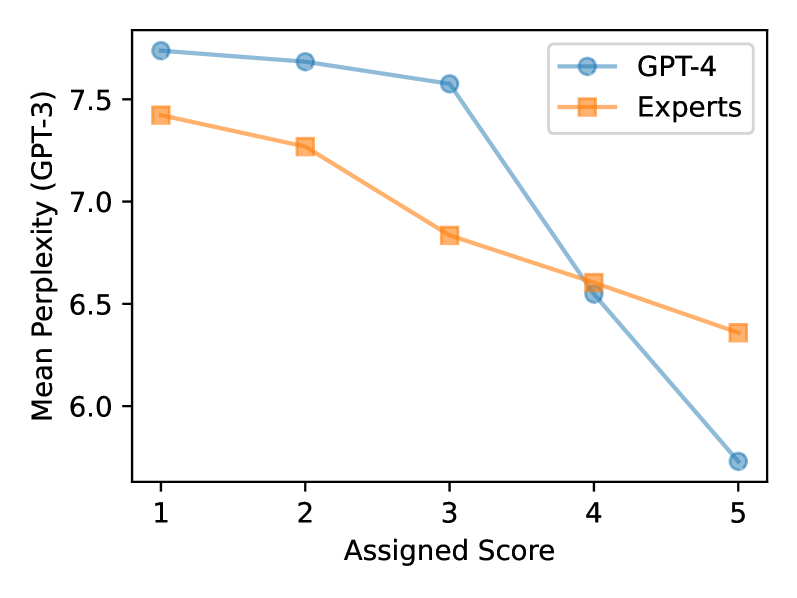
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024