SYNAuG: Exploiting Synthetic Data for Data Imbalance Problems

0
📊
Sign in to get full access
Overview
- Data imbalance in training data can lead to biased predictions from trained models, causing ethical and social issues.
- Carefully curating training data is a straightforward solution, but is often impractical due to the enormous scale of modern neural networks.
- This paper explores the use of synthetic data to address the data imbalance problem, proposing a method called SYNAuG that leverages synthetic data to equalize the unbalanced distribution of training data.
Plain English Explanation
Machine learning models are trained on datasets, and the quality of the dataset can significantly impact the model's performance and predictions. One common issue is data imbalance, where the dataset contains disproportionately more examples of some classes or categories compared to others. This can cause the model to become biased, making inaccurate predictions that may have ethical and social consequences.
A straightforward solution would be to carefully curate the training data to ensure a balanced distribution. However, as modern neural networks have grown to enormous sizes, this manual curation process becomes prohibitively labor-intensive and impractical.
Inspired by recent advancements in generative models, this paper explores the use of synthetic data to address the data imbalance problem. The researchers developed a method called SYNAuG, which generates synthetic data to balance out the uneven distribution of the original training data. Their experiments show that, although there is a gap between the real and synthetic data, training with SYNAuG followed by fine-tuning with a few real samples can achieve impressive performance on diverse tasks with different data imbalance issues, outperforming existing task-specific methods designed for the same purpose.
Technical Explanation
The paper proposes a method called SYNAuG (Synthetic Data Augmentation) to address the data imbalance problem in machine learning. SYNAuG leverages synthetic data generation to equalize the unbalanced distribution of the original training data.
The researchers first train a generative model, such as a Generative Adversarial Network (GAN) or a Variational Autoencoder (VAE), on the available training data. This generative model is then used to synthesize additional data samples for the underrepresented classes or categories, effectively balancing the overall distribution of the training dataset.
The paper presents experiments on diverse tasks with different data imbalance issues, such as image classification and text classification. The results show that, although there is a domain gap between the real and synthetic data, training with SYNAuG followed by fine-tuning with a few real samples can outperform existing task-specific methods designed for the same purpose.
Critical Analysis
The paper presents a promising approach to addressing the data imbalance problem, which is a common and challenging issue in machine learning. The use of synthetic data generation to balance the training data distribution is an interesting and potentially scalable solution.
However, the paper acknowledges the existence of a domain gap between the real and synthetic data, which may limit the effectiveness of the approach. The researchers attempt to mitigate this by fine-tuning the model with a small number of real samples, but this additional step introduces additional complexity and may not be feasible in all scenarios.
Furthermore, the paper does not provide a comprehensive analysis of the potential limitations or drawbacks of the SYNAuG method. For example, it does not address the potential for the synthetic data to introduce new biases or artifacts that could negatively impact the model's performance.
Future research could explore ways to further reduce the domain gap between real and synthetic data, perhaps through more advanced generative modeling techniques or domain adaptation methods. Additionally, a more thorough investigation of the potential pitfalls and mitigation strategies would be valuable for practitioners considering the use of synthetic data in their own projects.
Conclusion
This paper presents a novel approach to addressing the data imbalance problem in machine learning, which is a critical issue that can lead to biased and unethical predictions. By leveraging synthetic data generation through the SYNAuG method, the researchers demonstrate that it is possible to equalize the unbalanced distribution of training data and achieve impressive performance on diverse tasks.
While the approach shows promise, the existence of a domain gap between real and synthetic data remains a limitation that requires further investigation. Nonetheless, the paper's exploration of synthetic data as a means to tackle data imbalance is a valuable contribution to the field, and the insights gained can inform future research and practical applications in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
SYNAuG: Exploiting Synthetic Data for Data Imbalance Problems
Moon Ye-Bin, Nam Hyeon-Woo, Wonseok Choi, Nayeong Kim, Suha Kwak, Tae-Hyun Oh
Data imbalance in training data often leads to biased predictions from trained models, which in turn causes ethical and social issues. A straightforward solution is to carefully curate training data, but given the enormous scale of modern neural networks, this is prohibitively labor-intensive and thus impractical. Inspired by recent developments in generative models, this paper explores the potential of synthetic data to address the data imbalance problem. To be specific, our method, dubbed SYNAuG, leverages synthetic data to equalize the unbalanced distribution of training data. Our experiments demonstrate that, although a domain gap between real and synthetic data exists, training with SYNAuG followed by fine-tuning with a few real samples allows to achieve impressive performance on diverse tasks with different data imbalance issues, surpassing existing task-specific methods for the same purpose.
Read more4/26/2024
0
A Survey of Data Synthesis Approaches
Hsin-Yu Chang, Pei-Yu Chen, Tun-Hsiang Chou, Chang-Sheng Kao, Hsuan-Yun Yu, Yen-Ting Lin, Yun-Nung Chen
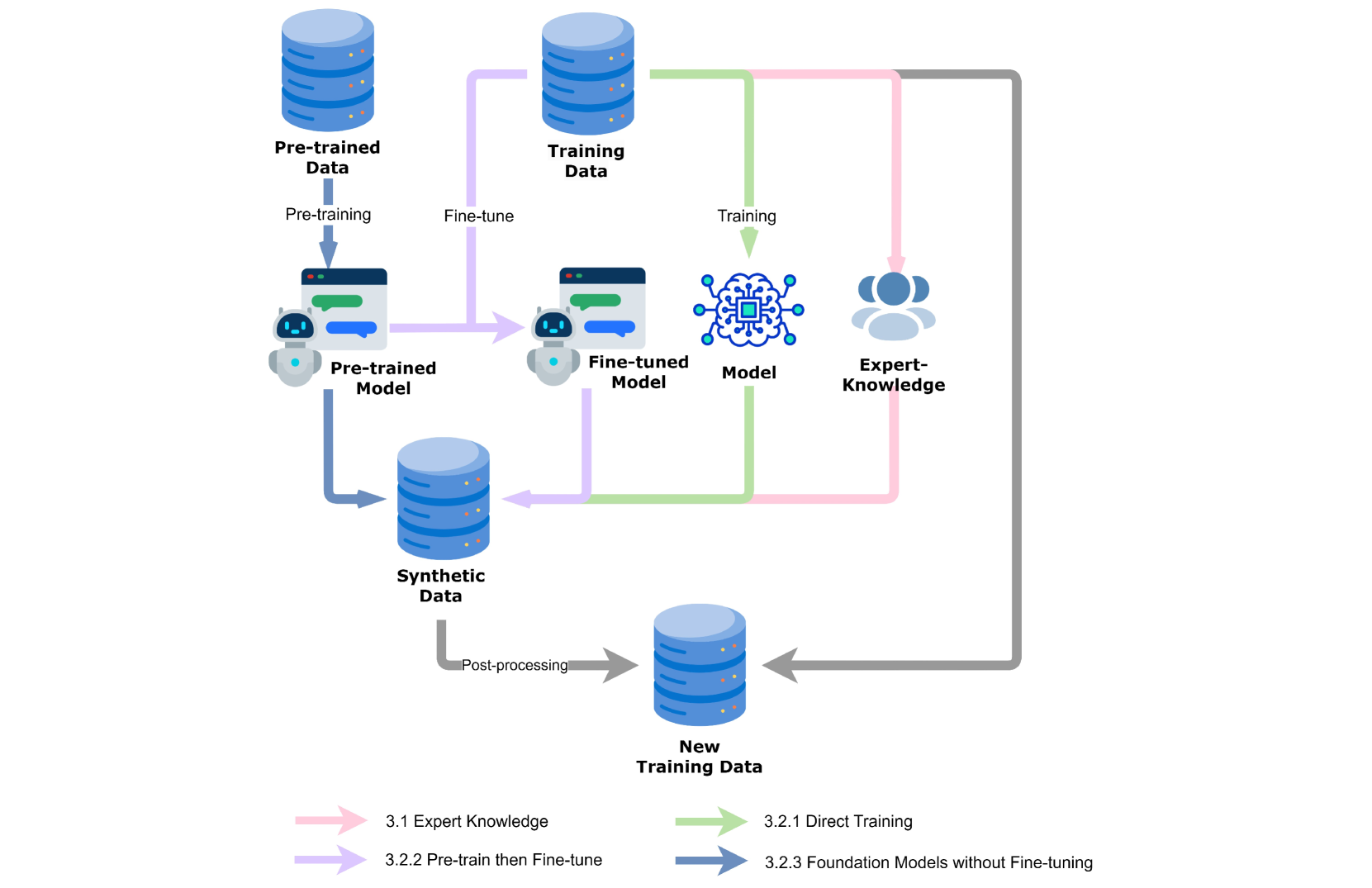
This paper provides a detailed survey of synthetic data techniques. We first discuss the expected goals of using synthetic data in data augmentation, which can be divided into four parts: 1) Improving Diversity, 2) Data Balancing, 3) Addressing Domain Shift, and 4) Resolving Edge Cases. Synthesizing data are closely related to the prevailing machine learning techniques at the time, therefore, we summarize the domain of synthetic data techniques into four categories: 1) Expert-knowledge, 2) Direct Training, 3) Pre-train then Fine-tune, and 4) Foundation Models without Fine-tuning. Next, we categorize the goals of synthetic data filtering into four types for discussion: 1) Basic Quality, 2) Label Consistency, and 3) Data Distribution. In section 5 of this paper, we also discuss the future directions of synthetic data and state three direction that we believe is important: 1) focus more on quality, 2) the evaluation of synthetic data, and 3) multi-model data augmentation.
Read more7/8/2024

0
Feedback-guided Data Synthesis for Imbalanced Classification
Reyhane Askari Hemmat, Mohammad Pezeshki, Florian Bordes, Michal Drozdzal, Adriana Romero-Soriano
Current status quo in machine learning is to use static datasets of real images for training, which often come from long-tailed distributions. With the recent advances in generative models, researchers have started augmenting these static datasets with synthetic data, reporting moderate performance improvements on classification tasks. We hypothesize that these performance gains are limited by the lack of feedback from the classifier to the generative model, which would promote the usefulness of the generated samples to improve the classifier's performance. In this work, we introduce a framework for augmenting static datasets with useful synthetic samples, which leverages one-shot feedback from the classifier to drive the sampling of the generative model. In order for the framework to be effective, we find that the samples must be close to the support of the real data of the task at hand, and be sufficiently diverse. We validate three feedback criteria on a long-tailed dataset (ImageNet-LT) as well as a group-imbalanced dataset (NICO++). On ImageNet-LT, we achieve state-of-the-art results, with over 4 percent improvement on underrepresented classes while being twice efficient in terms of the number of generated synthetic samples. NICO++ also enjoys marked boosts of over 5 percent in worst group accuracy. With these results, our framework paves the path towards effectively leveraging state-of-the-art text-to-image models as data sources that can be queried to improve downstream applications.
Read more9/11/2024

0
Synthetic Tabular Data Generation for Class Imbalance and Fairness: A Comparative Study
Emmanouil Panagiotou, Arjun Roy, Eirini Ntoutsi
Due to their data-driven nature, Machine Learning (ML) models are susceptible to bias inherited from data, especially in classification problems where class and group imbalances are prevalent. Class imbalance (in the classification target) and group imbalance (in protected attributes like sex or race) can undermine both ML utility and fairness. Although class and group imbalances commonly coincide in real-world tabular datasets, limited methods address this scenario. While most methods use oversampling techniques, like interpolation, to mitigate imbalances, recent advancements in synthetic tabular data generation offer promise but have not been adequately explored for this purpose. To this end, this paper conducts a comparative analysis to address class and group imbalances using state-of-the-art models for synthetic tabular data generation and various sampling strategies. Experimental results on four datasets, demonstrate the effectiveness of generative models for bias mitigation, creating opportunities for further exploration in this direction.
Read more9/10/2024