SynDARin: Synthesising Datasets for Automated Reasoning in Low-Resource Languages
2406.14425
0
0

Abstract
Question Answering (QA) datasets have been instrumental in developing and evaluating Large Language Model (LLM) capabilities. However, such datasets are scarce for languages other than English due to the cost and difficulties of collection and manual annotation. This means that producing novel models and measuring the performance of multilingual LLMs in low-resource languages is challenging. To mitigate this, we propose $textbf{S}$yn$textbf{DAR}$in, a method for generating and validating QA datasets for low-resource languages. We utilize parallel content mining to obtain $textit{human-curated}$ paragraphs between English and the target language. We use the English data as context to $textit{generate}$ synthetic multiple-choice (MC) question-answer pairs, which are automatically translated and further validated for quality. Combining these with their designated non-English $textit{human-curated}$ paragraphs form the final QA dataset. The method allows to maintain the content quality, reduces the likelihood of factual errors, and circumvents the need for costly annotation. To test the method, we created a QA dataset with $1.2$K samples for the Armenian language. The human evaluation shows that $98%$ of the generated English data maintains quality and diversity in the question types and topics, while the translation validation pipeline can filter out $sim70%$ of data with poor quality. We use the dataset to benchmark state-of-the-art LLMs, showing their inability to achieve human accuracy with some model performances closer to random chance. This shows that the generated dataset is non-trivial and can be used to evaluate reasoning capabilities in low-resource language.
Create account to get full access
Overview
- This paper introduces SynDARin, a technique for synthesizing datasets for automated reasoning in low-resource languages.
- The approach involves using machine translation and rule-based generation to create large-scale datasets for tasks like question answering, commonsense reasoning, and more.
- SynDARin aims to address the data scarcity challenge in developing AI systems for low-resource languages.
Plain English Explanation
SynDARin: Synthesising Datasets for Automated Reasoning in Low-Resource Languages is a research paper that presents a new method for creating synthetic datasets. The key problem it tries to solve is the lack of large, high-quality datasets for training AI models in low-resource languages, which are languages that don't have as much digital content and data available compared to major world languages like English.
The researchers developed a technique called SynDARin that takes existing datasets in high-resource languages like English and uses machine translation and rule-based generation to create similar datasets in low-resource languages. This allows them to build up large-scale datasets for tasks like question answering, commonsense reasoning, and more, even for languages that don't have much data available.
The idea is that by having these synthetic datasets, researchers and developers can then use them to fine-tune and train AI models like transformer models for low-resource languages. This helps address the data scarcity challenge and enables the development of more capable AI systems in a wider range of languages.
Technical Explanation
SynDARin: Synthesising Datasets for Automated Reasoning in Low-Resource Languages presents a novel approach for creating synthetic datasets to support automated reasoning tasks in low-resource languages.
The key components of the SynDARin methodology are:
-
Dataset Seed Selection: The researchers start with high-quality datasets in a high-resource language like English that cover tasks such as question answering, commonsense reasoning, and more.
-
Machine Translation: They then use machine translation to translate the source language dataset into the target low-resource language. This provides the initial set of samples in the low-resource language.
-
Rule-Based Generation: To expand the dataset, the researchers employ rule-based generation techniques. This involves applying linguistic rules and heuristics to systematically modify and generate new samples in the target language.
-
Dataset Curation: The synthetic datasets produced through translation and generation are then curated to ensure quality and remove any erroneous or nonsensical samples.
The researchers evaluate the SynDARin approach on several low-resource languages, including Marathi, Hindi-English, and Translated Fairytales. The results demonstrate the effectiveness of SynDARin in generating high-quality datasets that can be used to fine-tune transformer models for improved performance on automated reasoning tasks in low-resource languages.
Critical Analysis
The SynDARin approach presented in this paper is a promising step towards addressing the data scarcity challenge in developing AI systems for low-resource languages. By leveraging machine translation and rule-based generation, the researchers are able to create large-scale datasets that can be used to fine-tune and train more capable models.
However, the paper also acknowledges some limitations of the current approach. The quality of the synthetic datasets is still dependent on the accuracy of the machine translation and the effectiveness of the rule-based generation. There may be cases where the generated samples do not fully capture the nuances and complexities of the target language.
Additionally, the paper focuses on relatively narrow tasks like question answering and commonsense reasoning. It would be valuable to see the SynDARin methodology applied to a broader range of language understanding and generation tasks to further demonstrate its versatility and generalizability.
Overall, the SynDARin technique represents an important contribution to the field of low-resource language AI. By enabling the creation of high-quality synthetic datasets, it has the potential to accelerate the development of more inclusive and accessible AI systems that can serve a wider range of global communities.
Conclusion
The SynDARin paper introduces a novel approach for generating synthetic datasets to support automated reasoning tasks in low-resource languages. By combining machine translation and rule-based generation, the researchers are able to create large-scale datasets that can be used to fine-tune and train AI models, addressing the data scarcity challenge in this domain.
The results demonstrate the effectiveness of the SynDARin technique across several low-resource languages, paving the way for more inclusive and accessible AI systems that can serve a broader global audience. While the approach has some limitations, it represents an important step forward in the field of low-resource language AI, with the potential to unlock new possibilities for language understanding and reasoning across a diverse range of languages and cultures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Synthetic Dataset Creation and Fine-Tuning of Transformer Models for Question Answering in Serbian
Aleksa Cvetanovi'c, Predrag Tadi'c
0
0
In this paper, we focus on generating a synthetic question answering (QA) dataset using an adapted Translate-Align-Retrieve method. Using this method, we created the largest Serbian QA dataset of more than 87K samples, which we name SQuAD-sr. To acknowledge the script duality in Serbian, we generated both Cyrillic and Latin versions of the dataset. We investigate the dataset quality and use it to fine-tune several pre-trained QA models. Best results were obtained by fine-tuning the BERTi'c model on our Latin SQuAD-sr dataset, achieving 73.91% Exact Match and 82.97% F1 score on the benchmark XQuAD dataset, which we translated into Serbian for the purpose of evaluation. The results show that our model exceeds zero-shot baselines, but fails to go beyond human performance. We note the advantage of using a monolingual pre-trained model over multilingual, as well as the performance increase gained by using Latin over Cyrillic. By performing additional analysis, we show that questions about numeric values or dates are more likely to be answered correctly than other types of questions. Finally, we conclude that SQuAD-sr is of sufficient quality for fine-tuning a Serbian QA model, in the absence of a manually crafted and annotated dataset.
4/15/2024
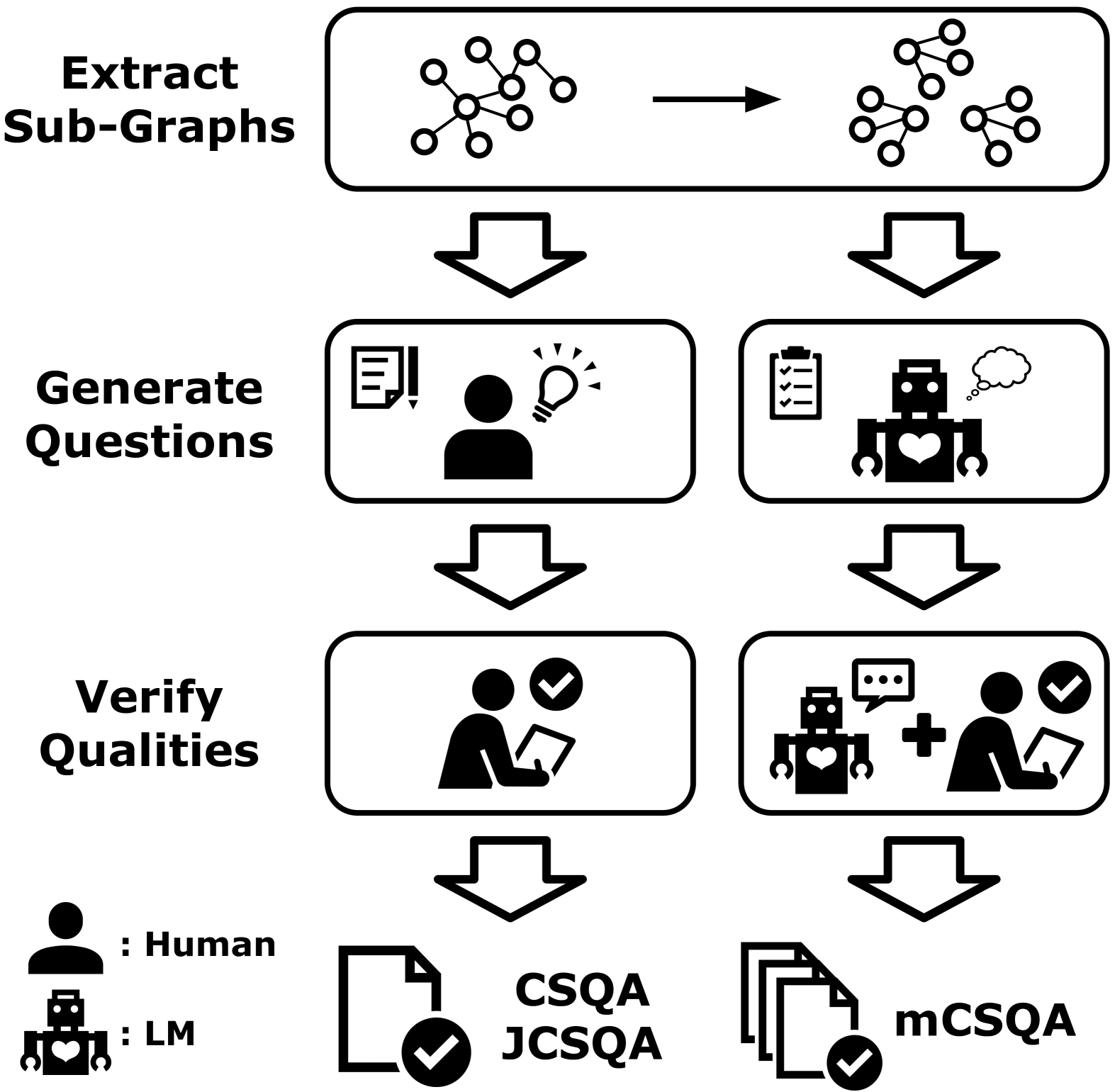
mCSQA: Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans
Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
0
0
It is very challenging to curate a dataset for language-specific knowledge and common sense in order to evaluate natural language understanding capabilities of language models. Due to the limitation in the availability of annotators, most current multilingual datasets are created through translation, which cannot evaluate such language-specific aspects. Therefore, we propose Multilingual CommonsenseQA (mCSQA) based on the construction process of CSQA but leveraging language models for a more efficient construction, e.g., by asking LM to generate questions/answers, refine answers and verify QAs followed by reduced human efforts for verification. Constructed dataset is a benchmark for cross-lingual language-transfer capabilities of multilingual LMs, and experimental results showed high language-transfer capabilities for questions that LMs could easily solve, but lower transfer capabilities for questions requiring deep knowledge or commonsense. This highlights the necessity of language-specific datasets for evaluation and training. Finally, our method demonstrated that multilingual LMs could create QA including language-specific knowledge, significantly reducing the dataset creation cost compared to manual creation. The datasets are available at https://huggingface.co/datasets/yusuke1997/mCSQA.
6/7/2024

FairytaleQA Translated: Enabling Educational Question and Answer Generation in Less-Resourced Languages
Bernardo Leite, Tom'as Freitas Os'orio, Henrique Lopes Cardoso
0
0
Question Answering (QA) datasets are crucial in assessing reading comprehension skills for both machines and humans. While numerous datasets have been developed in English for this purpose, a noticeable void exists in less-resourced languages. To alleviate this gap, our paper introduces machine-translated versions of FairytaleQA, a renowned QA dataset designed to assess and enhance narrative comprehension skills in young children. By employing fine-tuned, modest-scale models, we establish benchmarks for both Question Generation (QG) and QA tasks within the translated datasets. In addition, we present a case study proposing a model for generating question-answer pairs, with an evaluation incorporating quality metrics such as question well-formedness, answerability, relevance, and children suitability. Our evaluation prioritizes quantifying and describing error cases, along with providing directions for future work. This paper contributes to the advancement of QA and QG research in less-resourced languages, promoting accessibility and inclusivity in the development of these models for reading comprehension. The code and data is publicly available at github.com/bernardoleite/fairytaleqa-translated.
6/26/2024
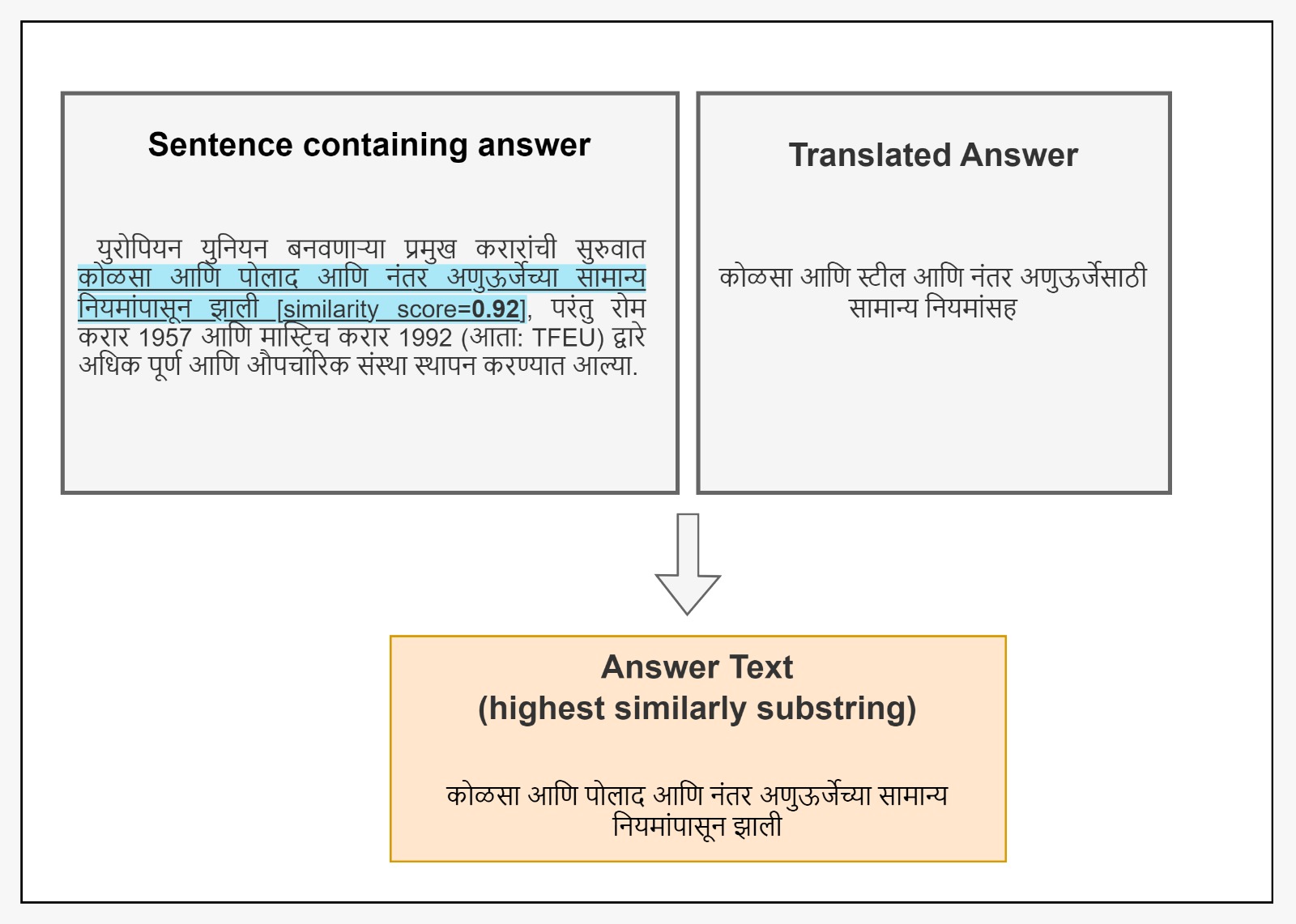
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
0
0
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
4/23/2024