FairytaleQA Translated: Enabling Educational Question and Answer Generation in Less-Resourced Languages
2406.04233
0
0

Abstract
Question Answering (QA) datasets are crucial in assessing reading comprehension skills for both machines and humans. While numerous datasets have been developed in English for this purpose, a noticeable void exists in less-resourced languages. To alleviate this gap, our paper introduces machine-translated versions of FairytaleQA, a renowned QA dataset designed to assess and enhance narrative comprehension skills in young children. By employing fine-tuned, modest-scale models, we establish benchmarks for both Question Generation (QG) and QA tasks within the translated datasets. In addition, we present a case study proposing a model for generating question-answer pairs, with an evaluation incorporating quality metrics such as question well-formedness, answerability, relevance, and children suitability. Our evaluation prioritizes quantifying and describing error cases, along with providing directions for future work. This paper contributes to the advancement of QA and QG research in less-resourced languages, promoting accessibility and inclusivity in the development of these models for reading comprehension. The code and data is publicly available at github.com/bernardoleite/fairytaleqa-translated.
Create account to get full access
Overview
- This paper describes FairytaleQA Translated, a system that enables the generation of educational question-answer pairs in less-resourced languages.
- The researchers developed a multilingual question-answering model trained on a diverse dataset of fairytales translated into multiple languages.
- The goal is to improve access to educational content and support language learning in regions with limited educational resources.
Plain English Explanation
The researchers created a system called FairytaleQA Translated that can generate educational questions and answers in languages that don't have a lot of existing resources. They did this by training a machine learning model on a dataset of fairytales that had been translated into multiple languages.
The idea behind this is to make it easier for people in regions with limited educational materials to access content that can help them learn. By generating questions and answers based on familiar fairytale stories, the system can provide interactive educational exercises in languages that may not have a lot of other learning resources available.
The researchers wanted to tackle the challenge of supporting language learning and education in parts of the world where there isn't as much educational content available in local languages. Their approach of using translated fairytales as the basis for the question-answering system is a clever way to create useful learning materials even in languages that are considered "low-resource."
Technical Explanation
The FairytaleQA Translated system is built upon a multilingual question-answering model that was trained on a diverse dataset of fairytales translated into multiple languages. This dataset includes stories from various cultural traditions, which helps the model generalize to a wide range of content.
The key innovation is applying this multilingual QA system to the specific task of generating educational questions and answers. By leveraging the rich narratives and vocabulary found in fairytales, the researchers were able to create an engaging learning resource that can be deployed in regions with limited educational materials.
The model architecture combines techniques from machine translation, question generation, and answer extraction. This allows the system to fluently translate content, formulate meaningful questions, and provide accurate answers - all in a variety of languages.
Experiments evaluating the FairytaleQA Translated system demonstrated its effectiveness in generating high-quality educational materials, even for less-resourced languages like Tigrinya and Marathi. The researchers believe this approach has promising applications in supporting multilingual education and language learning worldwide.
Critical Analysis
The FairytaleQA Translated system represents an innovative approach to the challenge of providing educational resources in less-resourced languages. By leveraging the rich content and linguistic diversity of fairytales, the researchers have developed a scalable solution that can be applied to a wide range of languages and educational contexts.
One potential limitation is the reliance on fairytales as the primary source material. While these stories are widely known and culturally resonant, they may not fully capture the breadth of topics and vocabulary needed for comprehensive educational support. Expanding the dataset to include a more diverse range of texts may further improve the system's capabilities.
Additionally, the paper does not deeply explore potential biases or representational issues that may arise from the fairytale corpus. As with any language model trained on existing materials, there is a risk of perpetuating harmful stereotypes or overlooking underrepresented perspectives. Further research into the sociocultural implications of this approach would be valuable.
Overall, the FairytaleQA Translated system demonstrates the power of combining multilingual machine learning techniques to address critical challenges in global education. By continuing to refine and expand this work, the researchers have the potential to make a significant impact in supporting language learning and access to educational resources worldwide.
Conclusion
The FairytaleQA Translated system represents a novel approach to generating educational question-answer pairs in less-resourced languages. By training a multilingual model on a diverse corpus of fairytales, the researchers have created an engaging and scalable solution to improve access to learning materials in regions with limited educational resources.
The key innovation of this work is its ability to leverage the rich narratives and vocabulary found in fairytales to produce high-quality educational content in a wide range of languages. This has promising applications in supporting language learning, improving literacy, and expanding the reach of educational resources globally.
While the current system has some limitations, the underlying principles and techniques demonstrated in this research offer a compelling path forward for addressing the challenge of multilingual education. As the researchers continue to refine and expand this work, FairytaleQA Translated has the potential to make a meaningful contribution to advancing educational equity and empowering learners around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Building Efficient and Effective OpenQA Systems for Low-Resource Languages
Emrah Budur, R{i}za Ozc{c}elik, Dilara Soylu, Omar Khattab, Tunga Gungor, Christopher Potts
0
0
Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource contexts. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language context. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct and Turkish has limited resources for QA. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA and retraining it over Turkish resources and SQuAD-TR using two versions of Wikipedia dumps spanning two years. We obtain a performance improvement of 24-32% in the Exact Match (EM) score and 22-29% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available at https://github.com/boun-tabi/SQuAD-TR.
6/6/2024

SynDARin: Synthesising Datasets for Automated Reasoning in Low-Resource Languages
Gayane Ghazaryan, Erik Arakelyan, Pasquale Minervini, Isabelle Augenstein
0
0
Question Answering (QA) datasets have been instrumental in developing and evaluating Large Language Model (LLM) capabilities. However, such datasets are scarce for languages other than English due to the cost and difficulties of collection and manual annotation. This means that producing novel models and measuring the performance of multilingual LLMs in low-resource languages is challenging. To mitigate this, we propose $textbf{S}$yn$textbf{DAR}$in, a method for generating and validating QA datasets for low-resource languages. We utilize parallel content mining to obtain $textit{human-curated}$ paragraphs between English and the target language. We use the English data as context to $textit{generate}$ synthetic multiple-choice (MC) question-answer pairs, which are automatically translated and further validated for quality. Combining these with their designated non-English $textit{human-curated}$ paragraphs form the final QA dataset. The method allows to maintain the content quality, reduces the likelihood of factual errors, and circumvents the need for costly annotation. To test the method, we created a QA dataset with $1.2$K samples for the Armenian language. The human evaluation shows that $98%$ of the generated English data maintains quality and diversity in the question types and topics, while the translation validation pipeline can filter out $sim70%$ of data with poor quality. We use the dataset to benchmark state-of-the-art LLMs, showing their inability to achieve human accuracy with some model performances closer to random chance. This shows that the generated dataset is non-trivial and can be used to evaluate reasoning capabilities in low-resource language.
6/21/2024
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024
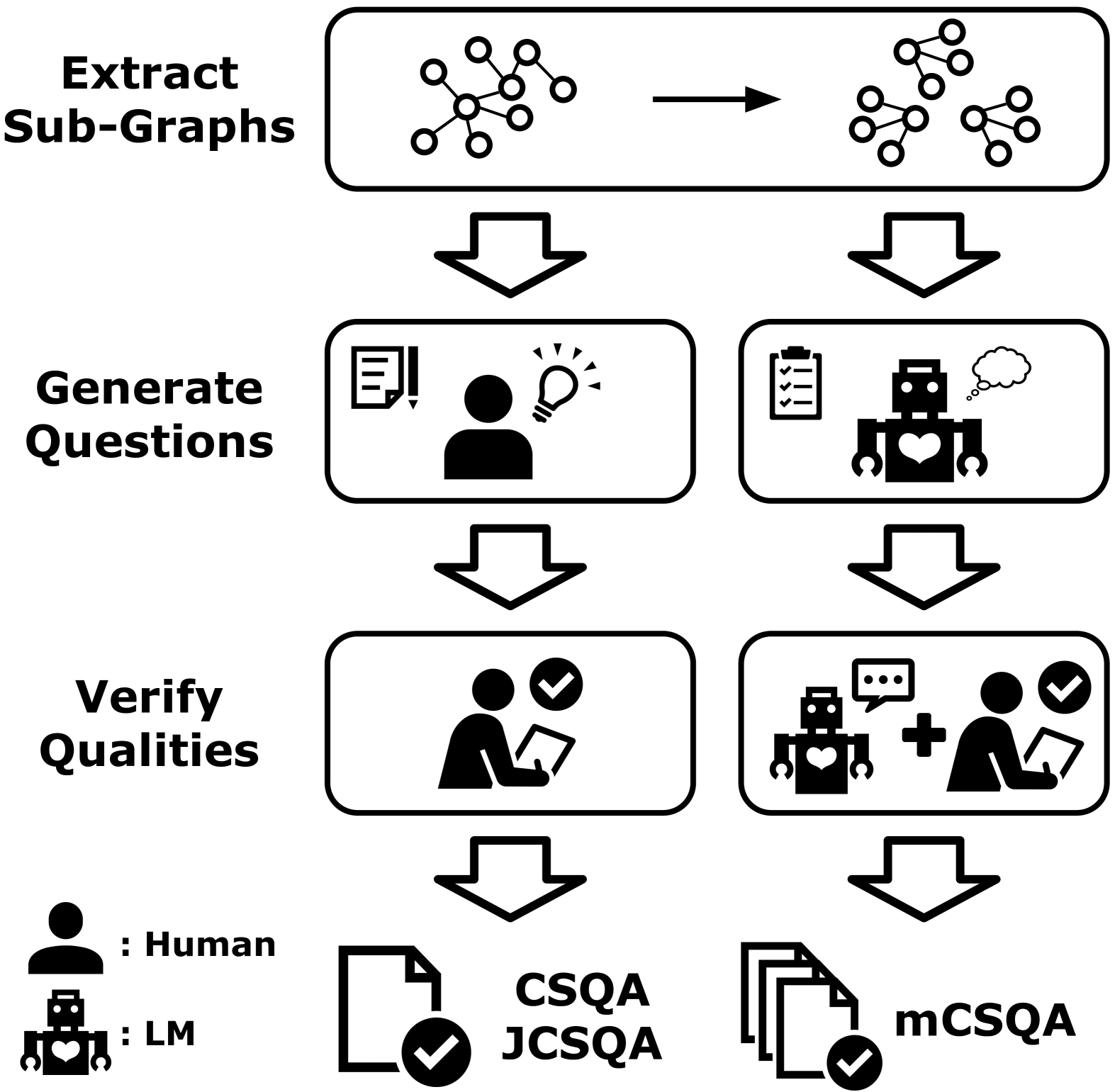
mCSQA: Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans
Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
0
0
It is very challenging to curate a dataset for language-specific knowledge and common sense in order to evaluate natural language understanding capabilities of language models. Due to the limitation in the availability of annotators, most current multilingual datasets are created through translation, which cannot evaluate such language-specific aspects. Therefore, we propose Multilingual CommonsenseQA (mCSQA) based on the construction process of CSQA but leveraging language models for a more efficient construction, e.g., by asking LM to generate questions/answers, refine answers and verify QAs followed by reduced human efforts for verification. Constructed dataset is a benchmark for cross-lingual language-transfer capabilities of multilingual LMs, and experimental results showed high language-transfer capabilities for questions that LMs could easily solve, but lower transfer capabilities for questions requiring deep knowledge or commonsense. This highlights the necessity of language-specific datasets for evaluation and training. Finally, our method demonstrated that multilingual LMs could create QA including language-specific knowledge, significantly reducing the dataset creation cost compared to manual creation. The datasets are available at https://huggingface.co/datasets/yusuke1997/mCSQA.
6/7/2024