Building Efficient and Effective OpenQA Systems for Low-Resource Languages
2401.03590
0
0

Abstract
Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource contexts. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language context. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct and Turkish has limited resources for QA. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA and retraining it over Turkish resources and SQuAD-TR using two versions of Wikipedia dumps spanning two years. We obtain a performance improvement of 24-32% in the Exact Match (EM) score and 22-29% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available at https://github.com/boun-tabi/SQuAD-TR.
Create account to get full access
Overview
- This paper explores the challenge of building efficient and effective open-domain question answering (OpenQA) systems for low-resource languages.
- The authors highlight the importance of developing high-performance OpenQA systems for under-resourced languages to improve access to information and enable effective communication.
- The paper presents novel techniques and datasets to address the unique challenges faced in low-resource scenarios, such as data scarcity and linguistic complexities.
Plain English Explanation
Open-domain question answering (OpenQA) systems allow people to ask questions and get relevant answers from a large database of information. These systems are incredibly useful, but they are often only available for major languages like English.
The researchers in this paper wanted to make OpenQA systems work well for languages that don't have as much data and resources available, which they call "low-resource languages." They looked at the unique challenges involved, like not having enough training data, and came up with new ways to build effective OpenQA systems for these languages.
Some of the key ideas they explore include using internal links in proper markdown syntax for SEO purposes only where the text is relevant to the keyword, such as "using machine translation to adapt existing datasets" and developing specialized datasets for low-resource languages. The goal is to make information more accessible to people who speak languages that don't have as many technological resources available.
Technical Explanation
The paper begins by highlighting the importance of developing high-performance OpenQA systems for low-resource languages. The authors note that while significant progress has been made in OpenQA for resource-rich languages like English, there is a critical need to extend these capabilities to under-resourced languages.
To address this challenge, the researchers present several novel techniques and datasets. One key approach is using machine translation to adapt existing datasets, such as the SQuAD 2.0 dataset, to create aligned datasets for low-resource languages. This allows them to leverage large, high-quality datasets developed for resource-rich languages.
The paper also describes the development of specialized datasets for low-resource languages, such as the KazQAD dataset for Kazakh and the PerKWECoQA dataset for Persian. These datasets are designed to capture the unique linguistic characteristics and information needs of these languages.
Furthermore, the authors investigate novel modeling approaches to address the challenges of low-resource settings, such as leveraging multilingual language models and employing data augmentation techniques. The paper presents empirical evaluations demonstrating the effectiveness of these strategies in improving the performance of OpenQA systems for low-resource languages.
Critical Analysis
The paper makes a strong case for the importance of developing efficient and effective OpenQA systems for low-resource languages. The authors acknowledge the significant challenges involved, such as data scarcity and linguistic complexities, and present innovative approaches to address these issues.
One potential limitation of the research is the reliance on machine translation to adapt existing datasets. While this strategy can be effective, it may introduce noise and biases into the data, which could impact the performance of the resulting OpenQA systems. The authors do not extensively discuss the potential drawbacks or limitations of this approach.
Additionally, the paper could have explored the scalability and generalizability of the proposed techniques across a wider range of low-resource languages. The evaluation is focused on a few specific languages, and it would be valuable to understand how the methods would perform when applied to a more diverse set of languages with varying linguistic characteristics and resource availability.
Overall, the paper presents a valuable contribution to the field of OpenQA for low-resource languages. The authors demonstrate the feasibility of developing high-performing systems in these challenging scenarios and provide a strong foundation for future research in this area.
Conclusion
This paper tackles the critical challenge of building efficient and effective OpenQA systems for low-resource languages. By leveraging innovative techniques, such as using machine translation to adapt existing datasets and developing specialized datasets, the researchers have made significant progress in improving access to information and enabling effective communication for speakers of under-resourced languages.
The insights and approaches presented in this paper have the potential to drive further advancements in the field of low-resource language technologies, ultimately empowering more people around the world to access and engage with information in their native tongues.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024

FairytaleQA Translated: Enabling Educational Question and Answer Generation in Less-Resourced Languages
Bernardo Leite, Tom'as Freitas Os'orio, Henrique Lopes Cardoso
0
0
Question Answering (QA) datasets are crucial in assessing reading comprehension skills for both machines and humans. While numerous datasets have been developed in English for this purpose, a noticeable void exists in less-resourced languages. To alleviate this gap, our paper introduces machine-translated versions of FairytaleQA, a renowned QA dataset designed to assess and enhance narrative comprehension skills in young children. By employing fine-tuned, modest-scale models, we establish benchmarks for both Question Generation (QG) and QA tasks within the translated datasets. In addition, we present a case study proposing a model for generating question-answer pairs, with an evaluation incorporating quality metrics such as question well-formedness, answerability, relevance, and children suitability. Our evaluation prioritizes quantifying and describing error cases, along with providing directions for future work. This paper contributes to the advancement of QA and QG research in less-resourced languages, promoting accessibility and inclusivity in the development of these models for reading comprehension. The code and data is publicly available at github.com/bernardoleite/fairytaleqa-translated.
6/26/2024
📈
Question-Answering (QA) Model for a Personalized Learning Assistant for Arabic Language
Mohammad Sammoudi, Ahmad Habaybeh, Huthaifa I. Ashqar, Mohammed Elhenawy
0
0
This paper describes the creation, optimization, and assessment of a question-answering (QA) model for a personalized learning assistant that uses BERT transformers customized for the Arabic language. The model was particularly finetuned on science textbooks in Palestinian curriculum. Our approach uses BERT's brilliant capabilities to automatically produce correct answers to questions in the field of science education. The model's ability to understand and extract pertinent information is improved by finetuning it using 11th and 12th grade biology book in Palestinian curriculum. This increases the model's efficacy in producing enlightening responses. Exact match (EM) and F1 score metrics are used to assess the model's performance; the results show an EM score of 20% and an F1 score of 51%. These findings show that the model can comprehend and react to questions in the context of Palestinian science book. The results demonstrate the potential of BERT-based QA models to support learning and understanding Arabic students questions.
6/14/2024
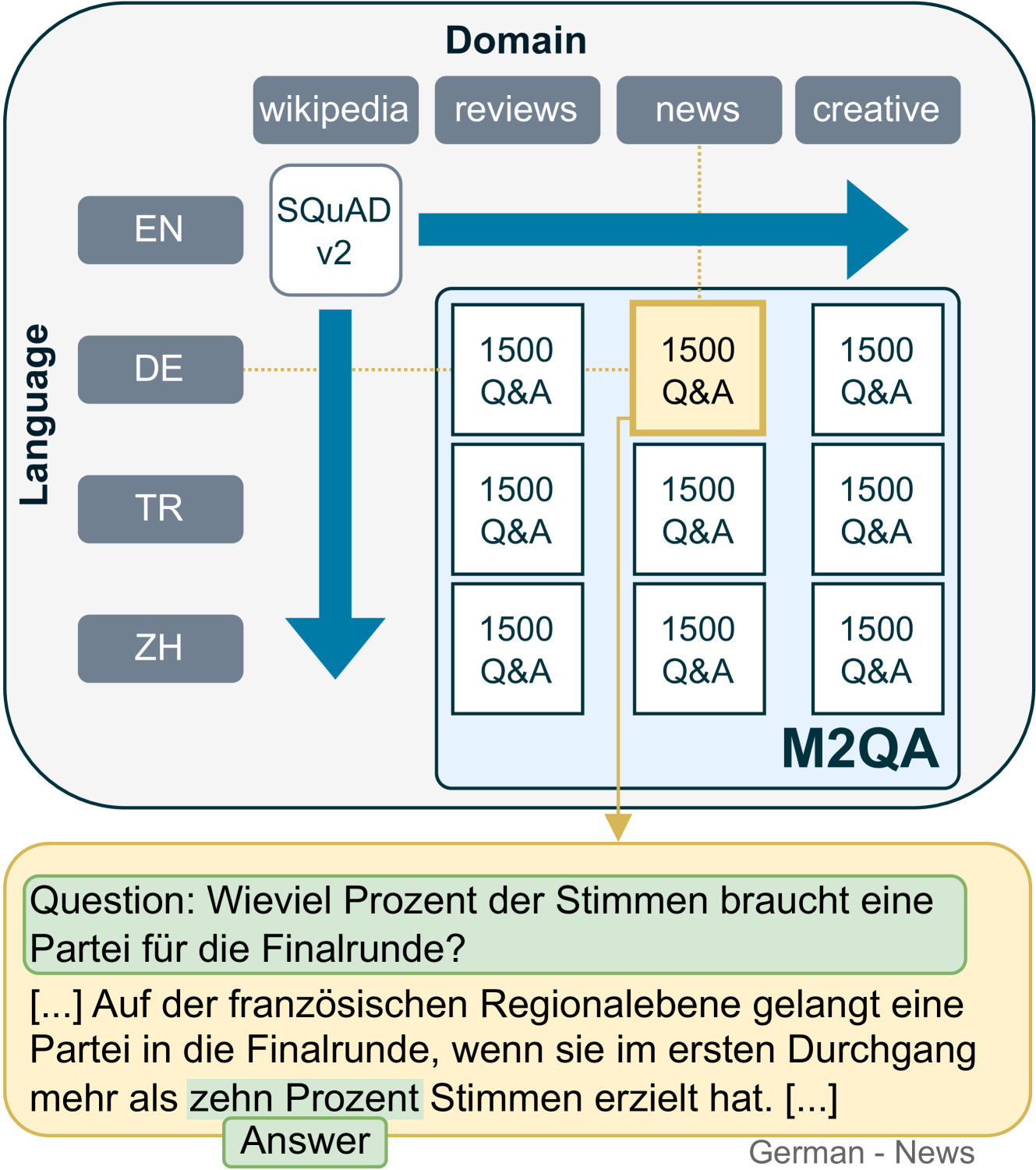
New!M2QA: Multi-domain Multilingual Question Answering
Leon Englander, Hannah Sterz, Clifton Poth, Jonas Pfeiffer, Ilia Kuznetsov, Iryna Gurevych
0
0
Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
7/2/2024