Synthetic Test Collections for Retrieval Evaluation

0
🐍
Sign in to get full access
Overview
- Test collections are crucial for evaluating information retrieval (IR) systems
- Obtaining diverse user queries and relevance judgments for test collections can be challenging and resource-intensive
- Generating synthetic datasets using Large Language Models (LLMs) has gained attention in various applications
- Previous work has used LLMs to generate synthetic queries or documents to improve ranking models, but using LLMs to construct synthetic test collections is relatively unexplored
Plain English Explanation
Test collections are like libraries of sample search queries and relevant documents that researchers use to evaluate how well their information retrieval systems are performing. However, building these test collections can be tricky. Coming up with a diverse set of search queries and determining which documents are relevant to each query is often a lot of work.
Recently, researchers have explored using powerful language models to generate synthetic data that can be used to supplement or even replace real-world data in various applications. In the field of information retrieval, while previous studies have shown that these language models can be used to generate synthetic queries or documents to improve search ranking models, using them to create entire synthetic test collections is a relatively new and unexplored idea.
Technical Explanation
This paper investigates whether it is possible to use large language models (LLMs) to construct fully synthetic test collections for evaluating information retrieval (IR) systems. The researchers analyze whether it's possible to create reliable synthetic test collections and explore the potential risks of bias that such synthetic collections may exhibit towards LLM-based IR models.
The experiments conducted in the paper indicate that it is indeed possible to use LLMs to construct synthetic test collections that can be reliably used for retrieval evaluation. The researchers compare different methods for evaluating the quality of these generative IR test collections and find that the synthetic collections perform comparably to traditional, human-curated test collections in terms of their ability to assess the performance of IR systems.
Critical Analysis
The paper suggests that using LLMs to generate synthetic test collections could be a promising approach, as it could help address the challenges of obtaining diverse queries and relevance judgments for traditional test collections. However, the researchers also note some potential risks and limitations of this approach.
One concern is the potential for bias in the synthetic test collections, as the language models may tend to generate queries and relevance judgments that favor LLM-based IR models. The researchers discuss their findings on evaluating this bias and suggest that further research is needed to fully understand the implications of using LLM-generated test collections.
Additionally, the paper does not explore the long-term reliability and stability of these synthetic test collections, which could be an important factor in their practical application. More research may be needed to understand how well the synthetic collections can capture the evolving nature of user information needs and the dynamics of real-world search scenarios.
Conclusion
This paper presents an intriguing approach to using large language models to construct synthetic test collections for evaluating information retrieval systems. The results suggest that it is possible to create reliable synthetic test collections, which could help address the challenges of obtaining diverse queries and relevance judgments for traditional test collections.
However, the potential for bias in these synthetic collections and the need for further research on their long-term reliability and stability are important considerations that warrant further investigation. As the field of information retrieval continues to evolve, exploring innovative approaches like this could lead to valuable advancements in how we evaluate and improve search technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
Synthetic Test Collections for Retrieval Evaluation
Hossein A. Rahmani, Nick Craswell, Emine Yilmaz, Bhaskar Mitra, Daniel Campos
Test collections play a vital role in evaluation of information retrieval (IR) systems. Obtaining a diverse set of user queries for test collection construction can be challenging, and acquiring relevance judgments, which indicate the appropriateness of retrieved documents to a query, is often costly and resource-intensive. Generating synthetic datasets using Large Language Models (LLMs) has recently gained significant attention in various applications. In IR, while previous work exploited the capabilities of LLMs to generate synthetic queries or documents to augment training data and improve the performance of ranking models, using LLMs for constructing synthetic test collections is relatively unexplored. Previous studies demonstrate that LLMs have the potential to generate synthetic relevance judgments for use in the evaluation of IR systems. In this paper, we comprehensively investigate whether it is possible to use LLMs to construct fully synthetic test collections by generating not only synthetic judgments but also synthetic queries. In particular, we analyse whether it is possible to construct reliable synthetic test collections and the potential risks of bias such test collections may exhibit towards LLM-based models. Our experiments indicate that using LLMs it is possible to construct synthetic test collections that can reliably be used for retrieval evaluation.
Read more5/14/2024

0
SynDL: A Large-Scale Synthetic Test Collection
Hossein A. Rahmani, Xi Wang, Emine Yilmaz, Nick Craswell, Bhaskar Mitra, Paul Thomas
Large-scale test collections play a crucial role in Information Retrieval (IR) research. However, according to the Cranfield paradigm and the research into publicly available datasets, the existing information retrieval research studies are commonly developed on small-scale datasets that rely on human assessors for relevance judgments - a time-intensive and expensive process. Recent studies have shown the strong capability of Large Language Models (LLMs) in producing reliable relevance judgments with human accuracy but at a greatly reduced cost. In this paper, to address the missing large-scale ad-hoc document retrieval dataset, we extend the TREC Deep Learning Track (DL) test collection via additional language model synthetic labels to enable researchers to test and evaluate their search systems at a large scale. Specifically, such a test collection includes more than 1,900 test queries from the previous years of tracks. We compare system evaluation with past human labels from past years and find that our synthetically created large-scale test collection can lead to highly correlated system rankings.
Read more9/2/2024
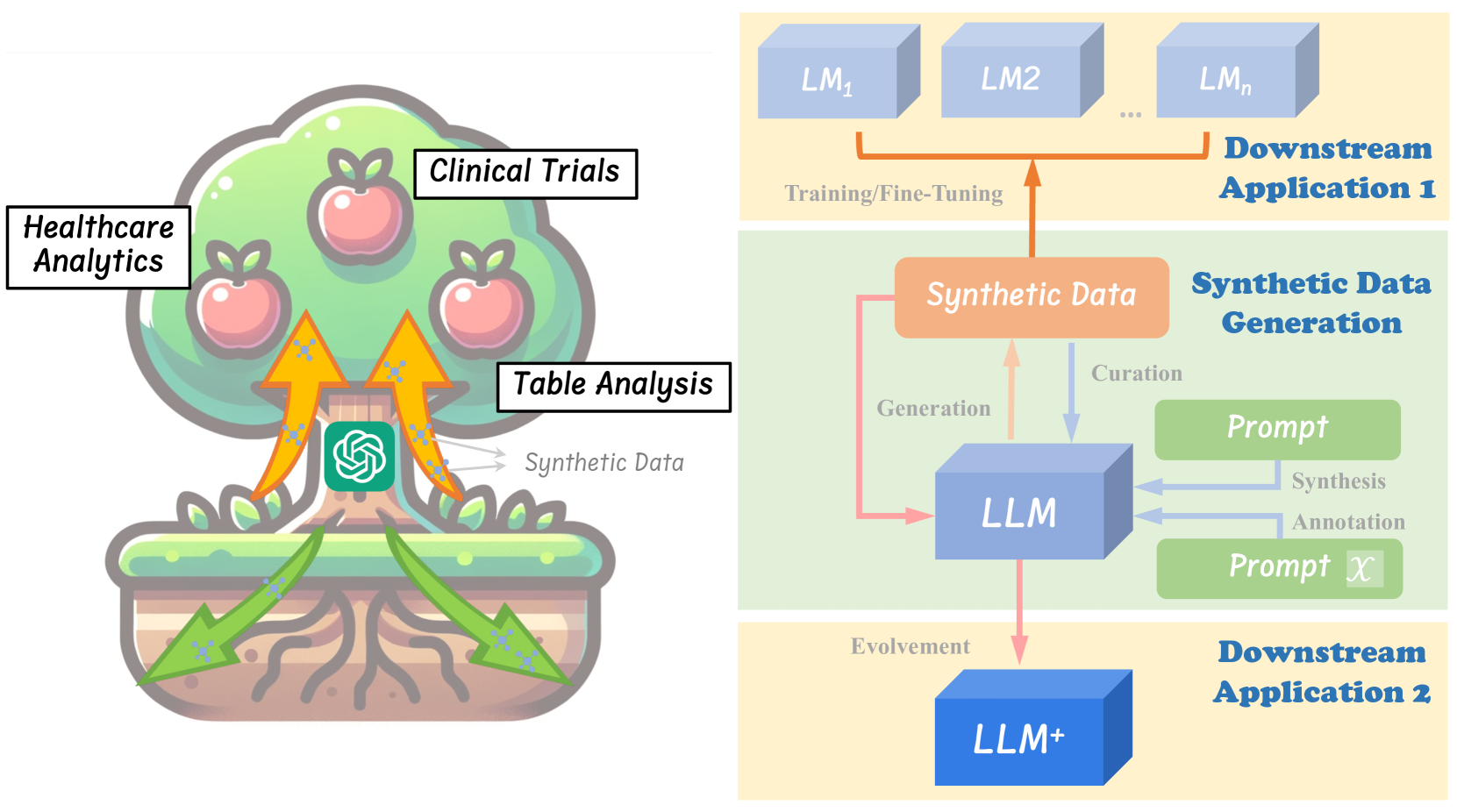
0
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024

0
Generative Information Retrieval Evaluation
Marwah Alaofi, Negar Arabzadeh, Charles L. A. Clarke, Mark Sanderson
This paper is a draft of a chapter intended to appear in a forthcoming book on generative information retrieval, co-edited by Chirag Shah and Ryen White. In this chapter, we consider generative information retrieval evaluation from two distinct but interrelated perspectives. First, large language models (LLMs) themselves are rapidly becoming tools for evaluation, with current research indicating that LLMs may be superior to crowdsource workers and other paid assessors on basic relevance judgement tasks. We review past and ongoing related research, including speculation on the future of shared task initiatives, such as TREC, and a discussion on the continuing need for human assessments. Second, we consider the evaluation of emerging LLM-based generative information retrieval (GenIR) systems, including retrieval augmented generation (RAG) systems. We consider approaches that focus both on the end-to-end evaluation of GenIR systems and on the evaluation of a retrieval component as an element in a RAG system. Going forward, we expect the evaluation of GenIR systems to be at least partially based on LLM-based assessment, creating an apparent circularity, with a system seemingly evaluating its own output. We resolve this apparent circularity in two ways: 1) by viewing LLM-based assessment as a form of slow search, where a slower IR system is used for evaluation and training of a faster production IR system; and 2) by recognizing a continuing need to ground evaluation in human assessment, even if the characteristics of that human assessment must change.
Read more4/17/2024