Leveraging LLMs for Synthesizing Training Data Across Many Languages in Multilingual Dense Retrieval

0
🏋️
Sign in to get full access
Overview
- Researchers have had limited success in using dense retrieval models for multilingual information retrieval, due to uneven and scarce training data across multiple languages.
- Synthetic training data generation techniques like InPars and Promptagator have only been investigated for English so far.
- To study model capabilities across both cross-lingual and monolingual retrieval tasks, the researchers developed SWIM-IR, a synthetic retrieval training dataset covering 33 languages, for fine-tuning multilingual dense retrievers without human supervision.
Plain English Explanation
Retrieval models are AI systems that can find relevant information in response to a given query. While these models have become quite powerful, they have struggled when working with multiple languages, especially for languages that have less available training data.
To address this, the researchers created a new dataset called SWIM-IR. This dataset contains synthetic (computer-generated) training examples in 33 different languages, ranging from high-resource to very low-resource languages. By using this dataset to fine-tune multilingual retrieval models, the researchers aimed to enable these models to perform well on both cross-lingual retrieval (finding relevant information across languages) and monolingual retrieval (finding relevant information within the same language) tasks.
The key innovation in creating SWIM-IR was the use of a "summarize-then-ask" prompting technique. This approach had the language model first generate a summary of the input text, and then use that summary to generate more informative queries in the target language. This helped the model better understand the content and produce higher-quality queries, even for low-resource languages.
The researchers then evaluated the models trained on SWIM-IR, called SWIM-X, on several benchmark datasets for retrieval. They found that these models performed competitively with existing human-supervised retrieval models, demonstrating that SWIM-IR can be a cost-effective substitute for expensive human-labeled retrieval training data.
Technical Explanation
To construct the SWIM-IR dataset, the researchers proposed a "summarize-then-ask" (SAP) prompting technique. In this approach, the large language model (LLM) first generates a textual summary of the input, and then uses that summary to generate informative queries in the target language. This helps the LLM better understand the content and produce higher-quality queries, even for low-resource languages.
The SWIM-IR dataset covers 33 languages, ranging from high-resource to very low-resource, and contains synthetic training examples for fine-tuning multilingual dense retrieval models. The researchers then evaluated the models trained on SWIM-IR, called SWIM-X, on three retrieval benchmarks: XOR-Retrieve (cross-lingual), MIRACL (monolingual), and XTREME-UP (cross-lingual).
The results show that the SWIM-X models are competitive with human-supervised dense retrieval models, such as mContriever-X, demonstrating that SWIM-IR can be a cost-effective substitute for expensive human-labeled retrieval training data.
Critical Analysis
The researchers acknowledge that while SWIM-IR is a promising approach, it still has some limitations. For example, the synthetic queries generated by the LLM may not fully capture the nuances and complexities of real-world information needs. Additionally, the evaluation was limited to a few benchmark datasets, and further testing on a wider range of scenarios would be beneficial to fully understand the capabilities and limitations of the SWIM-X models.
It would also be interesting to see how the SWIM-IR approach compares to other techniques for generating multilingual training data, such as machine translation-based data augmentation or cross-lingual transfer learning. Exploring the trade-offs between the different approaches could provide valuable insights for improving multilingual retrieval systems.
Overall, the SWIM-IR dataset and SWIM-X models represent an exciting step forward in addressing the challenges of multilingual information retrieval. By leveraging the power of large language models and synthetic data generation, the researchers have demonstrated a scalable and cost-effective way to enable retrieval models to perform well across a wide range of languages.
Conclusion
The SWIM-IR dataset and SWIM-X models provide a promising solution to the challenges of multilingual information retrieval. By using a "summarize-then-ask" prompting technique to generate synthetic training data in 33 languages, the researchers have shown that it is possible to fine-tune powerful multilingual retrieval models without the need for expensive human-labeled data.
The performance of the SWIM-X models on benchmark tasks suggests that this approach can be a cost-effective alternative to traditional human-supervised methods, with the potential to significantly expand the reach and accessibility of information retrieval systems across the global, multilingual landscape.
As the field of natural language processing continues to evolve, techniques like SWIM-IR will likely play an increasingly important role in enabling AI systems to understand and communicate in multiple languages, unlocking new possibilities for cross-cultural collaboration, knowledge sharing, and mutual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Leveraging LLMs for Synthesizing Training Data Across Many Languages in Multilingual Dense Retrieval
Nandan Thakur, Jianmo Ni, Gustavo Hern'andez 'Abrego, John Wieting, Jimmy Lin, Daniel Cer
There has been limited success for dense retrieval models in multilingual retrieval, due to uneven and scarce training data available across multiple languages. Synthetic training data generation is promising (e.g., InPars or Promptagator), but has been investigated only for English. Therefore, to study model capabilities across both cross-lingual and monolingual retrieval tasks, we develop SWIM-IR, a synthetic retrieval training dataset containing 33 (high to very-low resource) languages for fine-tuning multilingual dense retrievers without requiring any human supervision. To construct SWIM-IR, we propose SAP (summarize-then-ask prompting), where the large language model (LLM) generates a textual summary prior to the query generation step. SAP assists the LLM in generating informative queries in the target language. Using SWIM-IR, we explore synthetic fine-tuning of multilingual dense retrieval models and evaluate them robustly on three retrieval benchmarks: XOR-Retrieve (cross-lingual), MIRACL (monolingual) and XTREME-UP (cross-lingual). Our models, called SWIM-X, are competitive with human-supervised dense retrieval models, e.g., mContriever-X, finding that SWIM-IR can cheaply substitute for expensive human-labeled retrieval training data. SWIM-IR dataset and SWIM-X models are available at https://github.com/google-research-datasets/SWIM-IR.
Read more4/17/2024
0
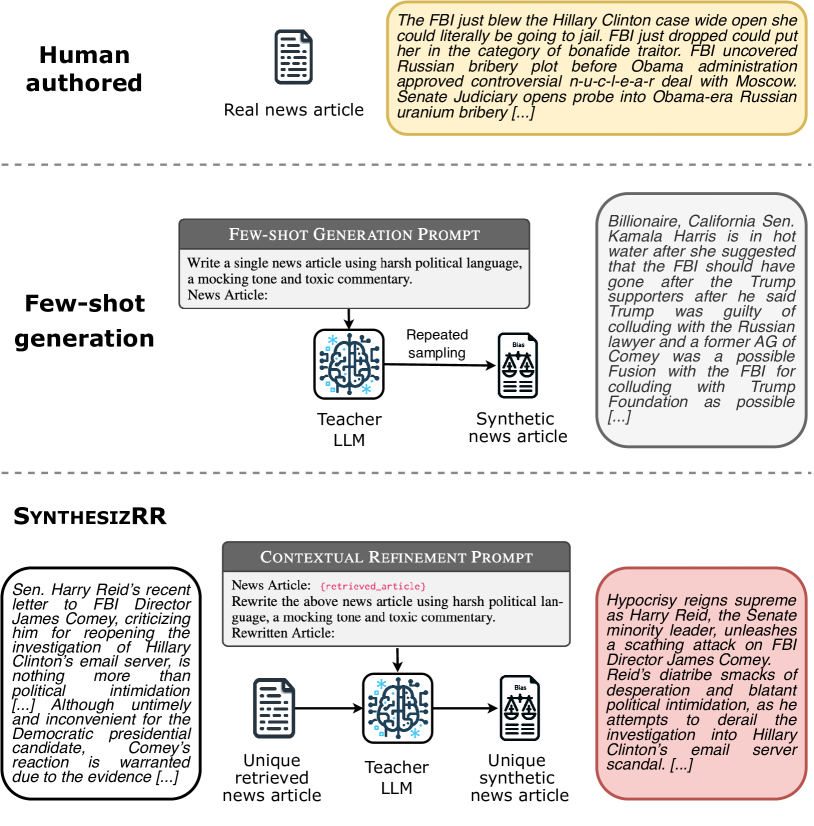
SynthesizRR: Generating Diverse Datasets with Retrieval Augmentation
Abhishek Divekar, Greg Durrett
It is often desirable to distill the capabilities of large language models (LLMs) into smaller student models due to compute and memory constraints. One way to do this for classification tasks is via dataset synthesis, which can be accomplished by generating examples of each label from the LLM. Prior approaches to synthesis use few-shot prompting, which relies on the LLM's parametric knowledge to generate usable examples. However, this leads to issues of repetition, bias towards popular entities, and stylistic differences from human text. In this work, we propose Synthesize by Retrieval and Refinement (SynthesizRR), which uses retrieval augmentation to introduce variety into the dataset synthesis process: as retrieved passages vary, the LLM is seeded with different content to generate its examples. We empirically study the synthesis of six datasets, covering topic classification, sentiment analysis, tone detection, and humor, requiring complex synthesis strategies. We find that SynthesizRR greatly improves lexical and semantic diversity, similarity to human-written text, and distillation performance, when compared to 32-shot prompting and four prior approaches. We release our extensive codebase at https://github.com/amazon-science/synthesizrr
Read more7/9/2024

0
Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
Read more7/11/2024

0
Synergistic Approach for Simultaneous Optimization of Monolingual, Cross-lingual, and Multilingual Information Retrieval
Adel Elmahdy, Sheng-Chieh Lin, Amin Ahmad
Information retrieval across different languages is an increasingly important challenge in natural language processing. Recent approaches based on multilingual pre-trained language models have achieved remarkable success, yet they often optimize for either monolingual, cross-lingual, or multilingual retrieval performance at the expense of others. This paper proposes a novel hybrid batch training strategy to simultaneously improve zero-shot retrieval performance across monolingual, cross-lingual, and multilingual settings while mitigating language bias. The approach fine-tunes multilingual language models using a mix of monolingual and cross-lingual question-answer pair batches sampled based on dataset size. Experiments on XQuAD-R, MLQA-R, and MIRACL benchmark datasets show that the proposed method consistently achieves comparable or superior results in zero-shot retrieval across various languages and retrieval tasks compared to monolingual-only or cross-lingual-only training. Hybrid batch training also substantially reduces language bias in multilingual retrieval compared to monolingual training. These results demonstrate the effectiveness of the proposed approach for learning language-agnostic representations that enable strong zero-shot retrieval performance across diverse languages.
Read more8/21/2024