SynopGround: A Large-Scale Dataset for Multi-Paragraph Video Grounding from TV Dramas and Synopses

0

Sign in to get full access
Overview
- SynopGround is a large-scale dataset for multi-paragraph video grounding from TV dramas and synopses
- It aims to advance research in long-term multimodal content understanding
- The dataset contains over 130,000 video-text pairs from 300 TV drama episodes and their corresponding synopses
Plain English Explanation
The SynopGround dataset is designed to help researchers develop AI systems that can better understand the connections between video content and the written descriptions of that content. Specifically, it contains a large collection of TV drama episodes paired with the written summaries or "synopses" of those episodes.
By training AI models on this dataset, researchers can develop systems that can link video scenes to the relevant parts of the written synopsis. This is a challenging task, as the videos and synopses can cover multiple storylines and events over an extended period of time.
Successful multi-paragraph video grounding systems could have applications in areas like long-term video understanding, automated video summarization, and generating relevant video captions.
Technical Explanation
The SynopGround dataset consists of over 130,000 video-text pairs from 300 TV drama episodes and their corresponding synopses. Each video is on average 45 minutes long, and the associated synopses contain multiple paragraphs describing the events and storylines.
To create the dataset, the researchers first extracted the video and text data from various TV drama sources. They then used a weakly supervised learning approach to automatically align the video content with the relevant parts of the synopses.
This alignment process is challenging due to the complexity of the video and text data. The videos contain multiple concurrent storylines, while the synopses summarize these storylines across multiple paragraphs. The researchers had to develop techniques to handle this long-term, multi-paragraph structure.
Critical Analysis
One limitation of the SynopGround dataset is that it is focused on a specific domain of TV dramas. While this allows for in-depth study of multi-paragraph video grounding in a realistic setting, it may not fully generalize to other types of video content, such as instructional videos or movie narratives.
Additionally, the automatic alignment process used to create the dataset, while innovative, may introduce some noise or errors that could impact the quality of the ground truth annotations. Further research could explore ways to improve the alignment process or incorporate manual verification to ensure high-quality labels.
Conclusion
The SynopGround dataset represents an important step forward in the field of long-term multimodal content understanding. By providing a large-scale resource for training and evaluating multi-paragraph video grounding systems, it can help drive progress in areas like video summarization, captioning, and narrative understanding. As AI technologies continue to advance, datasets like SynopGround will be crucial for developing robust and versatile multimodal systems that can better comprehend the complexities of real-world video content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SynopGround: A Large-Scale Dataset for Multi-Paragraph Video Grounding from TV Dramas and Synopses
Chaolei Tan, Zihang Lin, Junfu Pu, Zhongang Qi, Wei-Yi Pei, Zhi Qu, Yexin Wang, Ying Shan, Wei-Shi Zheng, Jian-Fang Hu
Video grounding is a fundamental problem in multimodal content understanding, aiming to localize specific natural language queries in an untrimmed video. However, current video grounding datasets merely focus on simple events and are either limited to shorter videos or brief sentences, which hinders the model from evolving toward stronger multimodal understanding capabilities. To address these limitations, we present a large-scale video grounding dataset named SynopGround, in which more than 2800 hours of videos are sourced from popular TV dramas and are paired with accurately localized human-written synopses. Each paragraph in the synopsis serves as a language query and is manually annotated with precise temporal boundaries in the long video. These paragraph queries are tightly correlated to each other and contain a wealth of abstract expressions summarizing video storylines and specific descriptions portraying event details, which enables the model to learn multimodal perception on more intricate concepts over longer context dependencies. Based on the dataset, we further introduce a more complex setting of video grounding dubbed Multi-Paragraph Video Grounding (MPVG), which takes as input multiple paragraphs and a long video for grounding each paragraph query to its temporal interval. In addition, we propose a novel Local-Global Multimodal Reasoner (LGMR) to explicitly model the local-global structures of long-term multimodal inputs for MPVG. Our method provides an effective baseline solution to the multi-paragraph video grounding problem. Extensive experiments verify the proposed model's effectiveness as well as its superiority in long-term multi-paragraph video grounding over prior state-of-the-arts. Dataset and code are publicly available. Project page: https://synopground.github.io/.
Read more8/20/2024
0
Multi-Sentence Grounding for Long-term Instructional Video
Zeqian Li, Qirui Chen, Tengda Han, Ya Zhang, Yanfeng Wang, Weidi Xie
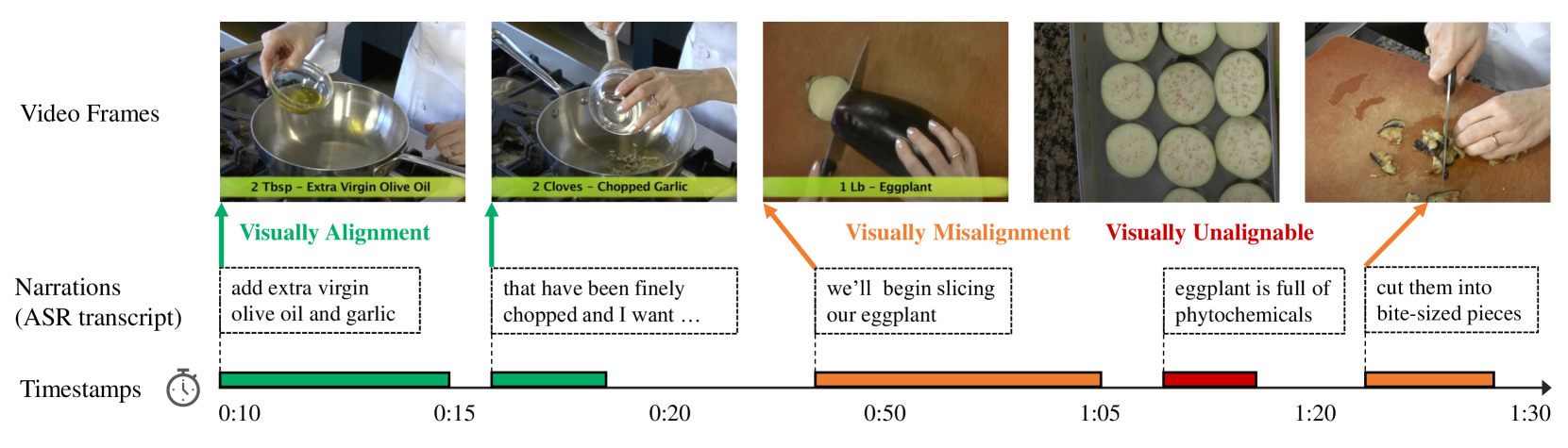
In this paper, we aim to establish an automatic, scalable pipeline for denoising the large-scale instructional dataset and construct a high-quality video-text dataset with multiple descriptive steps supervision, named HowToStep. We make the following contributions: (i) improving the quality of sentences in dataset by upgrading ASR systems to reduce errors from speech recognition and prompting a large language model to transform noisy ASR transcripts into descriptive steps; (ii) proposing a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to temporally align the generated steps to corresponding video segments. To measure the quality of our curated datasets, we train models for the task of multi-sentence grounding on it, i.e., given a long-form video, and associated multiple sentences, to determine their corresponding timestamps in the video simultaneously, as a result, the model shows superior performance on a series of multi-sentence grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.0% on HT-Step, 5.1% on HTM-Align and 1.9% on CrossTask. All codes, models, and the resulting dataset have been publicly released.
Read more7/23/2024
0
Multi-sentence Video Grounding for Long Video Generation
Wei Feng, Xin Wang, Hong Chen, Zeyang Zhang, Wenwu Zhu
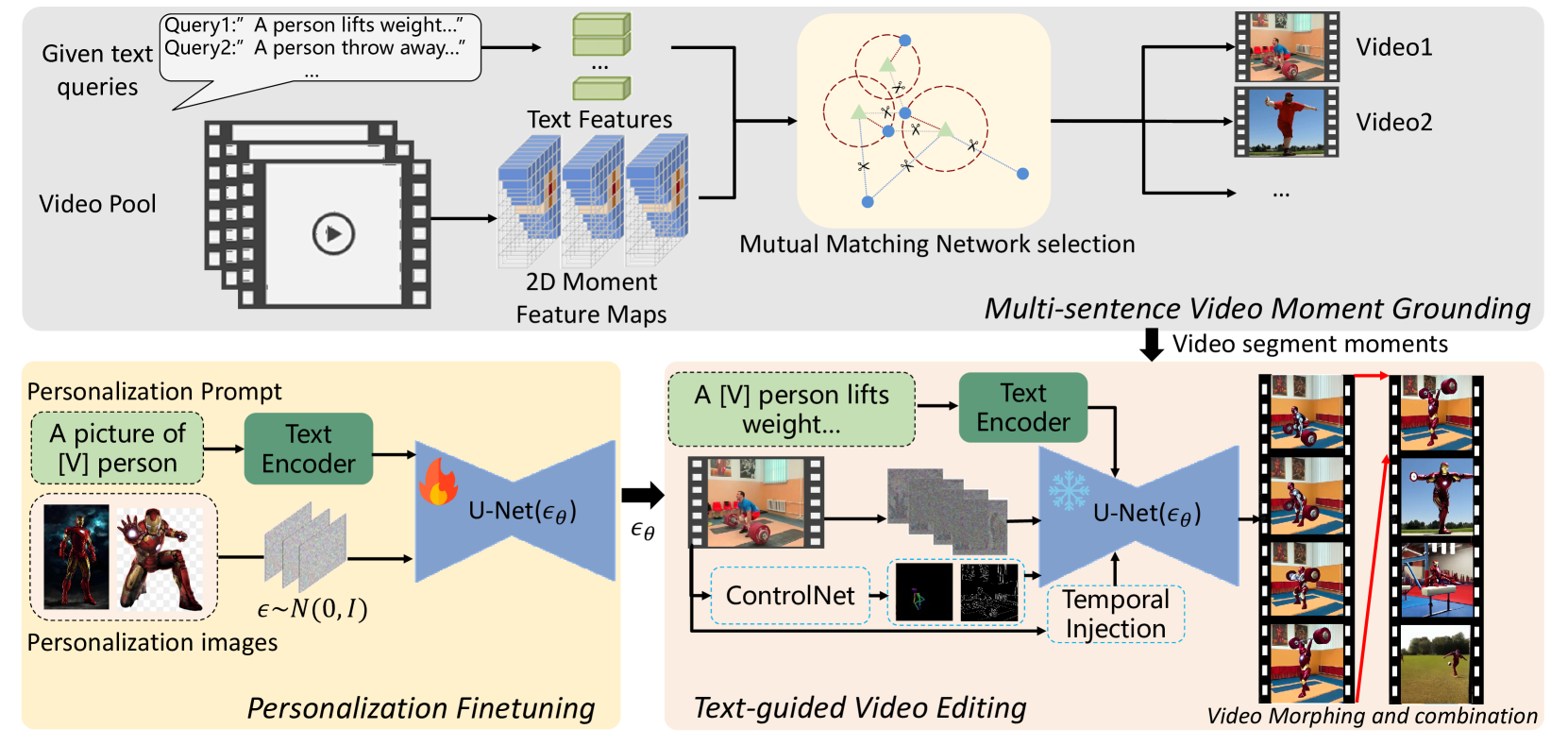
Video generation has witnessed great success recently, but their application in generating long videos still remains challenging due to the difficulty in maintaining the temporal consistency of generated videos and the high memory cost during generation. To tackle the problems, in this paper, we propose a brave and new idea of Multi-sentence Video Grounding for Long Video Generation, connecting the massive video moment retrieval to the video generation task for the first time, providing a new paradigm for long video generation. The method of our work can be summarized as three steps: (i) We design sequential scene text prompts as the queries for video grounding, utilizing the massive video moment retrieval to search for video moment segments that meet the text requirements in the video database. (ii) Based on the source frames of retrieved video moment segments, we adopt video editing methods to create new video content while preserving the temporal consistency of the retrieved video. Since the editing can be conducted segment by segment, and even frame by frame, it largely reduces the memory cost. (iii) We also attempt video morphing and personalized generation methods to improve the subject consistency of long video generation, providing ablation experimental results for the subtasks of long video generation. Our approach seamlessly extends the development in image/video editing, video morphing and personalized generation, and video grounding to the long video generation, offering effective solutions for generating long videos at low memory cost.
Read more7/19/2024

0
Multilingual Synopses of Movie Narratives: A Dataset for Story Understanding
Yidan Sun, Jianfei Yu, Boyang Li
Story video-text alignment, a core task in computational story understanding, aims to align video clips with corresponding sentences in their descriptions. However, progress on the task has been held back by the scarcity of manually annotated video-text correspondence and the heavy concentration on English narrations of Hollywood movies. To address these issues, in this paper, we construct a large-scale multilingual video story dataset named Multilingual Synopses of Movie Narratives (M-SYMON), containing 13,166 movie summary videos from 7 languages, as well as manual annotation of fine-grained video-text correspondences for 101.5 hours of video. Training on the human annotated data from SyMoN outperforms the SOTA methods by 15.7 and 16.2 percentage points on Clip Accuracy and Sentence IoU scores, respectively, demonstrating the effectiveness of the annotations. As benchmarks for future research, we create 6 baseline approaches with different multilingual training strategies, compare their performance in both intra-lingual and cross-lingual setups, exemplifying the challenges of multilingual video-text alignment.
Read more6/21/2024