Synthesizer Sound Matching Using Audio Spectrogram Transformers

0

Sign in to get full access
Overview
- This paper presents a method for synthesizer sound matching using audio spectrogram transformers.
- The proposed approach leverages transformer-based models to match synthesizer sounds to target audio samples.
- Experiments demonstrate the effectiveness of the method in generating synthesizer sounds that closely match target audio.
Plain English Explanation
The paper discusses a technique for creating synthesizer sounds that closely match a target audio sample. Synthesizers are electronic musical instruments that generate sounds, and this research aims to make it easier to produce synthesizer sounds that mimic a desired audio clip.
The key idea is to use transformer machine learning models to analyze the audio spectrogram (a visual representation of the audio frequencies) of the target sound. The transformer model can then generate synthesizer settings that produce a sound matching the target as closely as possible.
This can be useful for things like creating synthetic audio that blends seamlessly with real recordings, or automatically equalizing individual instrument tracks in music production.
Technical Explanation
The paper proposes a method for synthesizer sound matching using transformer-based models that operate on audio spectrograms. The key components are:
-
Audio Spectrogram Extraction: The target audio sample is converted into a spectrogram, which is a visual representation of the audio's frequency content over time.
-
Transformer-based Sound Matching: A transformer model is trained to take the target spectrogram as input and predict the optimal synthesizer parameters (such as oscillator settings, filter cutoffs, etc.) to generate a sound that matches the target as closely as possible.
-
Synthesizer Sound Generation: The predicted synthesizer parameters are used to generate a new audio sample that mimics the target sound.
The experiments show that this approach can generate synthesizer sounds that are perceptually very similar to target audio samples, outperforming previous methods. The transformer model is able to effectively learn the complex relationships between the spectrogram features and the required synthesizer settings.
Critical Analysis
The paper presents a novel and promising approach for synthesizer sound matching. However, some potential limitations and areas for future research are:
- The experiments were conducted on a relatively small dataset of synthesizer sounds, so further testing on larger and more diverse audio samples would be valuable.
- The method assumes the availability of target audio samples to match against. In many real-world scenarios, users may want to create new synthesizer sounds without having a specific target in mind.
- While the perceptual similarity of the generated sounds is evaluated, objective metrics like audio fidelity or human preference could provide additional useful insights.
- Exploring ways to incorporate user feedback or interactive refinement of the synthesizer settings could make the system more user-friendly.
Overall, this research represents an exciting step forward in using advanced machine learning techniques to enhance synthesizer sound design and music production workflows.
Conclusion
This paper presents a novel method for synthesizer sound matching using transformer-based models that operate on audio spectrograms. The proposed approach demonstrates the ability to generate synthesizer sounds that closely match target audio samples, with potential applications in areas like music production, sound design, and audio-visual content creation. While further research is needed to address some limitations, this work highlights the promise of using powerful machine learning models to enhance and streamline the creative process of electronic music synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Synthesizer Sound Matching Using Audio Spectrogram Transformers
Fred Bruford, Frederik Blang, Shahan Nercessian
Systems for synthesizer sound matching, which automatically set the parameters of a synthesizer to emulate an input sound, have the potential to make the process of synthesizer programming faster and easier for novice and experienced musicians alike, whilst also affording new means of interaction with synthesizers. Considering the enormous variety of synthesizers in the marketplace, and the complexity of many of them, general-purpose sound matching systems that function with minimal knowledge or prior assumptions about the underlying synthesis architecture are particularly desirable. With this in mind, we introduce a synthesizer sound matching model based on the Audio Spectrogram Transformer. We demonstrate the viability of this model by training on a large synthetic dataset of randomly generated samples from the popular Massive synthesizer. We show that this model can reconstruct parameters of samples generated from a set of 16 parameters, highlighting its improved fidelity relative to multi-layer perceptron and convolutional neural network baselines. We also provide audio examples demonstrating the out-of-domain model performance in emulating vocal imitations, and sounds from other synthesizers and musical instruments.
Read more7/24/2024
0
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
Read more6/11/2024
0
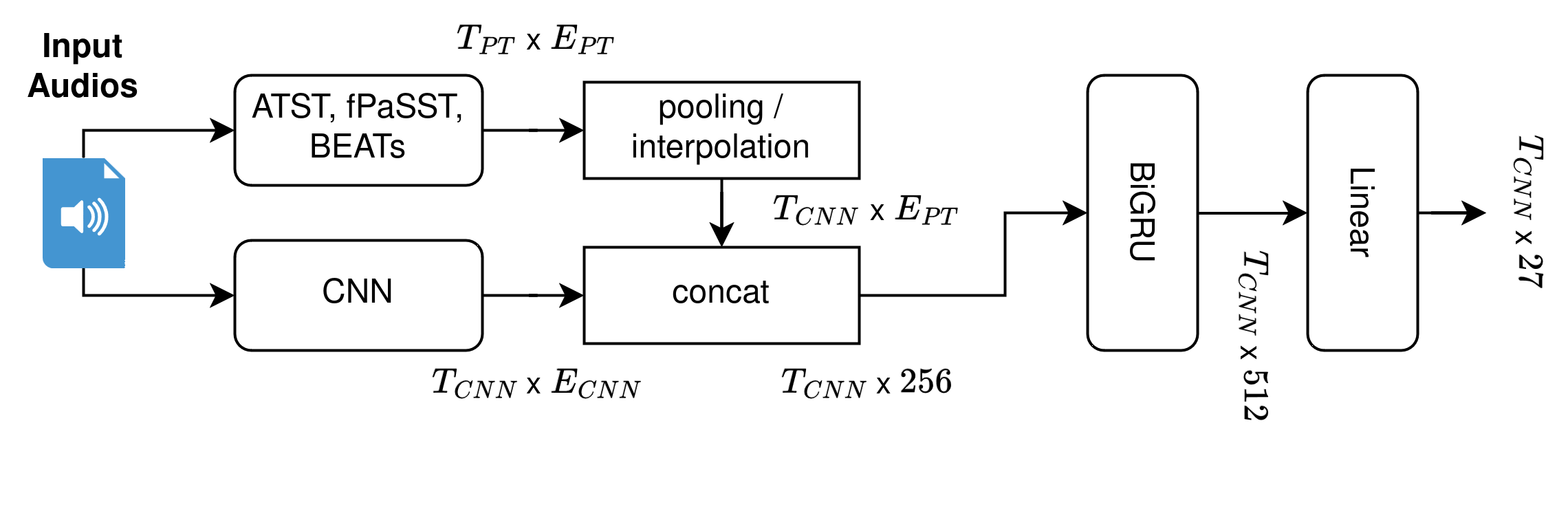
Improving Audio Spectrogram Transformers for Sound Event Detection Through Multi-Stage Training
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, Gerhard Widmer
This technical report describes the CP-JKU team's submission for Task 4 Sound Event Detection with Heterogeneous Training Datasets and Potentially Missing Labels of the DCASE 24 Challenge. We fine-tune three large Audio Spectrogram Transformers, PaSST, BEATs, and ATST, on the joint DESED and MAESTRO datasets in a two-stage training procedure. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the large pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of all three fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, boosting single-model performance substantially. Additionally, we pre-train PaSST and ATST on the subset of AudioSet that comes with strong temporal labels, before fine-tuning them on the Task 4 datasets.
Read more8/6/2024

0
Creative Text-to-Audio Generation via Synthesizer Programming
Manuel Cherep, Nikhil Singh, Jessica Shand
Neural audio synthesis methods now allow specifying ideas in natural language. However, these methods produce results that cannot be easily tweaked, as they are based on large latent spaces and up to billions of uninterpretable parameters. We propose a text-to-audio generation method that leverages a virtual modular sound synthesizer with only 78 parameters. Synthesizers have long been used by skilled sound designers for media like music and film due to their flexibility and intuitive controls. Our method, CTAG, iteratively updates a synthesizer's parameters to produce high-quality audio renderings of text prompts that can be easily inspected and tweaked. Sounds produced this way are also more abstract, capturing essential conceptual features over fine-grained acoustic details, akin to how simple sketches can vividly convey visual concepts. Our results show how CTAG produces sounds that are distinctive, perceived as artistic, and yet similarly identifiable to recent neural audio synthesis models, positioning it as a valuable and complementary tool.
Read more6/4/2024