Images that Sound: Composing Images and Sounds on a Single Canvas
2405.12221
0
0

Abstract
Spectrograms are 2D representations of sound that look very different from the images found in our visual world. And natural images, when played as spectrograms, make unnatural sounds. In this paper, we show that it is possible to synthesize spectrograms that simultaneously look like natural images and sound like natural audio. We call these spectrograms images that sound. Our approach is simple and zero-shot, and it leverages pre-trained text-to-image and text-to-spectrogram diffusion models that operate in a shared latent space. During the reverse process, we denoise noisy latents with both the audio and image diffusion models in parallel, resulting in a sample that is likely under both models. Through quantitative evaluations and perceptual studies, we find that our method successfully generates spectrograms that align with a desired audio prompt while also taking the visual appearance of a desired image prompt. Please see our project page for video results: https://ificl.github.io/images-that-sound/
Create account to get full access
Overview
- This paper presents a novel technique for composing and synchronizing visual and audio content on a single canvas.
- The authors introduce a system that allows users to create "Images that Sound" - dynamic visual artworks that are directly coupled with synchronized audio.
- The system enables artists and creators to seamlessly blend static and animated imagery with generative sound, resulting in expressive multimedia experiences.
Plain English Explanation
The paper describes a new way to create multimedia artworks that combine visuals and sound. The key idea is to have a single digital canvas where you can compose both static images and animated visuals, and then directly link that visual content to synchronized, generative audio.
This means artists can create dynamic visual artworks that "come alive" with sound - for example, a still image that subtly shifts and evolves as an accompanying soundscape plays. Or an abstract animation that has its movements and changes directly reflected in the generated audio.
The system allows for a very tight coupling between the visual and audio elements, so they can be tightly integrated and responsive to each other. This gives creators a powerful new medium to explore and express their ideas through the unique combination of sight and sound.
Technical Explanation
The paper introduces a novel framework for composing images and sounds on a single canvas. The core innovation is a system that enables users to directly link visual elements (both static and animated) with generative audio content.
The authors developed a web-based tool that provides a unified canvas for creating these "Images that Sound". Users can import or generate visual assets, and then associate them with parametric sound models. The system automatically synchronizes the visuals and audio in real-time, allowing creators to fine-tune the interactions between the two modalities.
Key technical aspects include:
- A modular architecture that separates the visual, audio, and synchronization components
- Techniques for mapping visual parameters (e.g. position, size, color) to audio synthesis
- Algorithms for adjusting the audio in response to dynamic visual changes
- Optimization methods to ensure smooth, low-latency performance
Through a series of creative use cases and user studies, the authors demonstrate the expressive potential of this audio-visual composition system. They show how it enables new forms of interactive digital art, immersive multimedia experiences, and novel interfaces for music creation.
Critical Analysis
The paper presents a compelling and technically robust system for bridging the gap between visual and audio media. The ability to tightly couple these modalities opens up exciting new creative possibilities, as evidenced by the diverse examples showcased.
However, the authors acknowledge some limitations of the current implementation. For instance, the audio synthesis is limited to parametric models, which may not capture the full richness and complexity of real-world sounds. Expanding the system to support more advanced audio-driven image generation or audio-editing capabilities could further enhance its creative potential.
Additionally, the paper focuses primarily on the technical aspects and user experiences, but does not delve deeply into the broader societal or artistic implications of this technology. As "Images that Sound" become more prevalent, it will be important to consider issues around accessibility, cultural representation, and the evolving role of digital art.
Overall, this work represents a significant advance in the field of audio-visual synthesis and interaction. The authors have demonstrated a compelling proof-of-concept that, with further development and research, could have a transformative impact on creative expression and multimedia experiences.
Conclusion
This paper introduces a novel framework for "Images that Sound" - a system that enables the seamless composition and synchronization of visual and audio content on a single digital canvas. By tightly coupling these two modalities, the authors have opened up new creative possibilities for artists, musicians, and multimedia designers.
The technical innovations, such as the modular architecture and techniques for mapping visuals to audio, represent a significant advance in the field of audio-visual synthesis and interaction. Through a range of use cases and user studies, the authors have demonstrated the expressive potential of this technology, paving the way for the development of more immersive, responsive, and integrated multimedia experiences.
While the current system has some limitations, the core concept of "Images that Sound" holds great promise. As the technology continues to evolve, it will be important to consider the broader social and artistic implications, ensuring that this medium is accessible, representative, and truly transformative for the creative community and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
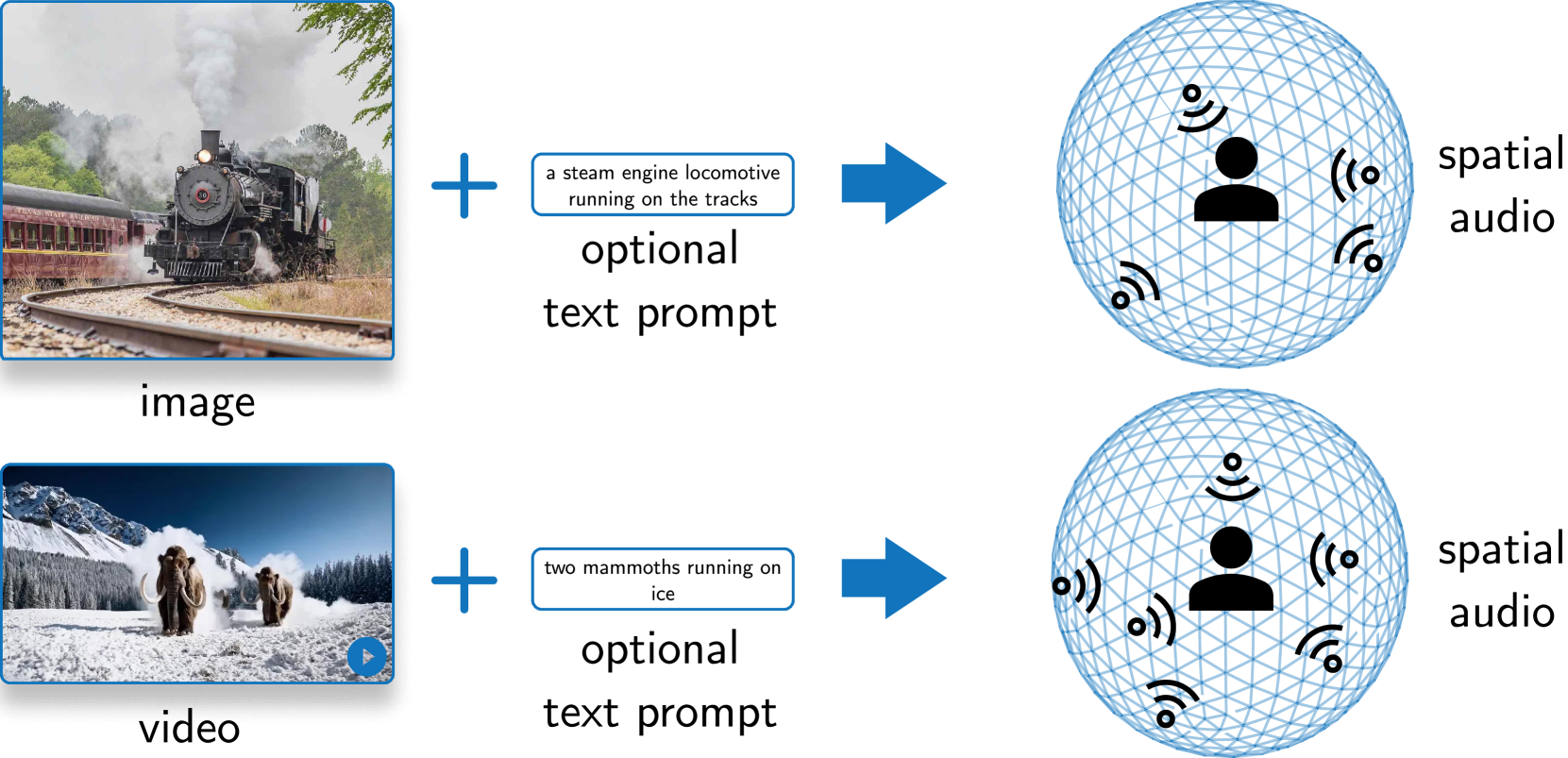
SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Rishit Dagli, Shivesh Prakash, Robert Wu, Houman Khosravani
0
0
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
6/12/2024
Visual Echoes: A Simple Unified Transformer for Audio-Visual Generation
Shiqi Yang, Zhi Zhong, Mengjie Zhao, Shusuke Takahashi, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
0
0
In recent years, with the realistic generation results and a wide range of personalized applications, diffusion-based generative models gain huge attention in both visual and audio generation areas. Compared to the considerable advancements of text2image or text2audio generation, research in audio2visual or visual2audio generation has been relatively slow. The recent audio-visual generation methods usually resort to huge large language model or composable diffusion models. Instead of designing another giant model for audio-visual generation, in this paper we take a step back showing a simple and lightweight generative transformer, which is not fully investigated in multi-modal generation, can achieve excellent results on image2audio generation. The transformer operates in the discrete audio and visual Vector-Quantized GAN space, and is trained in the mask denoising manner. After training, the classifier-free guidance could be deployed off-the-shelf achieving better performance, without any extra training or modification. Since the transformer model is modality symmetrical, it could also be directly deployed for audio2image generation and co-generation. In the experiments, we show that our simple method surpasses recent image2audio generation methods. Generated audio samples can be found at https://docs.google.com/presentation/d/1ZtC0SeblKkut4XJcRaDsSTuCRIXB3ypxmSi7HTY3IyQ/
5/27/2024
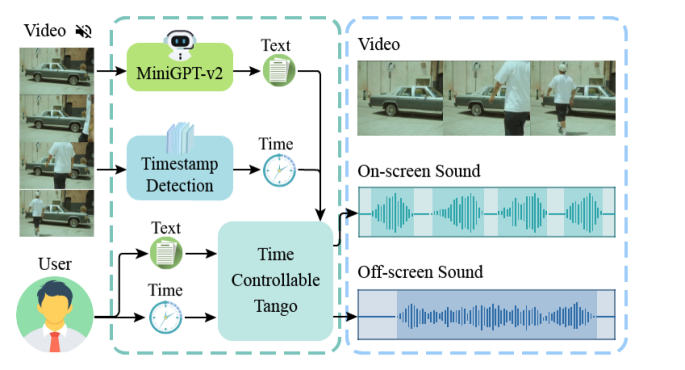
SonicVisionLM: Playing Sound with Vision Language Models
Zhifeng Xie, Shengye Yu, Qile He, Mengtian Li
0
0
There has been a growing interest in the task of generating sound for silent videos, primarily because of its practicality in streamlining video post-production. However, existing methods for video-sound generation attempt to directly create sound from visual representations, which can be challenging due to the difficulty of aligning visual representations with audio representations. In this paper, we present SonicVisionLM, a novel framework aimed at generating a wide range of sound effects by leveraging vision-language models(VLMs). Instead of generating audio directly from video, we use the capabilities of powerful VLMs. When provided with a silent video, our approach first identifies events within the video using a VLM to suggest possible sounds that match the video content. This shift in approach transforms the challenging task of aligning image and audio into more well-studied sub-problems of aligning image-to-text and text-to-audio through the popular diffusion models. To improve the quality of audio recommendations with LLMs, we have collected an extensive dataset that maps text descriptions to specific sound effects and developed a time-controlled audio adapter. Our approach surpasses current state-of-the-art methods for converting video to audio, enhancing synchronization with the visuals, and improving alignment between audio and video components. Project page: https://yusiissy.github.io/SonicVisionLM.github.io/
4/4/2024
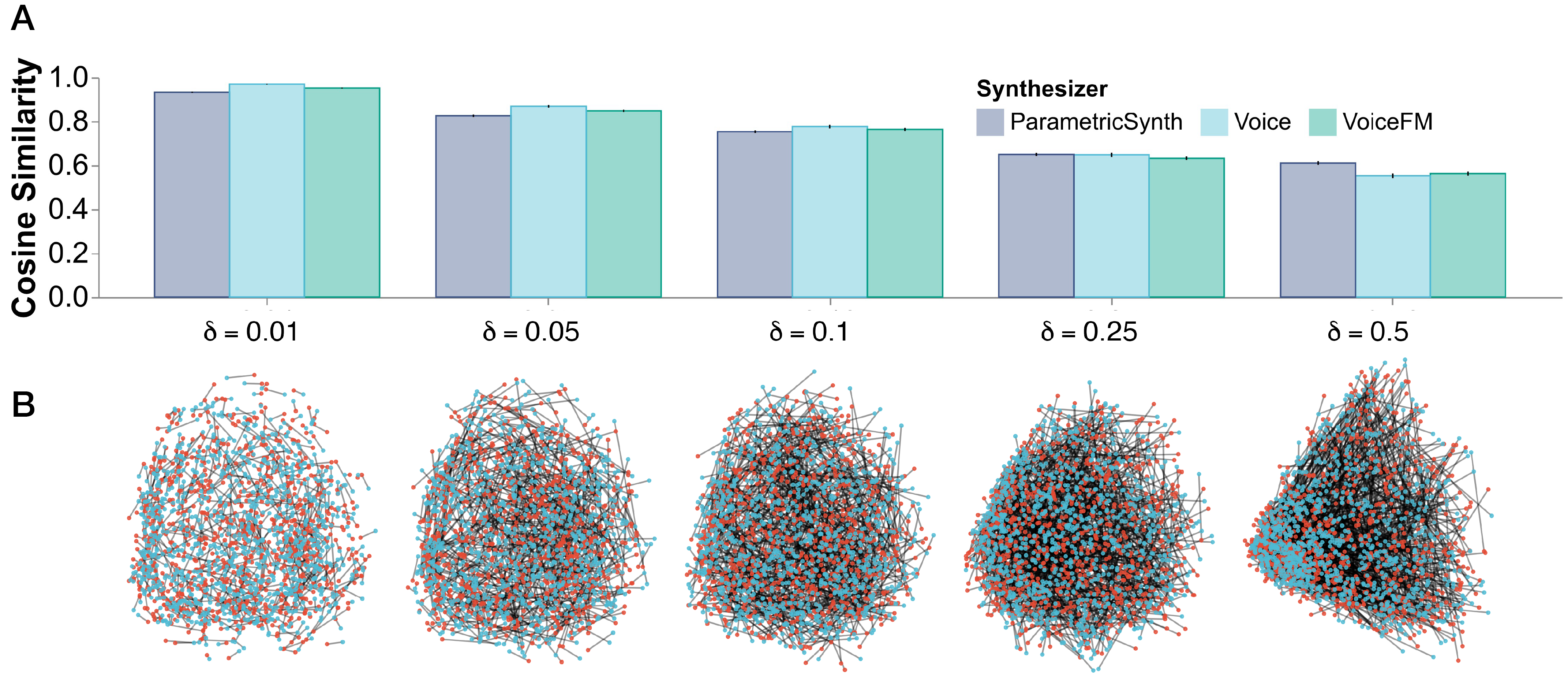
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
0
0
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
6/11/2024