Synthetic Oversampling: Theory and A Practical Approach Using LLMs to Address Data Imbalance

0
📊
Sign in to get full access
Overview
- Imbalanced data and spurious correlations are common challenges in machine learning and data science
- Oversampling, which artificially increases the number of instances in the underrepresented classes, is a widely adopted approach to tackle these challenges
- The paper introduces OPAL (Oversampling with Artificial LLM-generated data), a systematic oversampling approach that leverages large language models (LLMs) to generate high-quality synthetic data for minority groups
Plain English Explanation
Machine learning and data science often deal with datasets that are imbalanced - meaning some categories or classes have many more examples than others. This can lead to spurious correlations where the model picks up on patterns that don't actually reflect real-world relationships.
To address this, researchers often use a technique called oversampling, which artificially increases the number of examples in the underrepresented classes. This helps the model learn the important features of those classes more effectively.
The paper introduces a new oversampling approach called OPAL that uses large language models (LLMs) to generate high-quality synthetic data for the minority classes. Unlike previous work on synthetic data generation which has focused on improving prediction tasks, OPAL specifically targets the challenges of imbalanced data and spurious correlations.
The researchers develop a novel theory to show how the synthetic data generated by transformers can provide significant benefits for these problems. They also conduct extensive experiments to demonstrate the effectiveness of OPAL compared to alternative solutions.
Technical Explanation
The core idea behind OPAL is to leverage the powerful capabilities of large language models (LLMs) to generate high-quality synthetic data for the minority classes in an imbalanced dataset. This synthetic data is then combined with the original data to train the machine learning model.
The key innovations of OPAL are:
-
Systematic Approach: OPAL provides a systematic framework for incorporating the synthetic data generated by LLMs into the oversampling process, rather than just using the LLM output directly.
-
Theoretical Guarantees: The authors develop a novel theoretical analysis that rigorously characterizes the benefits of using the synthetic data generated by LLMs. This includes showing the capacity of transformers to generate high-quality synthetic data for both labels and covariates.
-
Empirical Validation: The researchers conduct extensive numerical experiments to demonstrate the efficacy of OPAL compared to alternative oversampling approaches, such as SMOTE and Synthetic Augmentation.
The OPAL framework involves several key steps:
- Pretrain an LLM on a large corpus of relevant data.
- Fine-tune the LLM on the minority class examples in the imbalanced dataset.
- Use the fine-tuned LLM to generate synthetic examples for the minority classes.
- Combine the synthetic data with the original dataset and use this augmented dataset to train the final machine learning model.
Critical Analysis
The paper provides a compelling approach to addressing the important challenges of imbalanced data and spurious correlations in machine learning. The use of LLMs to generate high-quality synthetic data is a novel and promising direction.
However, the paper does not fully explore the limitations and potential issues with this approach. For example, the authors do not discuss the computational and memory requirements of the LLM pretraining and fine-tuning steps, which could be significant barriers to practical deployment.
Additionally, the theoretical analysis focuses on the capacity of transformers to generate high-quality synthetic data, but does not delve into potential biases or artifacts that could be introduced by the LLM. Further research is needed to understand the robustness and reliability of the synthetic data generated by this approach.
Overall, the OPAL framework represents an important step forward in leveraging the power of LLMs to address fundamental challenges in machine learning. However, there are still many avenues for further exploration and refinement of this approach.
Conclusion
The paper introduces OPAL, a novel oversampling approach that uses large language models to generate high-quality synthetic data for minority classes in imbalanced datasets. This addresses two key challenges in machine learning and data science: imbalanced data and spurious correlations.
The researchers develop a rigorous theoretical framework to characterize the benefits of using the synthetic data, and demonstrate the effectiveness of OPAL through extensive numerical experiments. While the paper represents an important advance in this area, there are still opportunities for further research to address the limitations and potential issues with this approach.
Overall, the OPAL framework showcases the potential of leveraging powerful language models to tackle fundamental problems in machine learning and data science. As the field continues to evolve, techniques like OPAL will play an increasingly important role in building robust and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Synthetic Oversampling: Theory and A Practical Approach Using LLMs to Address Data Imbalance
Ryumei Nakada, Yichen Xu, Lexin Li, Linjun Zhang
Imbalanced data and spurious correlations are common challenges in machine learning and data science. Oversampling, which artificially increases the number of instances in the underrepresented classes, has been widely adopted to tackle these challenges. In this article, we introduce OPAL (textbf{O}versamtextbf{P}ling with textbf{A}rtificial textbf{L}LM-generated data), a systematic oversampling approach that leverages the capabilities of large language models (LLMs) to generate high-quality synthetic data for minority groups. Recent studies on synthetic data generation using deep generative models mostly target prediction tasks. Our proposal differs in that we focus on handling imbalanced data and spurious correlations. More importantly, we develop a novel theory that rigorously characterizes the benefits of using the synthetic data, and shows the capacity of transformers in generating high-quality synthetic data for both labels and covariates. We further conduct intensive numerical experiments to demonstrate the efficacy of our proposed approach compared to some representative alternative solutions.
Read more6/7/2024

0
Synthetic Tabular Data Generation for Class Imbalance and Fairness: A Comparative Study
Emmanouil Panagiotou, Arjun Roy, Eirini Ntoutsi
Due to their data-driven nature, Machine Learning (ML) models are susceptible to bias inherited from data, especially in classification problems where class and group imbalances are prevalent. Class imbalance (in the classification target) and group imbalance (in protected attributes like sex or race) can undermine both ML utility and fairness. Although class and group imbalances commonly coincide in real-world tabular datasets, limited methods address this scenario. While most methods use oversampling techniques, like interpolation, to mitigate imbalances, recent advancements in synthetic tabular data generation offer promise but have not been adequately explored for this purpose. To this end, this paper conducts a comparative analysis to address class and group imbalances using state-of-the-art models for synthetic tabular data generation and various sampling strategies. Experimental results on four datasets, demonstrate the effectiveness of generative models for bias mitigation, creating opportunities for further exploration in this direction.
Read more9/10/2024
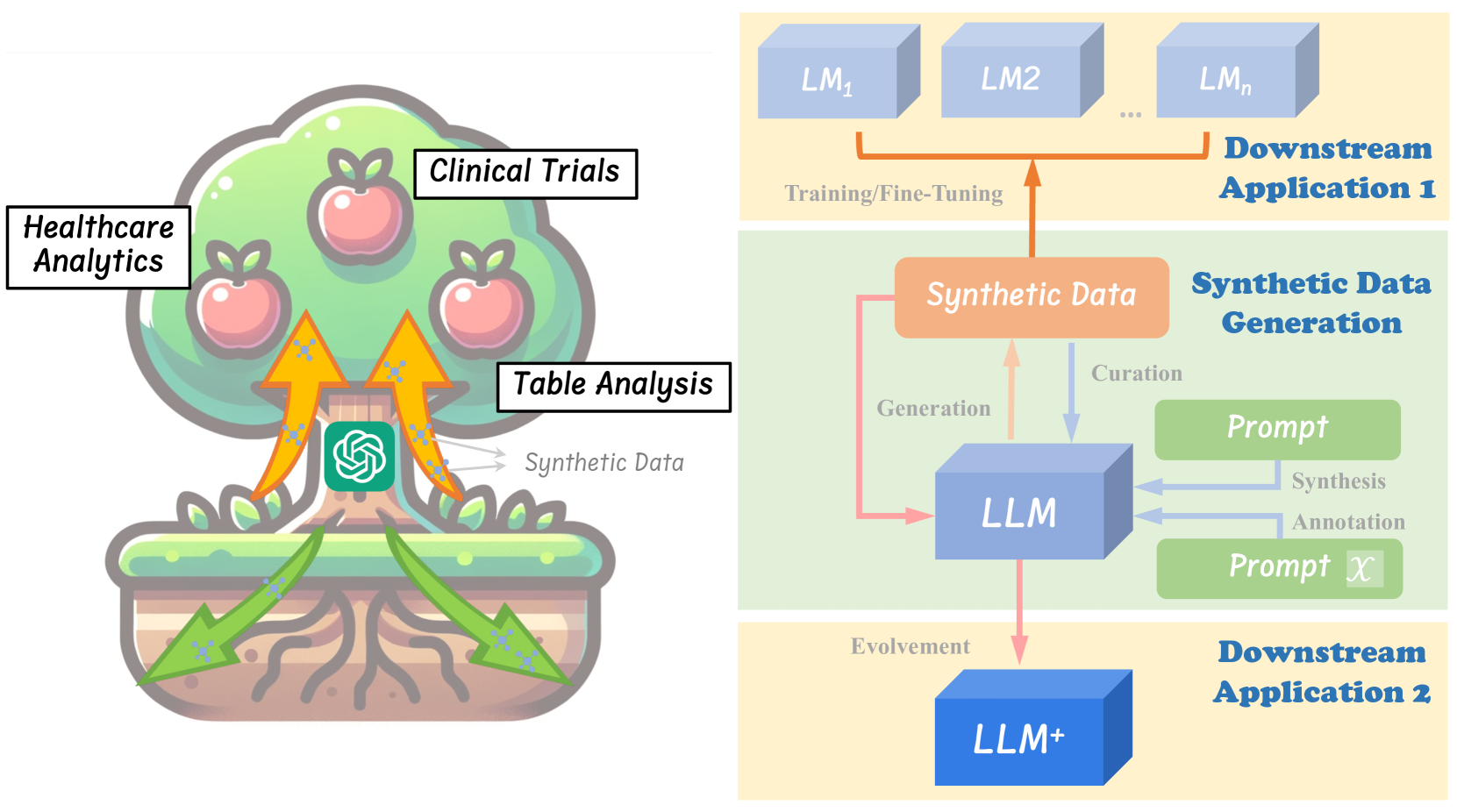
0
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024
📊
0
SYNAuG: Exploiting Synthetic Data for Data Imbalance Problems
Moon Ye-Bin, Nam Hyeon-Woo, Wonseok Choi, Nayeong Kim, Suha Kwak, Tae-Hyun Oh
Data imbalance in training data often leads to biased predictions from trained models, which in turn causes ethical and social issues. A straightforward solution is to carefully curate training data, but given the enormous scale of modern neural networks, this is prohibitively labor-intensive and thus impractical. Inspired by recent developments in generative models, this paper explores the potential of synthetic data to address the data imbalance problem. To be specific, our method, dubbed SYNAuG, leverages synthetic data to equalize the unbalanced distribution of training data. Our experiments demonstrate that, although a domain gap between real and synthetic data exists, training with SYNAuG followed by fine-tuning with a few real samples allows to achieve impressive performance on diverse tasks with different data imbalance issues, surpassing existing task-specific methods for the same purpose.
Read more4/26/2024