SynthVLM: High-Efficiency and High-Quality Synthetic Data for Vision Language Models

0

Sign in to get full access
Overview
- SynthVLM is a novel approach for generating high-quality, high-efficiency synthetic data to train vision-language models.
- It leverages large language models and 3D rendering to create diverse, realistic image-caption pairs that can boost the performance of these models.
- The key innovations include efficient synthetic data generation and robust distillation techniques to transfer knowledge from large models to smaller ones.
Plain English Explanation
The paper introduces SynthVLM, a new way to create synthetic data for training vision-language models. These models are used for tasks like image captioning, where the AI system describes the contents of an image using natural language.
The researchers found that by combining powerful language models with 3D rendering techniques, they could generate a large number of realistic image-caption pairs. This synthetic data can then be used to train the vision-language models, boosting their performance on real-world tasks.
The key advantages of SynthVLM are its efficiency and high-quality. The researchers developed techniques to streamline the data generation process, allowing them to create vast amounts of training data quickly and cost-effectively. At the same time, the synthetic data closely matches the characteristics of real-world data, ensuring the models learn meaningful representations.
By leveraging this synthetic data, the researchers were able to significantly improve the performance of vision-language models compared to using only real-world data for training. This suggests that SynthVLM could be a powerful tool for advancing the capabilities of these important AI systems.
Technical Explanation
The SynthVLM paper proposes a novel approach for generating high-quality, high-efficiency synthetic data to train vision-language models. The key innovations include:
-
Efficient Synthetic Data Generation: The researchers developed techniques to rapidly create diverse, realistic image-caption pairs using large language models and 3D rendering. This allows for the generation of vast amounts of training data quickly and cost-effectively.
-
Robust Distillation: The researchers used knowledge distillation to efficiently transfer the learned representations from large, powerful vision-language models to smaller, more practical models. This helps to preserve the benefits of the synthetic data while enabling deployment on resource-constrained devices.
-
Careful Design of Rendering and Language Components: The researchers paid close attention to the design of the 3D rendering and language generation components to ensure the synthetic data closely matches the characteristics of real-world data. This helps the models learn meaningful representations that transfer well to real-world tasks.
Through extensive experiments, the researchers demonstrated that their SynthVLM approach can significantly boost the performance of vision-language models compared to training on real-world data alone. This suggests that synthetic data generation could be a powerful tool for advancing the capabilities of these important AI systems.
Critical Analysis
The SynthVLM paper presents a promising approach for leveraging synthetic data to improve vision-language models. However, there are a few potential caveats and limitations to consider:
-
Generalization to Real-World Domains: While the researchers demonstrate the effectiveness of SynthVLM on standard benchmarks, it's unclear how well the synthetic data will generalize to more diverse, real-world domains. Further evaluation on a broader range of tasks and datasets would be valuable.
-
Scalability and Deployment: The paper focuses on the efficiency of the data generation process, but the computational and storage requirements for deploying these models in practical settings may still be challenging, especially for resource-constrained devices.
-
Ethical Considerations: The use of synthetic data raises potential ethical concerns, such as the risk of introducing biases or the potential for misuse. The researchers should consider addressing these issues more explicitly in their work.
Despite these caveats, the SynthVLM paper represents an important step forward in leveraging synthetic data to enhance the capabilities of vision-language models. Further research and careful consideration of the limitations will be crucial for realizing the full potential of this approach.
Conclusion
The SynthVLM paper introduces a novel approach for generating high-quality, high-efficiency synthetic data to train vision-language models. By combining large language models and 3D rendering, the researchers were able to create diverse, realistic image-caption pairs that significantly boosted the performance of these AI systems.
The key innovations include efficient synthetic data generation and robust distillation techniques to transfer knowledge from large models to smaller, more practical ones. While there are some caveats and limitations to consider, the SynthVLM approach represents an important step forward in leveraging synthetic data to advance the capabilities of vision-language models, with potential implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SynthVLM: High-Efficiency and High-Quality Synthetic Data for Vision Language Models
Zheng Liu, Hao Liang, Xijie Huang, Wentao Xiong, Qinhan Yu, Linzhuang Sun, Chong Chen, Conghui He, Bin Cui, Wentao Zhang
Recently, with the rise of web images, managing and understanding large-scale image datasets has become increasingly important. Vision Large Language Models (VLLMs) have recently emerged due to their robust vision-understanding capabilities. However, training these models requires vast amounts of data, posing challenges to efficiency, effectiveness, data quality, and privacy. In this paper, we introduce SynthVLM, a novel data synthesis pipeline for VLLMs. Unlike existing methods that generate captions from images, SynthVLM employs advanced diffusion models and high-quality captions to automatically generate and select high-resolution images from captions, creating precisely aligned image-text pairs. Leveraging these pairs, we achieve state-of-the-art (SoTA) performance on various vision question answering tasks, maintaining high alignment quality and preserving advanced language abilities. Moreover, SynthVLM surpasses traditional GPT-4 Vision-based caption generation methods in performance while significantly reducing computational overhead. Crucially, our method's reliance on purely generated data ensures the preservation of privacy, achieving SoTA performance with just 100k data points (only 18% of the official dataset size).
Read more8/13/2024
0
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
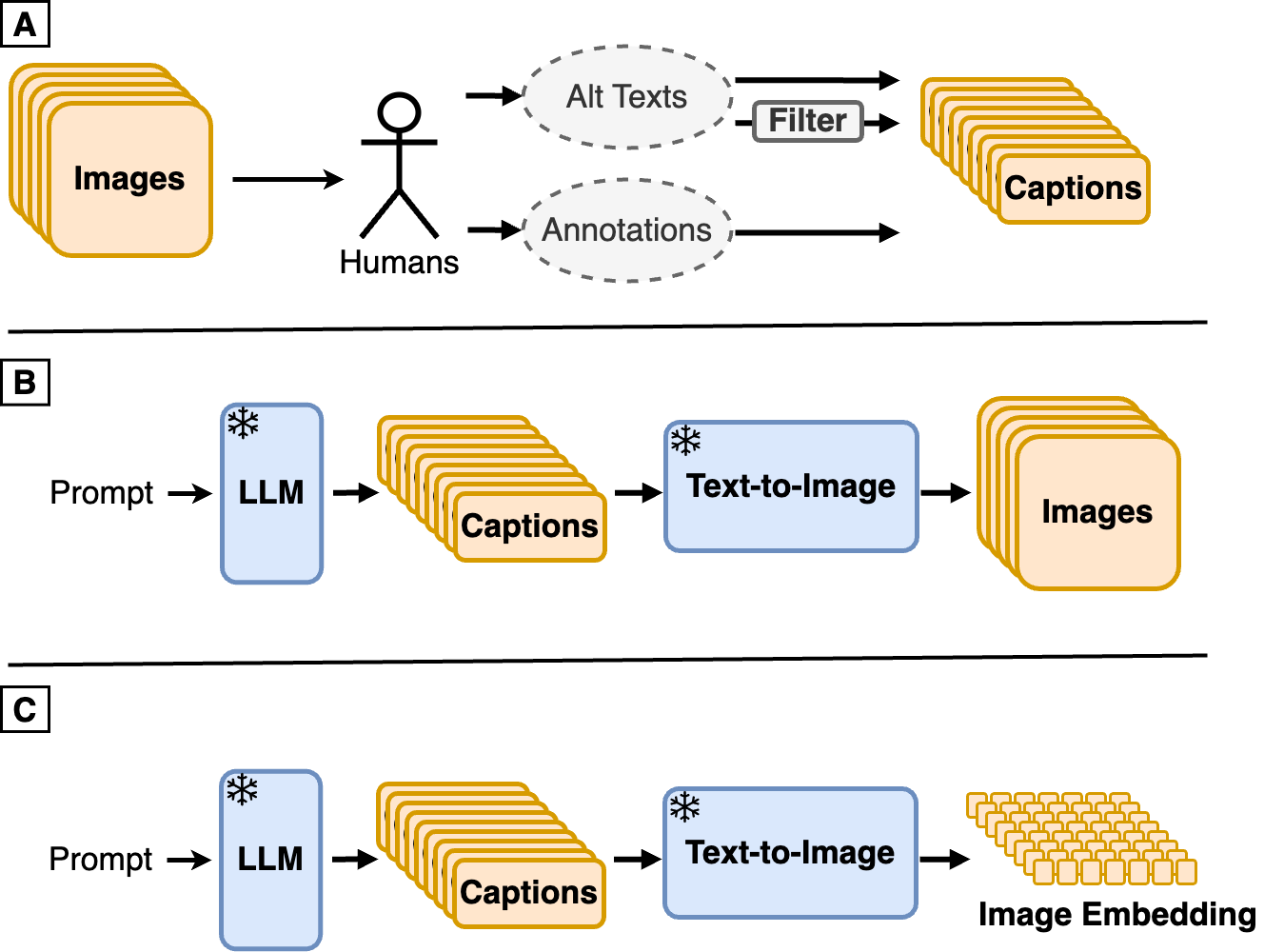
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
Read more6/10/2024
📊
0
ALLaVA: Harnessing GPT4V-Synthesized Data for Lite Vision-Language Models
Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, Benyou Wang
Large vision-language models (LVLMs) have shown premise in a broad range of vision-language tasks with their strong reasoning and generalization capabilities. However, they require considerable computational resources for training and deployment. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To this end, we propose a comprehensive pipeline for generating a synthetic dataset. The key idea is to leverage strong proprietary models to generate (i) fine-grained image annotations for vision-language alignment and (ii) complex reasoning visual question-answering pairs for visual instruction fine-tuning, yielding 1.3M samples in total. We train a series of lite VLMs on the synthetic dataset and experimental results demonstrate the effectiveness of the proposed scheme, where they achieve competitive performance on 17 benchmarks among 4B LVLMs, and even perform on par with 7B/13B-scale models on various benchmarks. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. We name our dataset textit{ALLaVA}, and open-source it to research community for developing better resource-efficient LVLMs for wider usage.
Read more6/18/2024
0
Harnessing the Power of Large Vision Language Models for Synthetic Image Detection
Mamadou Keita, Wassim Hamidouche, Hassen Bougueffa, Abdenour Hadid, Abdelmalik Taleb-Ahmed
In recent years, the emergence of models capable of generating images from text has attracted considerable interest, offering the possibility of creating realistic images from text descriptions. Yet these advances have also raised concerns about the potential misuse of these images, including the creation of misleading content such as fake news and propaganda. This study investigates the effectiveness of using advanced vision-language models (VLMs) for synthetic image identification. Specifically, the focus is on tuning state-of-the-art image captioning models for synthetic image detection. By harnessing the robust understanding capabilities of large VLMs, the aim is to distinguish authentic images from synthetic images produced by diffusion-based models. This study contributes to the advancement of synthetic image detection by exploiting the capabilities of visual language models such as BLIP-2 and ViTGPT2. By tailoring image captioning models, we address the challenges associated with the potential misuse of synthetic images in real-world applications. Results described in this paper highlight the promising role of VLMs in the field of synthetic image detection, outperforming conventional image-based detection techniques. Code and models can be found at https://github.com/Mamadou-Keita/VLM-DETECT.
Read more4/4/2024