T-CLAP: Temporal-Enhanced Contrastive Language-Audio Pretraining
2404.17806
0
0
Abstract
Contrastive language-audio pretraining~(CLAP) has been developed to align the representations of audio and language, achieving remarkable performance in retrieval and classification tasks. However, current CLAP struggles to capture temporal information within audio and text features, presenting substantial limitations for tasks such as audio retrieval and generation. To address this gap, we introduce T-CLAP, a temporal-enhanced CLAP model. We use Large Language Models~(LLMs) and mixed-up strategies to generate temporal-contrastive captions for audio clips from extensive audio-text datasets. Subsequently, a new temporal-focused contrastive loss is designed to fine-tune the CLAP model by incorporating these synthetic data. We conduct comprehensive experiments and analysis in multiple downstream tasks. T-CLAP shows improved capability in capturing the temporal relationship of sound events and outperforms state-of-the-art models by a significant margin.
Create account to get full access
Overview
- Introduces a new approach called Temporal-Enhanced Contrastive Language-Audio Pretraining (T-CLAP) that aims to improve upon existing contrastive language-audio models
- Key innovations include incorporating temporal information and decoupling content from style
- Evaluates T-CLAP on various multimodal tasks, showing improved performance over previous state-of-the-art methods
Plain English Explanation
The paper introduces a new way to train AI models that can understand and work with both language and audio data together. It builds on previous work like CLAP and CACOPHONY, but adds some key improvements.
The key ideas are:
-
Incorporating Temporal Information: The model doesn't just look at the language and audio at one point in time, but also considers how they change over time. This helps the model better understand the dynamic relationships between the two.
-
Decoupling Content from Style: The model tries to separate the actual content (what's being said/played) from the style (how it's being said/played). This allows the model to focus on the important semantic information rather than getting distracted by superficial details.
By incorporating these innovations, the researchers show that their T-CLAP model outperforms previous state-of-the-art language-audio models on a variety of benchmark tasks. This suggests their approach is a promising direction for building AI systems that can understand and reason about multimodal data more effectively.
Technical Explanation
The paper introduces a new model called Temporal-Enhanced Contrastive Language-Audio Pretraining (T-CLAP) that builds on the CLAP architecture. The key innovations are:
-
Temporal Modeling: T-CLAP incorporates temporal information by using a bidirectional transformer to encode the sequential nature of the language and audio inputs. This allows the model to capture the dynamic relationships between the modalities over time.
-
Decoupling Content and Style: Similar to CLAP, T-CLAP uses a contrastive learning objective to separate the content (what's being said/played) from the style (how it's being said/played). This helps the model focus on the semantic information rather than superficial details.
The model is pretrained on a large corpus of paired language-audio data using a multitask objective that combines the CLAP-style contrastive loss with a temporal prediction task. This encourages the model to learn robust multimodal representations that capture both the content and temporal dynamics of the input.
The researchers evaluate T-CLAP on a variety of downstream tasks, including audio-visual zero-shot learning, video captioning, and audio-text retrieval. They show that T-CLAP outperforms previous state-of-the-art models like CACOPHONY and CLAM-TTS, demonstrating the benefits of their temporal-enhanced and content-style decoupling approach.
Critical Analysis
The paper presents a compelling approach to improving language-audio multimodal models, but there are a few potential limitations and areas for further research:
-
Dataset Bias: The researchers use a large corpus of internet-crawled language-audio data for pretraining. While this provides a diverse set of examples, it may also introduce biases that could affect the model's performance on specific tasks or domains.
-
Scalability: The T-CLAP model is relatively complex, with the bidirectional transformer and additional content-style decoupling components. This could make it computationally expensive to train and deploy, especially for resource-constrained applications.
-
Interpretability: As with many deep learning models, it may be challenging to fully understand the internal representations and decision-making processes of T-CLAP. This could limit its interpretability and make it harder to diagnose and correct potential issues.
-
Generalization: While the model shows strong performance on the evaluated tasks, it would be valuable to test its generalization to a wider range of multimodal applications, especially those involving more complex language and audio interactions.
Overall, the T-CLAP approach is a promising step forward in multimodal language-audio modeling, but further research is needed to address these potential limitations and explore the model's broader applicability.
Conclusion
The T-CLAP paper introduces a novel approach to contrastive language-audio pretraining that incorporates temporal information and decouples content from style. The key innovations lead to improved performance on a variety of multimodal tasks compared to previous state-of-the-art methods.
This work represents an important advancement in the field of multimodal AI, demonstrating the value of leveraging both language and audio data together to build more robust and capable systems. The insights from this research could have far-reaching implications for applications ranging from video understanding to intelligent personal assistants.
As the field of multimodal AI continues to evolve, the T-CLAP model and its underlying principles are likely to inspire further advancements and inspire researchers to explore new ways of integrating temporal dynamics and disentangling content and style in multimodal learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

tinyCLAP: Distilling Constrastive Language-Audio Pretrained Models
Francesco Paissan, Elisabetta Farella
0
0
Contrastive Language-Audio Pretraining (CLAP) became of crucial importance in the field of audio and speech processing. Its employment ranges from sound event detection to text-to-audio generation. However, one of the main limitations is the considerable amount of data required in the training process and the overall computational complexity during inference. This paper investigates how we can reduce the complexity of contrastive language-audio pre-trained models, yielding an efficient model that we call tinyCLAP. We derive an unimodal distillation loss from first principles and explore how the dimensionality of the shared, multimodal latent space can be reduced via pruning. TinyCLAP uses only 6% of the original Microsoft CLAP parameters with a minimal reduction (less than 5%) in zero-shot classification performance across the three sound event detection datasets on which it was tested
6/13/2024

ParaCLAP -- Towards a general language-audio model for computational paralinguistic tasks
Xin Jing, Andreas Triantafyllopoulos, Bjorn Schuller
0
0
Contrastive language-audio pretraining (CLAP) has recently emerged as a method for making audio analysis more generalisable. Specifically, CLAP-style models are able to `answer' a diverse set of language queries, extending the capabilities of audio models beyond a closed set of labels. However, CLAP relies on a large set of (audio, query) pairs for pretraining. While such sets are available for general audio tasks, like captioning or sound event detection, there are no datasets with matched audio and text queries for computational paralinguistic (CP) tasks. As a result, the community relies on generic CLAP models trained for general audio with limited success. In the present study, we explore training considerations for ParaCLAP, a CLAP-style model suited to CP, including a novel process for creating audio-language queries. We demonstrate its effectiveness on a set of computational paralinguistic tasks, where it is shown to surpass the performance of open-source state-of-the-art models.
6/12/2024
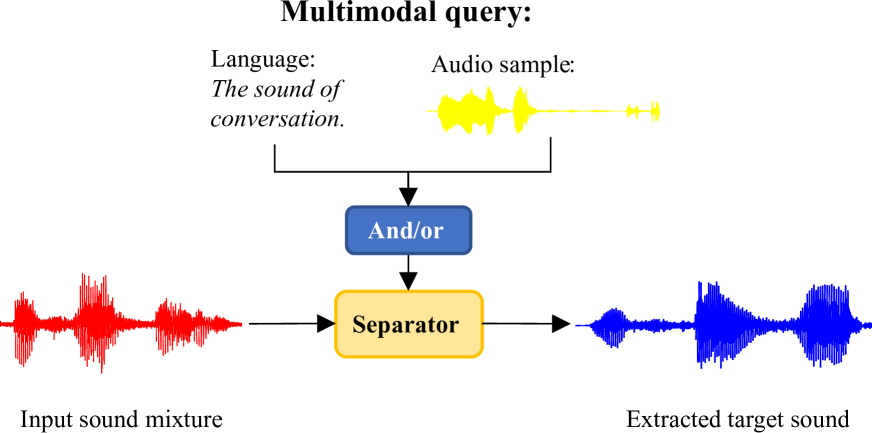
CLAPSep: Leveraging Contrastive Pre-trained Model for Multi-Modal Query-Conditioned Target Sound Extraction
Hao Ma, Zhiyuan Peng, Xu Li, Mingjie Shao, Xixin Wu, Ju Liu
0
0
Universal sound separation (USS) aims to extract arbitrary types of sounds from real-world recordings. This can be achieved by language-queried target sound extraction (TSE), which typically consists of two components: a query network that converts user queries into conditional embeddings, and a separation network that extracts the target sound accordingly. Existing methods commonly train models from scratch. As a consequence, substantial data and computational resources are required to improve the models' performance and generalizability. In this paper, we propose to integrate pre-trained models into TSE models to address the above issue. To be specific, we tailor and adapt the powerful contrastive language-audio pre-trained model (CLAP) for USS, denoted as CLAPSep. CLAPSep also accepts flexible user inputs, taking both positive and negative user prompts of uni- and/or multi-modalities for target sound extraction. These key features of CLAPSep can not only enhance the extraction performance but also improve the versatility of its application. We provide extensive experiments on 5 diverse datasets to demonstrate the superior performance and zero- and few-shot generalizability of our proposed CLAPSep with fast training convergence, surpassing previous methods by a significant margin. Full codes and some audio examples are released for reproduction and evaluation.
5/9/2024
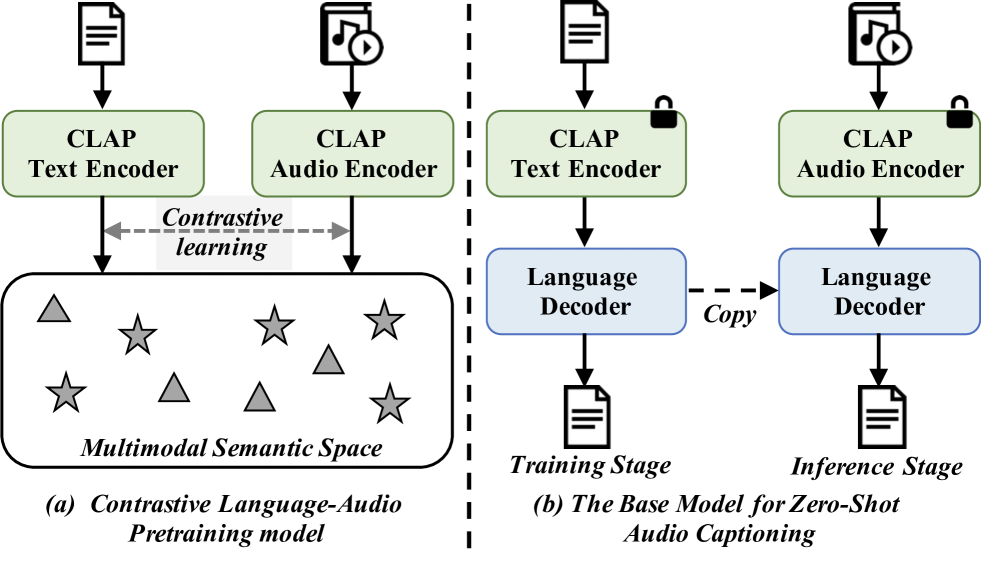
Zero-Shot Audio Captioning Using Soft and Hard Prompts
Yiming Zhang, Xuenan Xu, Ruoyi Du, Haohe Liu, Yuan Dong, Zheng-Hua Tan, Wenwu Wang, Zhanyu Ma
0
0
In traditional audio captioning methods, a model is usually trained in a fully supervised manner using a human-annotated dataset containing audio-text pairs and then evaluated on the test sets from the same dataset. Such methods have two limitations. First, these methods are often data-hungry and require time-consuming and expensive human annotations to obtain audio-text pairs. Second, these models often suffer from performance degradation in cross-domain scenarios, i.e., when the input audio comes from a different domain than the training set, which, however, has received little attention. We propose an effective audio captioning method based on the contrastive language-audio pre-training (CLAP) model to address these issues. Our proposed method requires only textual data for training, enabling the model to generate text from the textual feature in the cross-modal semantic space.In the inference stage, the model generates the descriptive text for the given audio from the audio feature by leveraging the audio-text alignment from CLAP.We devise two strategies to mitigate the discrepancy between text and audio embeddings: a mixed-augmentation-based soft prompt and a retrieval-based acoustic-aware hard prompt. These approaches are designed to enhance the generalization performance of our proposed model, facilitating the model to generate captions more robustly and accurately. Extensive experiments on AudioCaps and Clotho benchmarks show the effectiveness of our proposed method, which outperforms other zero-shot audio captioning approaches for in-domain scenarios and outperforms the compared methods for cross-domain scenarios, underscoring the generalization ability of our method.
6/11/2024