Tabula: Efficiently Computing Nonlinear Activation Functions for Secure Neural Network Inference

0
🧠
Sign in to get full access
Overview
- Proposes an alternative to garbled circuits for secure neural network inference, called Tabula
- Tabula uses secure lookup tables to efficiently compute nonlinear activation functions
- Reduces communication, storage, and runtime costs compared to garbled circuit approaches
Plain English Explanation
Tabula is a new way to perform secure neural network inference, which means running a neural network model on sensitive data without revealing the data or the model. Traditional approaches, like garbled circuits, require a lot of back-and-forth communication between the client (who has the data) and the server (who has the model). This communication is costly and slows down the inference process.
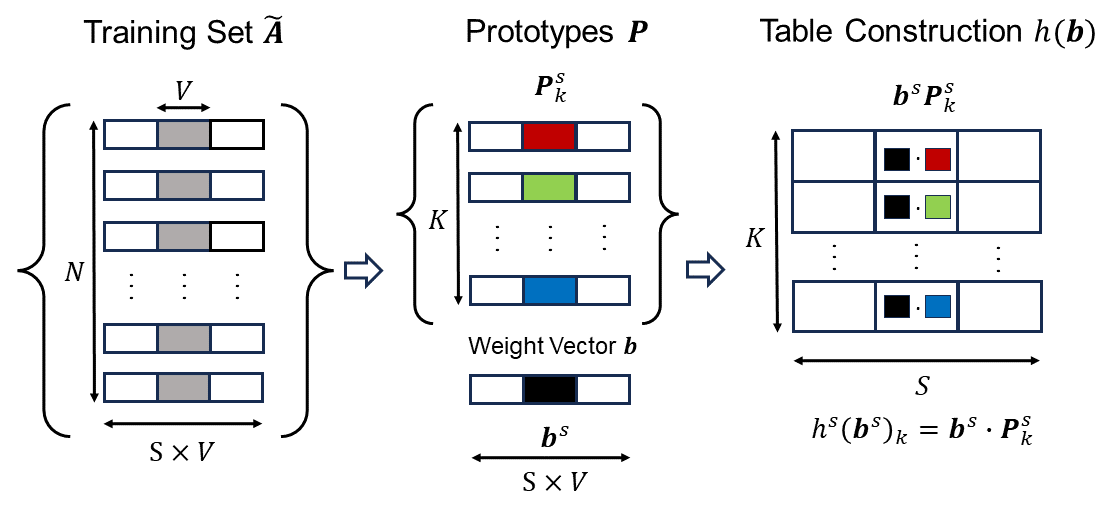
Tabula's key idea is to precompute lookup tables for the nonlinear activation functions used in the neural network. These tables contain the result of every possible input to the activation function. During the actual inference, the client can just look up the result in the table instead of having to compute it. This reduces the communication needed to a single round, where the client sends the input and receives the result.
To make this approach practical, the authors use quantization to reduce the size of the lookup tables. Quantization involves representing numbers with fewer bits, which saves storage space but can introduce some errors.
Compared to garbled circuits, Tabula achieves significant improvements in communication, speed, and storage requirements for secure neural network inference. It can reduce communication by up to 9 times and speed up the overall inference process by up to 50 times, while using a comparable amount of storage.
Technical Explanation
Tabula is an algorithm for performing secure neural network inference that is based on secure lookup tables, rather than the more common approach of using garbled circuits.
The key idea behind Tabula is to precompute lookup tables during an offline phase that contain the results of all possible nonlinear function calls (such as activation functions) used in the neural network. During the online phase of inference, the client can simply look up the result of applying a nonlinear function to their input, rather than having to compute it securely using a garbled circuit.
This approach significantly reduces the communication and runtime costs compared to garbled circuits, which require multiple rounds of communication between the client and server. Tabula's online phase requires only a single round of communication, with the cost equal to twice the number of bits of the input to the nonlinear function.
To make this approach practical, the authors use quantization to reduce the storage costs of the lookup tables, which would otherwise grow exponentially with the number of operands and precision of the input values. The quantization introduces some error, but the authors show that the performance gains outweigh this trade-off.
Compared to garbled circuits with 8-bit quantized inputs, Tabula with 8-bit activations uses 280-560 times less communication, is over 100 times faster, and uses a comparable amount of storage. Compared to other state-of-the-art protocols, Tabula achieves greater than 40 times communication reduction.
These improvements lead to significant performance gains in the end-to-end secure inference of neural networks. Tabula can reduce the communication by up to 9 times and achieve an end-to-end inference speedup of up to 50 times, while imposing comparable storage and offline preprocessing costs.
Critical Analysis
The authors of the Tabula paper have thoroughly evaluated their approach and provided a comprehensive comparison to existing techniques, such as garbled circuits and other state-of-the-art secure inference protocols. However, there are a few potential limitations and areas for further research:
-
The use of quantization to reduce the storage costs of the lookup tables may introduce some accuracy loss, which could be a concern for certain applications. The authors have shown that the performance gains outweigh this trade-off, but the impact on model accuracy should be further studied, especially for more complex neural network architectures.
-
The offline preprocessing phase required to generate the lookup tables may be computationally expensive and time-consuming, particularly for large neural networks. The authors mention that this cost is amortized over many inference requests, but the scalability of this approach for rapidly evolving models or real-time applications should be investigated.
-
The Tabula approach is primarily focused on the efficient computation of nonlinear activation functions, but there may be other components of the neural network inference process (e.g., linear operations, pooling layers) that could also benefit from specialized secure computation techniques. Exploring a more holistic approach to secure neural network inference could lead to further performance improvements.
-
The paper does not address the potential privacy and security implications of using precomputed lookup tables, which could be vulnerable to certain attack vectors if not properly secured. The authors should provide more guidance on how to ensure the confidentiality and integrity of the lookup tables in real-world deployments.
Despite these potential concerns, the Tabula approach represents a significant advancement in the field of secure neural network inference, and the authors have demonstrated its effectiveness through rigorous experimentation. Continued research and refinement of this technique could lead to even greater performance gains and broader adoption of secure machine learning in sensitive applications.
Conclusion
The Tabula algorithm proposed in this paper offers a novel approach to secure neural network inference that addresses the limitations of traditional garbled circuit-based methods. By using precomputed secure lookup tables, Tabula can significantly reduce the communication, storage, and runtime costs associated with executing nonlinear activation functions during the online inference phase.
The authors have shown that Tabula can achieve up to 9 times reduction in end-to-end inference communication and up to 50 times speedup, while maintaining comparable storage and offline preprocessing requirements. These performance gains could enable the widespread adoption of secure machine learning in a variety of sensitive applications, such as healthcare, finance, and security.
While the Tabula approach has some potential limitations, such as the impact of quantization on model accuracy and the scalability of the offline preprocessing, the authors have provided a solid foundation for further research and refinement. Exploring ways to address these challenges and expand the technique to other components of the neural network inference process could lead to even greater advancements in the field of secure machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Tabula: Efficiently Computing Nonlinear Activation Functions for Secure Neural Network Inference
Maximilian Lam, Michael Mitzenmacher, Vijay Janapa Reddi, Gu-Yeon Wei, David Brooks
Multiparty computation approaches to secure neural network inference commonly rely on garbled circuits for securely executing nonlinear activation functions. However, garbled circuits require excessive communication between server and client, impose significant storage overheads, and incur large runtime penalties. To reduce these costs, we propose an alternative to garbled circuits: Tabula, an algorithm based on secure lookup tables. Our approach precomputes lookup tables during an offline phase that contains the result of all possible nonlinear function calls. Because these tables incur exponential storage costs in the number of operands and the precision of the input values, we use quantization to reduce these storage costs to make this approach practical. This enables an online phase where securely computing the result of a nonlinear function requires just a single round of communication, with communication cost equal to twice the number of bits of the input to the nonlinear function. In practice our approach costs 2 bytes of communication per nonlinear function call in the online phase. Compared to garbled circuits with 8-bit quantized inputs, when computing individual nonlinear functions during the online phase, experiments show Tabula with 8-bit activations uses between $280$-$560 times$ less communication, is over $100times$ faster, and uses a comparable (within a factor of 2) amount of storage; compared against other state-of-the-art protocols Tabula achieves greater than $40times$ communication reduction. This leads to significant performance gains over garbled circuits with quantized inputs during the online phase of secure inference of neural networks: Tabula reduces end-to-end inference communication by up to $9 times$ and achieves an end-to-end inference speedup of up to $50 times$, while imposing comparable storage and offline preprocessing costs.
Read more6/18/2024
0
TabConv: Low-Computation CNN Inference via Table Lookups
Neelesh Gupta, Narayanan Kannan, Pengmiao Zhang, Viktor Prasanna
Convolutional Neural Networks (CNNs) have demonstrated remarkable ability throughout the field of computer vision. However, CNN inference requires a large number of arithmetic operations, making them expensive to deploy in hardware. Current approaches alleviate this issue by developing hardware-supported, algorithmic processes to simplify spatial convolution functions. However, these methods still heavily rely on matrix multiplication, leading to significant computational overhead. To bridge the gap between hardware, algorithmic acceleration, and approximate matrix multiplication, we propose TabConv, a novel, table-based approximation for convolution to significantly reduce arithmetic operations during inference. Additionally, we introduce a priority masking technique based on cosine similarity to select layers for table-based approximation, thereby maintaining the model performance. We evaluate our approach on popular CNNs: ResNet-18, ResNet-34, and NetworkInNetwork (NIN). TabConv preserves over 93% of the original model's performance while reducing arithmetic operations by 36.5%, 25.8%, and 99.4% for ResNet-18 on CIFAR-10, CIFAR-100, and MNIST, respectively, 35.6% and 99.3% for ResNet-34 on CIFAR-10 and MNIST, and 98.9% for NIN on MNIST, achieving low-computation inference.
Read more4/10/2024
🧠
0
NeuraLUT: Hiding Neural Network Density in Boolean Synthesizable Functions
Marta Andronic, George A. Constantinides
Field-Programmable Gate Array (FPGA) accelerators have proven successful in handling latency- and resource-critical deep neural network (DNN) inference tasks. Among the most computationally intensive operations in a neural network (NN) is the dot product between the feature and weight vectors. Thus, some previous FPGA acceleration works have proposed mapping neurons with quantized inputs and outputs directly to lookup tables (LUTs) for hardware implementation. In these works, the boundaries of the neurons coincide with the boundaries of the LUTs. We propose relaxing these boundaries and mapping entire sub-networks to a single LUT. As the sub-networks are absorbed within the LUT, the NN topology and precision within a partition do not affect the size of the lookup tables generated. Therefore, we utilize fully connected layers with floating-point precision inside each partition, which benefit from being universal function approximators, but with rigid sparsity and quantization enforced between partitions, where the NN topology becomes exposed to the circuit topology. Although cheap to implement, this approach can lead to very deep NNs, and so to tackle challenges like vanishing gradients, we also introduce skip connections inside the partitions. The resulting methodology can be seen as training DNNs with a specific FPGA hardware-inspired sparsity pattern that allows them to be mapped to much shallower circuit-level networks, thereby significantly improving latency. We validate our proposed method on a known latency-critical task, jet substructure tagging, and on the classical computer vision task, digit classification using MNIST. Our approach allows for greater function expressivity within the LUTs compared to existing work, leading to up to $4.3times$ lower latency NNs for the same accuracy.
Read more7/4/2024
0
Fast and Private Inference of Deep Neural Networks by Co-designing Activation Functions
Abdulrahman Diaa, Lucas Fenaux, Thomas Humphries, Marian Dietz, Faezeh Ebrahimianghazani, Bailey Kacsmar, Xinda Li, Nils Lukas, Rasoul Akhavan Mahdavi, Simon Oya, Ehsan Amjadian, Florian Kerschbaum
Machine Learning as a Service (MLaaS) is an increasingly popular design where a company with abundant computing resources trains a deep neural network and offers query access for tasks like image classification. The challenge with this design is that MLaaS requires the client to reveal their potentially sensitive queries to the company hosting the model. Multi-party computation (MPC) protects the client's data by allowing encrypted inferences. However, current approaches suffer from prohibitively large inference times. The inference time bottleneck in MPC is the evaluation of non-linear layers such as ReLU activation functions. Motivated by the success of previous work co-designing machine learning and MPC, we develop an activation function co-design. We replace all ReLUs with a polynomial approximation and evaluate them with single-round MPC protocols, which give state-of-the-art inference times in wide-area networks. Furthermore, to address the accuracy issues previously encountered with polynomial activations, we propose a novel training algorithm that gives accuracy competitive with plaintext models. Our evaluation shows between $3$ and $110times$ speedups in inference time on large models with up to $23$ million parameters while maintaining competitive inference accuracy.
Read more4/17/2024