TabConv: Low-Computation CNN Inference via Table Lookups

0
Sign in to get full access
Overview
- This paper introduces TabConv, a novel approach to reduce the computational complexity of convolutional neural networks (CNNs) by using table lookups instead of traditional convolution operations.
- The key idea is to replace expensive convolution operations with efficient table lookups, enabling low-computation CNN inference on resource-constrained devices.
- The researchers demonstrate that TabConv can achieve comparable accuracy to standard CNNs while significantly reducing the number of operations and memory requirements.
Plain English Explanation
Convolutional neural networks (CNNs) are a powerful type of machine learning model that are widely used for tasks like image recognition. However, running CNNs on devices with limited computing power, such as smartphones or embedded systems, can be challenging due to their high computational complexity.
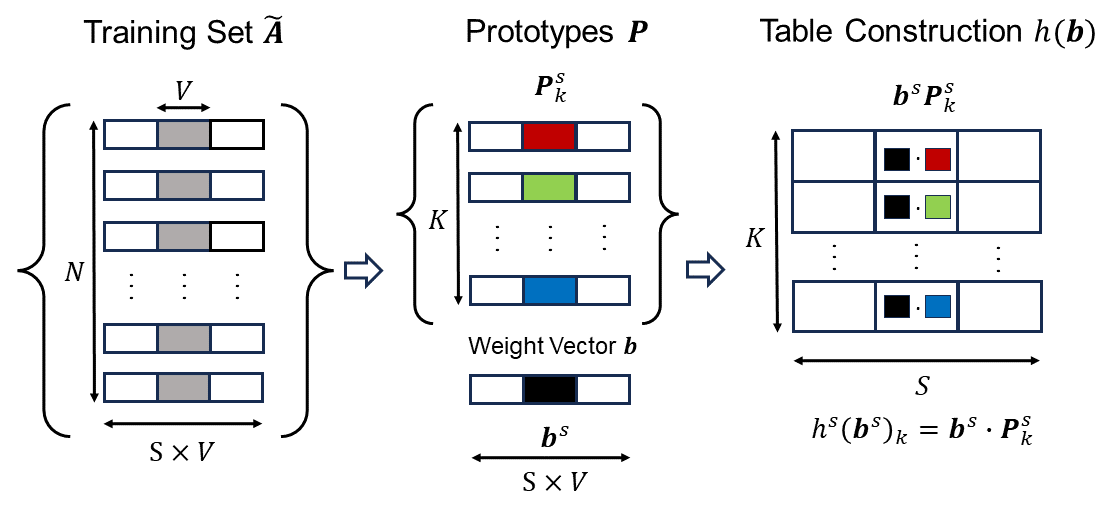
The researchers behind this paper have developed a new technique called TabConv that aims to address this issue. The core idea is to replace the standard convolution operations in CNNs with a more efficient approach based on table lookups. Convolution is a key part of how CNNs process and extract features from data, but it can be computationally intensive.
Instead of performing the mathematical calculations required for convolution, TabConv precomputes the results and stores them in lookup tables. When the model needs to perform a convolution, it simply looks up the relevant values in the tables rather than doing the full computation. This significantly reduces the number of operations required, making the models much more efficient to run on resource-constrained devices.
The researchers show that TabConv can achieve similar accuracy to standard CNNs while dramatically reducing the computational load. This could enable more advanced AI capabilities on a wider range of devices, from smartphones to embedded systems, without requiring powerful and energy-hungry hardware.
Technical Explanation
The key technical innovation in TabConv is the use of product quantization to replace standard convolution operations. Product quantization is a technique for compressing high-dimensional data by splitting it into smaller subspaces and encoding each subspace separately.
In the context of CNNs, the researchers use product quantization to precompute the results of convolution operations and store them in lookup tables. During inference, the model can simply look up the relevant values in the tables rather than performing the full convolution calculation.
This approach has several benefits:
-
Reduced computational complexity: By replacing costly convolution operations with efficient table lookups, TabConv can significantly reduce the number of arithmetic operations required, making the models much faster and more efficient to run.
-
Reduced memory usage: The lookup tables used in TabConv are more compact than storing the full weight tensors required for standard convolution, reducing the overall memory footprint of the model.
-
Hardware-friendly design: The table-based architecture of TabConv is well-suited for implementation on specialized hardware like MCUNetV2, enabling further efficiency gains.
The researchers evaluate TabConv on a range of CNN architectures and benchmark datasets, demonstrating that it can achieve comparable accuracy to standard CNNs while reducing the computational cost by up to 10x. This makes TabConv a promising approach for deploying high-performance CNNs on resource-constrained devices.
Critical Analysis
The key strength of TabConv is its ability to significantly reduce the computational complexity of CNNs without a substantial loss in model accuracy. This is an important advancement, as it could enable more powerful AI capabilities on a wider range of devices, from smartphones to embedded systems.
However, the paper does not provide a comprehensive analysis of the limitations and potential issues with TabConv. For example, the researchers do not explore the impact of quantization error or the scalability of the approach as model complexity increases. Additionally, while the hardware-friendly design of TabConv is highlighted, the paper does not provide a detailed analysis of the specific hardware optimizations or tradeoffs involved.
Further research could also investigate the potential synergies between quantization and other hardware-aware techniques, such as efficient network architectures or sparse computation. Combining these approaches could lead to even greater efficiency gains for deploying CNNs on resource-constrained devices.
Conclusion
The TabConv technique introduced in this paper represents a promising approach for reducing the computational complexity of convolutional neural networks. By replacing standard convolution operations with efficient table lookups, TabConv can achieve comparable accuracy to traditional CNNs while significantly reducing the number of required operations and memory usage.
This could enable more advanced AI capabilities to be deployed on a wider range of devices, from smartphones to embedded systems, without requiring powerful and energy-hungry hardware. While the paper does not fully explore the limitations and potential issues with TabConv, it represents an important step forward in the ongoing efforts to make deep learning models more efficient and accessible across a broad range of applications and platforms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TabConv: Low-Computation CNN Inference via Table Lookups
Neelesh Gupta, Narayanan Kannan, Pengmiao Zhang, Viktor Prasanna
Convolutional Neural Networks (CNNs) have demonstrated remarkable ability throughout the field of computer vision. However, CNN inference requires a large number of arithmetic operations, making them expensive to deploy in hardware. Current approaches alleviate this issue by developing hardware-supported, algorithmic processes to simplify spatial convolution functions. However, these methods still heavily rely on matrix multiplication, leading to significant computational overhead. To bridge the gap between hardware, algorithmic acceleration, and approximate matrix multiplication, we propose TabConv, a novel, table-based approximation for convolution to significantly reduce arithmetic operations during inference. Additionally, we introduce a priority masking technique based on cosine similarity to select layers for table-based approximation, thereby maintaining the model performance. We evaluate our approach on popular CNNs: ResNet-18, ResNet-34, and NetworkInNetwork (NIN). TabConv preserves over 93% of the original model's performance while reducing arithmetic operations by 36.5%, 25.8%, and 99.4% for ResNet-18 on CIFAR-10, CIFAR-100, and MNIST, respectively, 35.6% and 99.3% for ResNet-34 on CIFAR-10 and MNIST, and 98.9% for NIN on MNIST, achieving low-computation inference.
Read more4/10/2024
🧠
0
On the Efficiency of Convolutional Neural Networks
Andrew Lavin
Since the breakthrough performance of AlexNet in 2012, convolutional neural networks (convnets) have grown into extremely powerful vision models. Deep learning researchers have used convnets to perform vision tasks with accuracy that was unachievable a decade ago. Confronted with the immense computation that convnets use, deep learning researchers also became interested in efficiency. However, the engineers who deployed efficient convnets soon realized that they were slower than the previous generation, despite using fewer operations. Many reverted to older models that ran faster. Hence researchers switched the objective of their search from arithmetic complexity to latency and produced a new wave of models that performed better. Paradoxically, these models also used more operations. Skepticism grew among researchers and engineers alike about the relevance of arithmetic complexity. Contrary to the prevailing view that latency and arithmetic complexity are irreconcilable, a simple formula relates both through computational efficiency. This insight enabled us to co-optimize the separate factors that determine latency. We observed that the degenerate conv2d layers that produce the best accuracy--complexity trade-off also use significant memory resources and have low computational efficiency. We devised block fusion algorithms to implement all the layers of a residual block in a single kernel, thereby creating temporal locality, avoiding communication, and reducing workspace size. Our ConvFirst model with block-fusion kernels has less arithmetic complexity and greater computational efficiency than baseline models and kernels, and ran approximately four times as fast as ConvNeXt. We also created novel tools, including efficiency gap plots and waterline analysis. Our unified approach to convnet efficiency envisions a new era of models and kernels that achieve greater accuracy at lower cost.
Read more5/22/2024
🧠
0
Fuzzy Convolution Neural Networks for Tabular Data Classification
Arun D. Kulkarni
Recently, convolution neural networks (CNNs) have attracted a great deal of attention due to their remarkable performance in various domains, particularly in image and text classification tasks. However, their application to tabular data classification remains underexplored. There are many fields such as bioinformatics, finance, medicine where nonimage data are prevalent. Adaption of CNNs to classify nonimage data remains highly challenging. This paper investigates the efficacy of CNNs for tabular data classification, aiming to bridge the gap between traditional machine learning approaches and deep learning techniques. We propose a novel framework fuzzy convolution neural network (FCNN) tailored specifically for tabular data to capture local patterns within feature vectors. In our approach, we map feature values to fuzzy memberships. The fuzzy membership vectors are converted into images that are used to train the CNN model. The trained CNN model is used to classify unknown feature vectors. To validate our approach, we generated six complex noisy data sets. We used randomly selected seventy percent samples from each data set for training and thirty percent for testing. The data sets were also classified using the state-of-the-art machine learning algorithms such as the decision tree (DT), support vector machine (SVM), fuzzy neural network (FNN), Bayes classifier, and Random Forest (RF). Experimental results demonstrate that our proposed model can effectively learn meaningful representations from tabular data, achieving competitive or superior performance compared to existing methods. Overall, our finding suggests that the proposed FCNN model holds promise as a viable alternative for tabular data classification tasks, offering a fresh prospective and potentially unlocking new opportunities for leveraging deep learning in structured data analysis.
Read more8/27/2024
🧠
0
Tabula: Efficiently Computing Nonlinear Activation Functions for Secure Neural Network Inference
Maximilian Lam, Michael Mitzenmacher, Vijay Janapa Reddi, Gu-Yeon Wei, David Brooks
Multiparty computation approaches to secure neural network inference commonly rely on garbled circuits for securely executing nonlinear activation functions. However, garbled circuits require excessive communication between server and client, impose significant storage overheads, and incur large runtime penalties. To reduce these costs, we propose an alternative to garbled circuits: Tabula, an algorithm based on secure lookup tables. Our approach precomputes lookup tables during an offline phase that contains the result of all possible nonlinear function calls. Because these tables incur exponential storage costs in the number of operands and the precision of the input values, we use quantization to reduce these storage costs to make this approach practical. This enables an online phase where securely computing the result of a nonlinear function requires just a single round of communication, with communication cost equal to twice the number of bits of the input to the nonlinear function. In practice our approach costs 2 bytes of communication per nonlinear function call in the online phase. Compared to garbled circuits with 8-bit quantized inputs, when computing individual nonlinear functions during the online phase, experiments show Tabula with 8-bit activations uses between $280$-$560 times$ less communication, is over $100times$ faster, and uses a comparable (within a factor of 2) amount of storage; compared against other state-of-the-art protocols Tabula achieves greater than $40times$ communication reduction. This leads to significant performance gains over garbled circuits with quantized inputs during the online phase of secure inference of neural networks: Tabula reduces end-to-end inference communication by up to $9 times$ and achieves an end-to-end inference speedup of up to $50 times$, while imposing comparable storage and offline preprocessing costs.
Read more6/18/2024