TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- Reinforcement learning (RL) has made significant progress in learning from raw pixel data, but sample inefficiency remains a substantial challenge.
- Prior works have attempted to address this by creating self-supervised auxiliary tasks to enrich the agent's learned representations for future state prediction.
- However, these objectives are often insufficient to learn representations that can represent the optimal policy or value function, and they often consider tasks with small, abstract discrete action spaces, overlooking the importance of action representation learning in continuous control.
- This paper introduces TACO: Temporal Action-driven Contrastive Learning, a temporal contrastive learning approach that facilitates the concurrent acquisition of latent state and action representations for agents.
Plain English Explanation
TACO is a new technique that helps AI agents learn more efficiently in continuous control tasks, such as navigating a virtual environment or controlling a robot. Traditional RL methods can struggle with these types of tasks because they require the agent to learn effective representations of both the current state and the available actions.
TACO addresses this by using a "contrastive learning" approach, which means the agent learns by comparing the current state and action to future states. This helps the agent develop a deep understanding of how its actions affect the environment, which can lead to faster and more effective learning.
The key insight is that by simultaneously learning representations for both the current state and the available actions, the agent can build a more comprehensive model of the task, rather than focusing on just the state or just the actions. This "dual representation" approach is what allows TACO to outperform other methods in terms of sample efficiency, meaning the agent can learn effective policies with fewer interactions with the environment.
Technical Explanation
TACO is a temporal contrastive learning approach that facilitates the concurrent acquisition of latent state and action representations for agents operating in continuous control environments. The key insight is that by learning representations for both the current state and the available actions, the agent can build a more comprehensive model of the task, leading to improved sample efficiency in online RL.
Specifically, TACO optimizes the mutual information between representations of current states paired with action sequences and representations of the corresponding future states. This allows the agent to learn state and action representations that encompass sufficient information for control, as demonstrated by the 40% performance boost after one million environment interaction steps on average across nine challenging visual continuous control tasks from the DeepMind Control Suite.
Additionally, the authors show that TACO can serve as a plug-and-play module that can be added to existing offline visual RL methods to establish new state-of-the-art performance for offline visual RL across offline datasets with varying quality. This highlights the versatility of the TACO approach and its potential to benefit a wide range of reinforcement learning applications.
Critical Analysis
While the TACO approach demonstrates impressive performance gains in both online and offline RL settings, the paper does not provide a detailed theoretical analysis of the conditions under which the learned representations are guaranteed to be sufficient for control. The authors cite theoretical results, but more rigor in this area could help build a stronger understanding of the fundamental principles underlying the success of TACO.
Additionally, the paper does not address the computational complexity of the TACO algorithm, which could be an important consideration for real-world deployment, especially in resource-constrained environments. The authors could have provided more details on the scalability of TACO and how it compares to other state-of-the-art methods in terms of computational efficiency.
Furthermore, the paper focuses on visual continuous control tasks, but it would be interesting to see how TACO performs in other types of RL problems, such as multi-task learning, action-centric representation learning, or semi-supervised learning. This could help identify the broader applicability of the TACO approach and its potential limitations.
Conclusion
The TACO approach introduced in this paper represents a promising step forward in addressing the sample efficiency challenge in reinforcement learning from raw pixel data. By simultaneously learning representations for both the current state and the available actions, TACO can build a more comprehensive model of the task, leading to significant performance gains in both online and offline RL settings.
While the paper does not address certain theoretical and practical aspects in depth, the impressive empirical results suggest that TACO is a valuable contribution to the field of reinforcement learning. As the research community continues to explore new ways to improve sample efficiency and representation learning, techniques like TACO will likely play an important role in advancing the state of the art and expanding the capabilities of RL agents in complex, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning
Ruijie Zheng, Xiyao Wang, Yanchao Sun, Shuang Ma, Jieyu Zhao, Huazhe Xu, Hal Daum'e III, Furong Huang
Despite recent progress in reinforcement learning (RL) from raw pixel data, sample inefficiency continues to present a substantial obstacle. Prior works have attempted to address this challenge by creating self-supervised auxiliary tasks, aiming to enrich the agent's learned representations with control-relevant information for future state prediction. However, these objectives are often insufficient to learn representations that can represent the optimal policy or value function, and they often consider tasks with small, abstract discrete action spaces and thus overlook the importance of action representation learning in continuous control. In this paper, we introduce TACO: Temporal Action-driven Contrastive Learning, a simple yet powerful temporal contrastive learning approach that facilitates the concurrent acquisition of latent state and action representations for agents. TACO simultaneously learns a state and an action representation by optimizing the mutual information between representations of current states paired with action sequences and representations of the corresponding future states. Theoretically, TACO can be shown to learn state and action representations that encompass sufficient information for control, thereby improving sample efficiency. For online RL, TACO achieves 40% performance boost after one million environment interaction steps on average across nine challenging visual continuous control tasks from Deepmind Control Suite. In addition, we show that TACO can also serve as a plug-and-play module adding to existing offline visual RL methods to establish the new state-of-the-art performance for offline visual RL across offline datasets with varying quality.
Read more5/27/2024

0
Premier-TACO is a Few-Shot Policy Learner: Pretraining Multitask Representation via Temporal Action-Driven Contrastive Loss
Ruijie Zheng, Yongyuan Liang, Xiyao Wang, Shuang Ma, Hal Daum'e III, Huazhe Xu, John Langford, Praveen Palanisamy, Kalyan Shankar Basu, Furong Huang
We present Premier-TACO, a multitask feature representation learning approach designed to improve few-shot policy learning efficiency in sequential decision-making tasks. Premier-TACO leverages a subset of multitask offline datasets for pretraining a general feature representation, which captures critical environmental dynamics and is fine-tuned using minimal expert demonstrations. It advances the temporal action contrastive learning (TACO) objective, known for state-of-the-art results in visual control tasks, by incorporating a novel negative example sampling strategy. This strategy is crucial in significantly boosting TACO's computational efficiency, making large-scale multitask offline pretraining feasible. Our extensive empirical evaluation in a diverse set of continuous control benchmarks including Deepmind Control Suite, MetaWorld, and LIBERO demonstrate Premier-TACO's effectiveness in pretraining visual representations, significantly enhancing few-shot imitation learning of novel tasks. Our code, pretraining data, as well as pretrained model checkpoints will be released at https://github.com/PremierTACO/premier-taco. Our project webpage is at https://premiertaco.github.io.
Read more5/27/2024
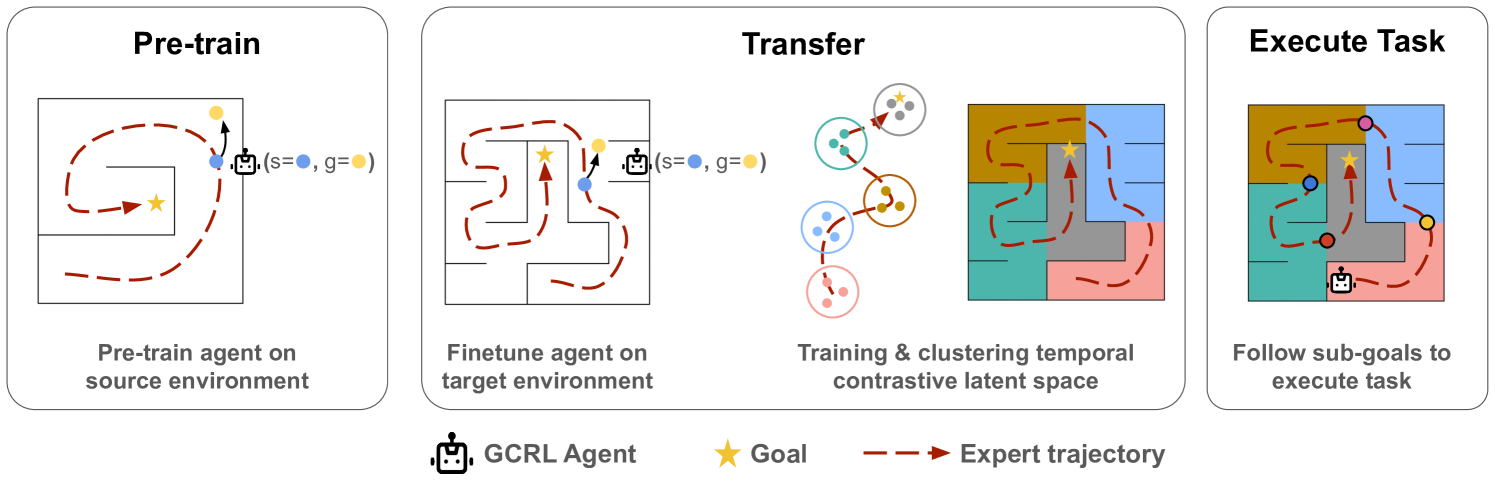
0
Multi-Agent Transfer Learning via Temporal Contrastive Learning
Weihao Zeng, Joseph Campbell, Simon Stepputtis, Katia Sycara
This paper introduces a novel transfer learning framework for deep multi-agent reinforcement learning. The approach automatically combines goal-conditioned policies with temporal contrastive learning to discover meaningful sub-goals. The approach involves pre-training a goal-conditioned agent, finetuning it on the target domain, and using contrastive learning to construct a planning graph that guides the agent via sub-goals. Experiments on multi-agent coordination Overcooked tasks demonstrate improved sample efficiency, the ability to solve sparse-reward and long-horizon problems, and enhanced interpretability compared to baselines. The results highlight the effectiveness of integrating goal-conditioned policies with unsupervised temporal abstraction learning for complex multi-agent transfer learning. Compared to state-of-the-art baselines, our method achieves the same or better performances while requiring only 21.7% of the training samples.
Read more6/4/2024

0
Efficient Multi-Task Reinforcement Learning via Task-Specific Action Correction
Jinyuan Feng, Min Chen, Zhiqiang Pu, Tenghai Qiu, Jianqiang Yi
Multi-task reinforcement learning (MTRL) demonstrate potential for enhancing the generalization of a robot, enabling it to perform multiple tasks concurrently. However, the performance of MTRL may still be susceptible to conflicts between tasks and negative interference. To facilitate efficient MTRL, we propose Task-Specific Action Correction (TSAC), a general and complementary approach designed for simultaneous learning of multiple tasks. TSAC decomposes policy learning into two separate policies: a shared policy (SP) and an action correction policy (ACP). To alleviate conflicts resulting from excessive focus on specific tasks' details in SP, ACP incorporates goal-oriented sparse rewards, enabling an agent to adopt a long-term perspective and achieve generalization across tasks. Additional rewards transform the original problem into a multi-objective MTRL problem. Furthermore, to convert the multi-objective MTRL into a single-objective formulation, TSAC assigns a virtual expected budget to the sparse rewards and employs Lagrangian method to transform a constrained single-objective optimization into an unconstrained one. Experimental evaluations conducted on Meta-World's MT10 and MT50 benchmarks demonstrate that TSAC outperforms existing state-of-the-art methods, achieving significant improvements in both sample efficiency and effective action execution.
Read more4/10/2024