Multi-Agent Transfer Learning via Temporal Contrastive Learning

0
Sign in to get full access
Overview
- The paper proposes a multi-agent transfer learning approach using a temporal contrastive learning framework.
- The framework aims to learn transferable representations by capturing the temporal dynamics of agent-environment interactions.
- It is designed to enable efficient multi-task reinforcement learning by leveraging knowledge transfer between related tasks.
Plain English Explanation
The research explores a way for artificial intelligence (AI) systems, or "agents," to learn from each other's experiences. In many real-world scenarios, multiple AI agents may need to work together to accomplish complex tasks. However, each agent may have its own unique set of skills and experiences, making it difficult for them to share knowledge effectively.
The Multi-Agent Transfer Learning via Temporal Contrastive Learning paper introduces a novel approach to address this challenge. The key idea is to have the agents learn "representations" - or abstract models - of their environment and the actions they can take, by looking at the temporal patterns in their interactions. By capturing these patterns, the agents can then transfer useful knowledge to each other, even if their specific experiences are different.
This approach builds on the concept of contrastive learning, which has been shown to be effective in helping AI systems learn robust representations from data. The TRACT framework, in particular, has demonstrated the value of incorporating temporal information into the learning process.
By leveraging these ideas, the proposed Multi-Agent Transfer Learning via Temporal Contrastive Learning approach aims to enable more efficient multi-task reinforcement learning, where agents can quickly adapt to new tasks by building on the knowledge acquired from previous ones. This could have significant implications for the development of more capable and flexible AI systems that can operate in complex, dynamic environments.
Technical Explanation
The Multi-Agent Transfer Learning via Temporal Contrastive Learning framework consists of two main components: a temporal contrastive learning module and a task-specific policy network.
The temporal contrastive learning module is responsible for learning transferable representations by capturing the temporal dynamics of agent-environment interactions. It does this by contrasting the representations of temporally related and unrelated observations, forcing the model to learn features that are predictive of the future state of the environment.
The task-specific policy network, on the other hand, leverages the learned representations to efficiently learn task-specific policies. By initializing the policy network with the representations learned by the contrastive module, the agents can quickly adapt to new tasks, even with limited data and training time.
The authors evaluate their approach on a range of multi-agent reinforcement learning environments, including Variational Offline Multi-Agent Skill Discovery scenarios. The results demonstrate that the proposed framework outperforms several baseline methods, highlighting its ability to enable efficient knowledge transfer between agents and tasks.
Critical Analysis
The Multi-Agent Transfer Learning via Temporal Contrastive Learning paper presents a promising approach to address the challenge of knowledge sharing in multi-agent systems. By focusing on the temporal dynamics of agent-environment interactions, the framework leverages a key aspect of reinforcement learning that has often been overlooked in previous transfer learning methods.
One potential limitation of the approach, as mentioned in the paper, is the assumption that the tasks being transferred between are related. In real-world scenarios, the relationship between tasks may not always be clear, and the framework may struggle to identify the appropriate knowledge to transfer. Further research could explore ways to relax this assumption and make the transfer learning process more robust to task diversity.
Additionally, the paper does not delve into the computational and memory requirements of the proposed framework. As the number of agents and tasks increases, the complexity of the system may grow, potentially limiting its scalability. Investigating ways to optimize the framework for efficient deployment in large-scale, resource-constrained environments could be a valuable area for future work.
Overall, the Multi-Agent Transfer Learning via Temporal Contrastive Learning paper presents a compelling approach that could significantly advance the field of multi-agent reinforcement learning. By enabling efficient knowledge transfer, the framework has the potential to accelerate the development of more capable and adaptable AI systems that can tackle complex, real-world challenges.
Conclusion
The Multi-Agent Transfer Learning via Temporal Contrastive Learning paper introduces a novel framework for enabling efficient knowledge transfer between artificial intelligence agents in multi-agent reinforcement learning scenarios. By capturing the temporal dynamics of agent-environment interactions through a contrastive learning approach, the framework learns transferable representations that can be leveraged to quickly adapt to new tasks.
The proposed approach has the potential to significantly enhance the flexibility and performance of multi-agent AI systems, enabling them to tackle a wider range of complex, real-world problems. As the field of AI continues to advance, techniques like this that facilitate effective knowledge sharing and transfer will become increasingly important for developing intelligent systems that can operate effectively in dynamic, uncertain environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Agent Transfer Learning via Temporal Contrastive Learning
Weihao Zeng, Joseph Campbell, Simon Stepputtis, Katia Sycara
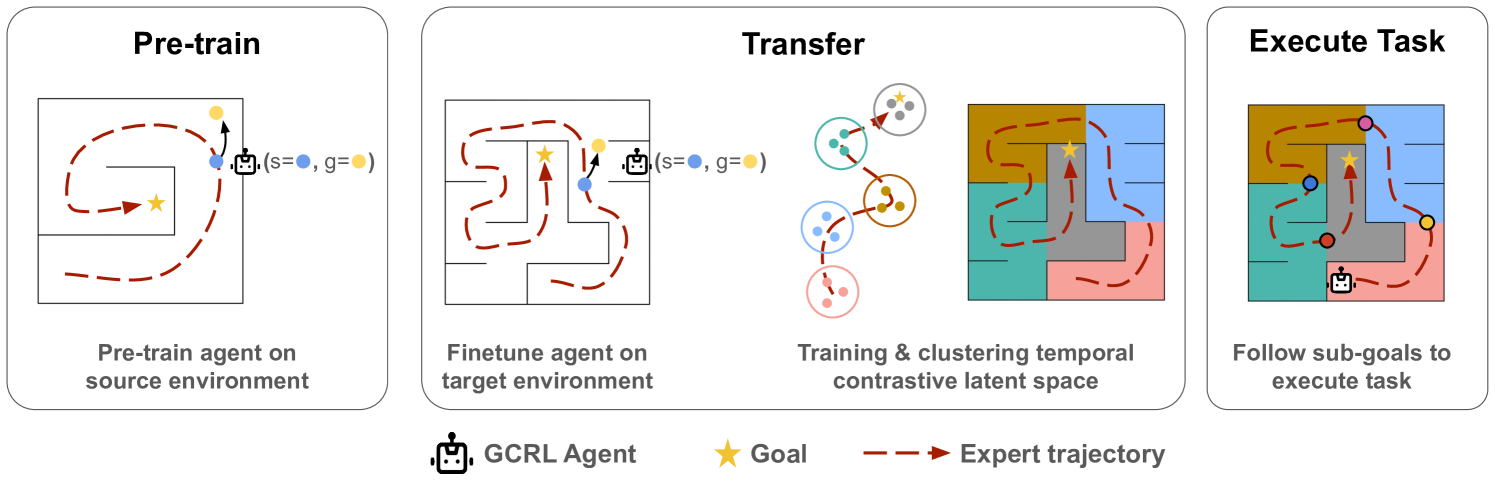
This paper introduces a novel transfer learning framework for deep multi-agent reinforcement learning. The approach automatically combines goal-conditioned policies with temporal contrastive learning to discover meaningful sub-goals. The approach involves pre-training a goal-conditioned agent, finetuning it on the target domain, and using contrastive learning to construct a planning graph that guides the agent via sub-goals. Experiments on multi-agent coordination Overcooked tasks demonstrate improved sample efficiency, the ability to solve sparse-reward and long-horizon problems, and enhanced interpretability compared to baselines. The results highlight the effectiveness of integrating goal-conditioned policies with unsupervised temporal abstraction learning for complex multi-agent transfer learning. Compared to state-of-the-art baselines, our method achieves the same or better performances while requiring only 21.7% of the training samples.
Read more6/4/2024

0
Synergistic Multi-Agent Framework with Trajectory Learning for Knowledge-Intensive Tasks
Shengbin Yue, Siyuan Wang, Wei Chen, Xuanjing Huang, Zhongyu Wei
Recent advancements in Large Language Models (LLMs) have led to significant breakthroughs in various natural language processing tasks. However, generating factually consistent responses in knowledge-intensive scenarios remains a challenge due to issues such as hallucination, difficulty in acquiring long-tailed knowledge, and limited memory expansion. This paper introduces SMART, a novel multi-agent framework that leverages external knowledge to enhance the interpretability and factual consistency of LLM-generated responses. SMART comprises four specialized agents, each performing a specific sub-trajectory action to navigate complex knowledge-intensive tasks. We propose a multi-agent co-training paradigm, Long-Short Trajectory Learning, which ensures synergistic collaboration among agents while maintaining fine-grained execution by each agent. Extensive experiments on five knowledge-intensive tasks demonstrate SMART's superior performance compared to widely adopted knowledge internalization and knowledge enhancement methods. Our framework can extend beyond knowledge-intensive tasks to more complex scenarios. Our code is available at https://github.com/yueshengbin/SMART.
Read more8/27/2024
🏅
0
TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning
Ruijie Zheng, Xiyao Wang, Yanchao Sun, Shuang Ma, Jieyu Zhao, Huazhe Xu, Hal Daum'e III, Furong Huang
Despite recent progress in reinforcement learning (RL) from raw pixel data, sample inefficiency continues to present a substantial obstacle. Prior works have attempted to address this challenge by creating self-supervised auxiliary tasks, aiming to enrich the agent's learned representations with control-relevant information for future state prediction. However, these objectives are often insufficient to learn representations that can represent the optimal policy or value function, and they often consider tasks with small, abstract discrete action spaces and thus overlook the importance of action representation learning in continuous control. In this paper, we introduce TACO: Temporal Action-driven Contrastive Learning, a simple yet powerful temporal contrastive learning approach that facilitates the concurrent acquisition of latent state and action representations for agents. TACO simultaneously learns a state and an action representation by optimizing the mutual information between representations of current states paired with action sequences and representations of the corresponding future states. Theoretically, TACO can be shown to learn state and action representations that encompass sufficient information for control, thereby improving sample efficiency. For online RL, TACO achieves 40% performance boost after one million environment interaction steps on average across nine challenging visual continuous control tasks from Deepmind Control Suite. In addition, we show that TACO can also serve as a plug-and-play module adding to existing offline visual RL methods to establish the new state-of-the-art performance for offline visual RL across offline datasets with varying quality.
Read more5/27/2024

0
TLDR: Unsupervised Goal-Conditioned RL via Temporal Distance-Aware Representations
Junik Bae, Kwanyoung Park, Youngwoon Lee
Unsupervised goal-conditioned reinforcement learning (GCRL) is a promising paradigm for developing diverse robotic skills without external supervision. However, existing unsupervised GCRL methods often struggle to cover a wide range of states in complex environments due to their limited exploration and sparse or noisy rewards for GCRL. To overcome these challenges, we propose a novel unsupervised GCRL method that leverages TemporaL Distance-aware Representations (TLDR). TLDR selects faraway goals to initiate exploration and computes intrinsic exploration rewards and goal-reaching rewards, based on temporal distance. Specifically, our exploration policy seeks states with large temporal distances (i.e. covering a large state space), while the goal-conditioned policy learns to minimize the temporal distance to the goal (i.e. reaching the goal). Our experimental results in six simulated robotic locomotion environments demonstrate that our method significantly outperforms previous unsupervised GCRL methods in achieving a wide variety of states.
Read more7/12/2024