Premier-TACO is a Few-Shot Policy Learner: Pretraining Multitask Representation via Temporal Action-Driven Contrastive Loss

0

Sign in to get full access
Overview
- This paper introduces Premier-TACO, a few-shot policy learning method that learns a versatile representation from pre-training on a diverse set of tasks.
- The key innovation is the use of a temporal action-driven contrastive loss, which encourages the model to learn representations that capture the temporal dynamics of actions.
- The authors show that this pretraining approach leads to improved few-shot learning performance on a variety of robotic manipulation tasks.
Plain English Explanation
Premier-TACO is a machine learning model that can quickly learn new skills by building on its prior experience. The researchers who created Premier-TACO trained it on a wide range of tasks, using a novel technique called "temporal action-driven contrastive loss" to help the model learn representations that capture the dynamics of different actions over time.
This pretraining process allows Premier-TACO to develop a versatile understanding of how actions unfold, which then gives it a head start when adapting to perform new tasks with only a few examples. For instance, if Premier-TACO has learned about grasping, pouring, and stirring actions through its pretraining, it can more easily learn a new task like flipping a pancake, since it already has some baseline knowledge about how manipulating objects evolves over time.
The key advantage of this approach is that it enables Premier-TACO to become a capable "few-shot" learner, meaning it can acquire new skills with just a small number of training examples. This is an important capability for real-world robotic systems that may encounter many novel tasks and cannot rely on extensive retraining for each new scenario.
Technical Explanation
Premier-TACO is a pretraining-based few-shot policy learning framework that learns a generalizable representation through multi-task training. The core innovation is the use of a temporal action-driven contrastive loss to encourage the model to capture the temporal dynamics of actions during the pretraining phase.
The authors leverage ideas from Action-Slot and E-MARL to design a pretraining pipeline that exposes the model to a diverse set of robotic manipulation tasks. The temporal action-driven contrastive loss aims to learn representations that can effectively distinguish between different types of actions and their evolution over time.
After pretraining, the authors fine-tune Premier-TACO on new few-shot tasks using a meta-learning approach. They demonstrate that this pretraining strategy leads to significant improvements in few-shot policy learning performance compared to baselines that do not leverage the temporal action-driven contrastive loss or multi-task pretraining.
Critical Analysis
The authors make a compelling case for the benefits of their temporal action-driven contrastive pretraining approach, which allows Premier-TACO to become a highly capable few-shot learner. However, the paper does not fully address potential limitations or caveats of this method.
For instance, the authors do not discuss the computational and memory requirements of the pretraining phase, which could be a concern for real-world deployment, especially on resource-constrained robotic platforms. Additionally, the paper focuses on a relatively narrow set of robotic manipulation tasks, and it's unclear how well the approach would generalize to more diverse or complex domains.
Furthermore, the authors do not provide a detailed analysis of the learned representations or the specific behaviors that enable Premier-TACO's strong few-shot learning performance. A deeper investigation into the inner workings of the model could yield valuable insights for improving few-shot learning methods in the future.
Conclusion
Premier-TACO demonstrates the power of pretraining with a temporal action-driven contrastive loss to develop versatile representations that facilitate few-shot policy learning. By exposing the model to a diverse set of tasks and explicitly learning to capture the dynamics of actions, Premier-TACO can quickly adapt to new scenarios with just a handful of examples.
This research advances the field of few-shot reinforcement learning, which is crucial for deploying capable robotic systems that can flexibly handle a wide range of tasks in the real world. While the paper leaves room for further investigation, Premier-TACO's impressive few-shot learning abilities highlight the potential of pretraining-based approaches to enable more adaptable and efficient AI agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Premier-TACO is a Few-Shot Policy Learner: Pretraining Multitask Representation via Temporal Action-Driven Contrastive Loss
Ruijie Zheng, Yongyuan Liang, Xiyao Wang, Shuang Ma, Hal Daum'e III, Huazhe Xu, John Langford, Praveen Palanisamy, Kalyan Shankar Basu, Furong Huang
We present Premier-TACO, a multitask feature representation learning approach designed to improve few-shot policy learning efficiency in sequential decision-making tasks. Premier-TACO leverages a subset of multitask offline datasets for pretraining a general feature representation, which captures critical environmental dynamics and is fine-tuned using minimal expert demonstrations. It advances the temporal action contrastive learning (TACO) objective, known for state-of-the-art results in visual control tasks, by incorporating a novel negative example sampling strategy. This strategy is crucial in significantly boosting TACO's computational efficiency, making large-scale multitask offline pretraining feasible. Our extensive empirical evaluation in a diverse set of continuous control benchmarks including Deepmind Control Suite, MetaWorld, and LIBERO demonstrate Premier-TACO's effectiveness in pretraining visual representations, significantly enhancing few-shot imitation learning of novel tasks. Our code, pretraining data, as well as pretrained model checkpoints will be released at https://github.com/PremierTACO/premier-taco. Our project webpage is at https://premiertaco.github.io.
Read more5/27/2024
🏅
0
TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning
Ruijie Zheng, Xiyao Wang, Yanchao Sun, Shuang Ma, Jieyu Zhao, Huazhe Xu, Hal Daum'e III, Furong Huang
Despite recent progress in reinforcement learning (RL) from raw pixel data, sample inefficiency continues to present a substantial obstacle. Prior works have attempted to address this challenge by creating self-supervised auxiliary tasks, aiming to enrich the agent's learned representations with control-relevant information for future state prediction. However, these objectives are often insufficient to learn representations that can represent the optimal policy or value function, and they often consider tasks with small, abstract discrete action spaces and thus overlook the importance of action representation learning in continuous control. In this paper, we introduce TACO: Temporal Action-driven Contrastive Learning, a simple yet powerful temporal contrastive learning approach that facilitates the concurrent acquisition of latent state and action representations for agents. TACO simultaneously learns a state and an action representation by optimizing the mutual information between representations of current states paired with action sequences and representations of the corresponding future states. Theoretically, TACO can be shown to learn state and action representations that encompass sufficient information for control, thereby improving sample efficiency. For online RL, TACO achieves 40% performance boost after one million environment interaction steps on average across nine challenging visual continuous control tasks from Deepmind Control Suite. In addition, we show that TACO can also serve as a plug-and-play module adding to existing offline visual RL methods to establish the new state-of-the-art performance for offline visual RL across offline datasets with varying quality.
Read more5/27/2024

0
Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation
Vivek Myers, Bill Chunyuan Zheng, Oier Mees, Sergey Levine, Kuan Fang
Learned language-conditioned robot policies often struggle to effectively adapt to new real-world tasks even when pre-trained across a diverse set of instructions. We propose a novel approach for few-shot adaptation to unseen tasks that exploits the semantic understanding of task decomposition provided by vision-language models (VLMs). Our method, Policy Adaptation via Language Optimization (PALO), combines a handful of demonstrations of a task with proposed language decompositions sampled from a VLM to quickly enable rapid nonparametric adaptation, avoiding the need for a larger fine-tuning dataset. We evaluate PALO on extensive real-world experiments consisting of challenging unseen, long-horizon robot manipulation tasks. We find that PALO is able of consistently complete long-horizon, multi-tier tasks in the real world, outperforming state of the art pre-trained generalist policies, and methods that have access to the same demonstrations.
Read more8/30/2024
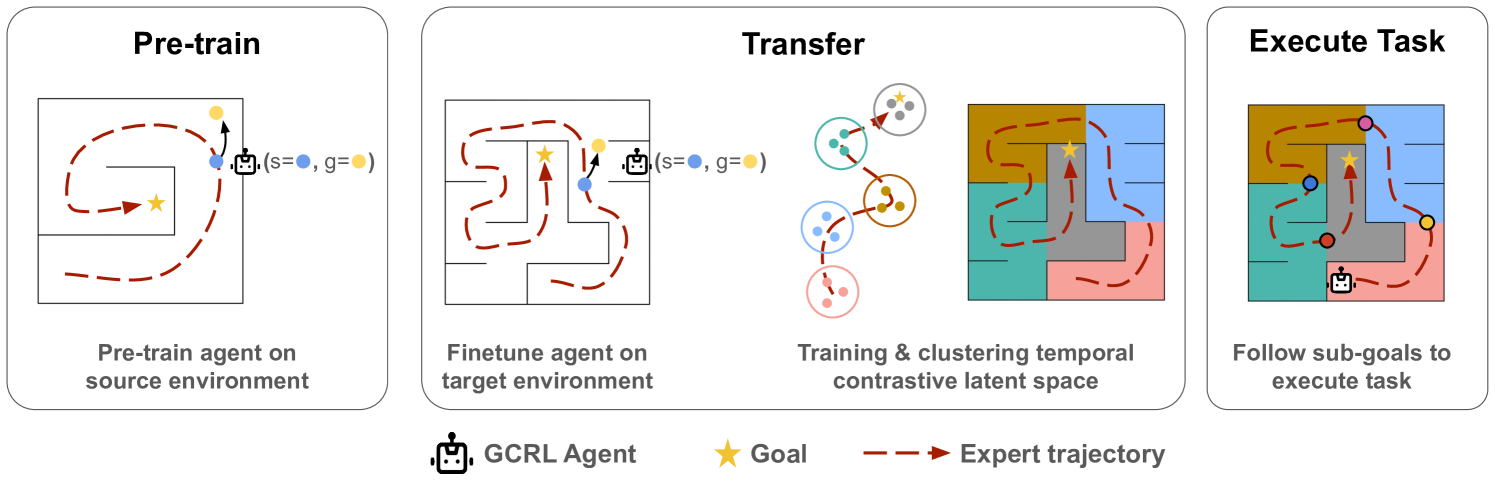
0
Multi-Agent Transfer Learning via Temporal Contrastive Learning
Weihao Zeng, Joseph Campbell, Simon Stepputtis, Katia Sycara
This paper introduces a novel transfer learning framework for deep multi-agent reinforcement learning. The approach automatically combines goal-conditioned policies with temporal contrastive learning to discover meaningful sub-goals. The approach involves pre-training a goal-conditioned agent, finetuning it on the target domain, and using contrastive learning to construct a planning graph that guides the agent via sub-goals. Experiments on multi-agent coordination Overcooked tasks demonstrate improved sample efficiency, the ability to solve sparse-reward and long-horizon problems, and enhanced interpretability compared to baselines. The results highlight the effectiveness of integrating goal-conditioned policies with unsupervised temporal abstraction learning for complex multi-agent transfer learning. Compared to state-of-the-art baselines, our method achieves the same or better performances while requiring only 21.7% of the training samples.
Read more6/4/2024