StatBot.Swiss: Bilingual Open Data Exploration in Natural Language

0

Sign in to get full access
Overview
• StatBot.Swiss is a bilingual (German and French) open data exploration system that allows users to interact with government data using natural language queries in their preferred language.
• The system leverages large language models to understand user queries, retrieve relevant data from open data sources, and generate informative responses in the user's language.
• Key features include the ability to handle complex queries, provide explanations of data and findings, and support data visualization.
Plain English Explanation
StatBot.Swiss is a tool that makes it easier for people to explore and understand government data. It uses advanced language models to understand questions asked in either German or French, and then it retrieves the relevant data and provides an explanation in the user's language.
So, for example, if you're a French speaker and you ask StatBot.Swiss a question about the unemployment rate in your region, it will understand your query, look up the data, and give you a response and explanation in French. The same goes for German speakers.
The system is designed to handle complex queries, not just simple lookups. It can explain the data, create visualizations, and generally make it easier for people to get insights from government information, even if they're not experts in data analysis.
This is particularly useful for citizens who want to stay informed about important issues but may not have the time or technical skills to dig through raw data themselves. StatBot.Swiss aims to make open data more accessible and useful for everyone.
Technical Explanation
StatBot.Swiss leverages large, pre-trained language models to power its natural language understanding and generation capabilities. When a user submits a query in German or French, the system first processes the text to extract the key information and intent.
It then retrieves relevant data from open government data sources, using techniques like semantic search to find the most appropriate datasets. The language model is then used to generate an informative response that explains the data and insights in the user's preferred language.
The system also supports data visualization, allowing users to see the information in graphical form. This is facilitated by integrating the language model with data visualization tools and libraries.
Overall, StatBot.Swiss demonstrates how large language models can be leveraged to enhance access and understanding of open government data, making it more useful for citizens and policymakers alike. It builds on related work in areas like multilingual chat datasets and benchmarking large language models across languages.
Critical Analysis
The paper provides a compelling proof-of-concept for StatBot.Swiss, but it also acknowledges several limitations and areas for further research. For example, the current system is limited to a specific set of open data sources, and expanding its coverage to a wider range of datasets and domains would be an important next step.
Additionally, the authors note that the language model's performance may degrade when handling very complex or technical queries, and further work is needed to improve its robustness and accuracy in such cases. There are also potential concerns around bias and fairness that should be carefully considered as the system is developed further.
Overall, while StatBot.Swiss represents an exciting step forward in making government data more accessible, there is still room for improvement and further research. Ongoing benchmarking of large language models and exploring how they can be better integrated with spoken language understanding will be crucial for realizing the full potential of systems like this.
Conclusion
StatBot.Swiss demonstrates how large language models can be leveraged to create bilingual, natural language-driven tools for exploring open government data. By making it easier for citizens to access and understand important information, the system has the potential to improve transparency, civic engagement, and data-driven decision-making.
As the field of natural language processing continues to advance, we can expect to see more innovative applications like StatBot.Swiss that bridge the gap between complex data and the general public. This could have far-reaching implications for how citizens interact with and participate in their government.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
StatBot.Swiss: Bilingual Open Data Exploration in Natural Language
Farhad Nooralahzadeh, Yi Zhang, Ellery Smith, Sabine Maennel, Cyril Matthey-Doret, Raphael de Fondville, Kurt Stockinger
The potential for improvements brought by Large Language Models (LLMs) in Text-to-SQL systems is mostly assessed on monolingual English datasets. However, LLMs' performance for other languages remains vastly unexplored. In this work, we release the StatBot.Swiss dataset, the first bilingual benchmark for evaluating Text-to-SQL systems based on real-world applications. The StatBot.Swiss dataset contains 455 natural language/SQL-pairs over 35 big databases with varying level of complexity for both English and German. We evaluate the performance of state-of-the-art LLMs such as GPT-3.5-Turbo and mixtral-8x7b-instruct for the Text-to-SQL translation task using an in-context learning approach. Our experimental analysis illustrates that current LLMs struggle to generalize well in generating SQL queries on our novel bilingual dataset.
Read more6/7/2024
0
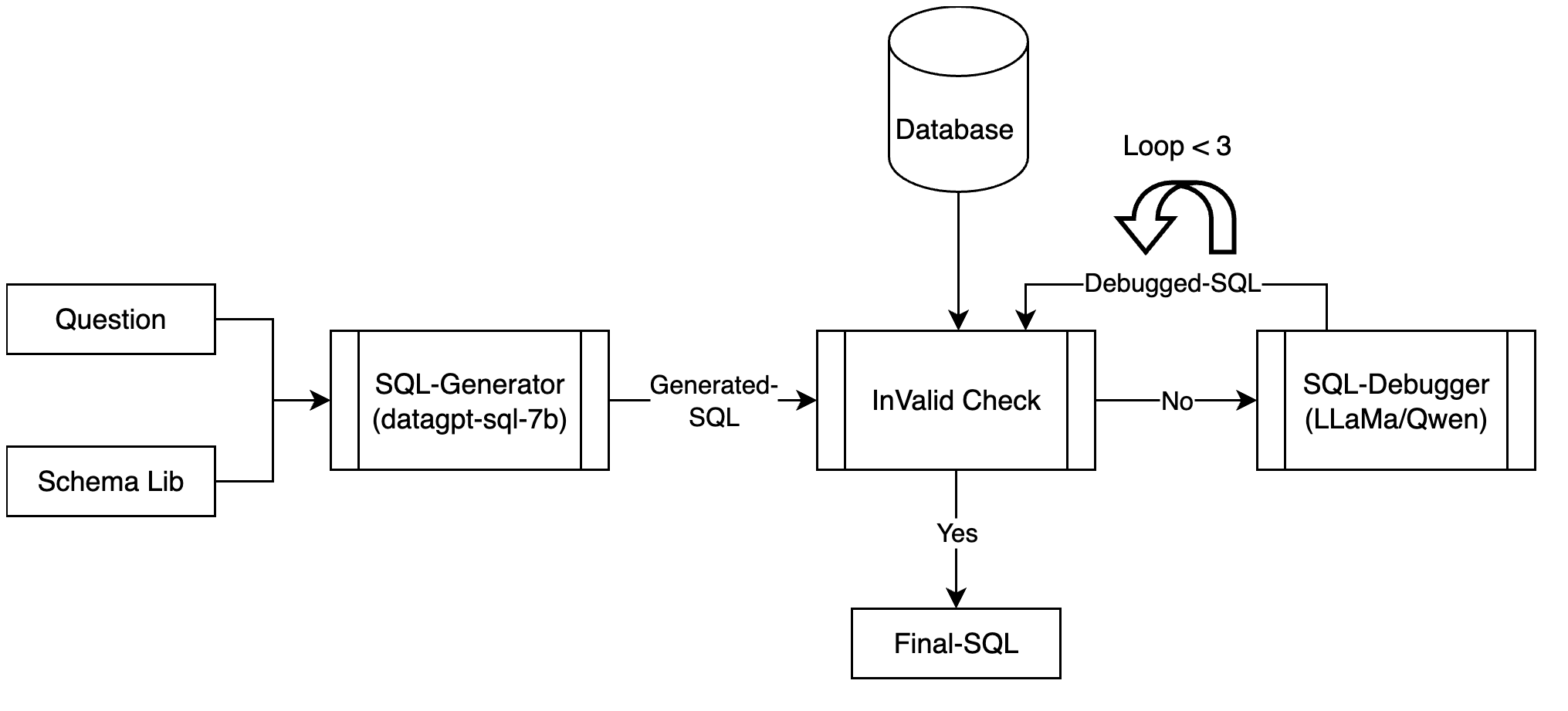
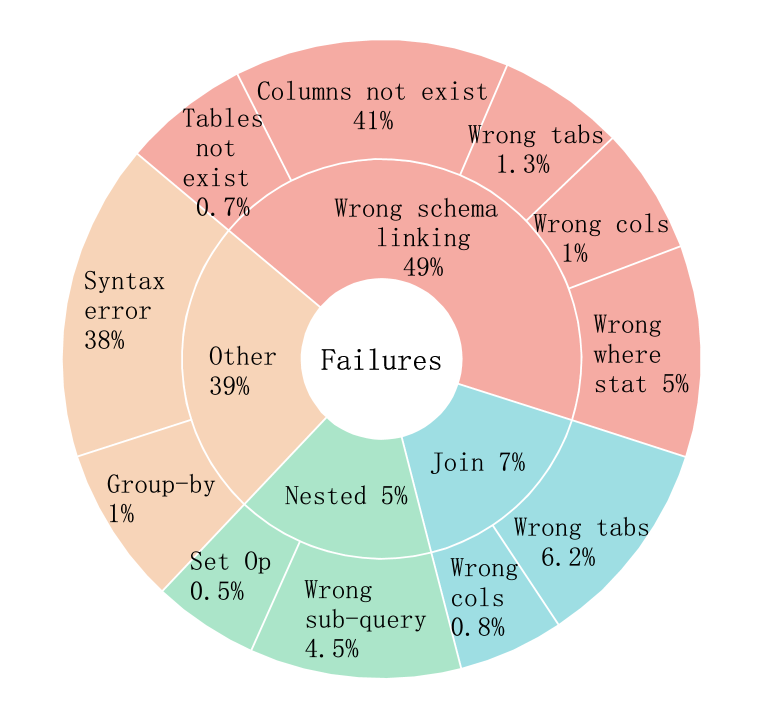
DataGpt-SQL-7B: An Open-Source Language Model for Text-to-SQL
Lixia Wu, Peng Li, Junhong Lou, Lei Fu
In addressing the pivotal role of translating natural language queries into SQL commands, we propose a suite of compact, fine-tuned models and self-refine mechanisms to democratize data access and analysis for non-expert users, mitigating risks associated with closed-source Large Language Models. Specifically, we constructed a dataset of over 20K sample for Text-to-SQL as well as the preference dateset, to improve the efficiency in the domain of SQL generation. To further ensure code validity, a code corrector was integrated into the model. Our system, DataGpt-sql, achieved 87.2% accuracy on the spider-dev, respectively, showcasing the effectiveness of our solution in text-to-SQL conversion tasks. Our code, data, and models are available at url{https://github.com/CainiaoTechAi/datagpt-sql-7b}
Read more9/25/2024
0
Open-SQL Framework: Enhancing Text-to-SQL on Open-source Large Language Models
Xiaojun Chen, Tianle Wang, Tianhao Qiu, Jianbin Qin, Min Yang
Despite the success of large language models (LLMs) in Text-to-SQL tasks, open-source LLMs encounter challenges in contextual understanding and response coherence. To tackle these issues, we present ours, a systematic methodology tailored for Text-to-SQL with open-source LLMs. Our contributions include a comprehensive evaluation of open-source LLMs in Text-to-SQL tasks, the openprompt strategy for effective question representation, and novel strategies for supervised fine-tuning. We explore the benefits of Chain-of-Thought in step-by-step inference and propose the openexample method for enhanced few-shot learning. Additionally, we introduce token-efficient techniques, such as textbf{Variable-length Open DB Schema}, textbf{Target Column Truncation}, and textbf{Example Column Truncation}, addressing challenges in large-scale databases. Our findings emphasize the need for further investigation into the impact of supervised fine-tuning on contextual learning capabilities. Remarkably, our method significantly improved Llama2-7B from 2.54% to 41.04% and Code Llama-7B from 14.54% to 48.24% on the BIRD-Dev dataset. Notably, the performance of Code Llama-7B surpassed GPT-4 (46.35%) on the BIRD-Dev dataset.
Read more5/14/2024

0
A Survey on Employing Large Language Models for Text-to-SQL Tasks
Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, Zhi Yang
The increasing volume of data stored in relational databases has led to the need for efficient querying and utilization of this data in various sectors. However, writing SQL queries requires specialized knowledge, which poses a challenge for non-professional users trying to access and query databases. Text-to-SQL parsing solves this issue by converting natural language queries into SQL queries, thus making database access more accessible for non-expert users. To take advantage of the recent developments in Large Language Models (LLMs), a range of new methods have emerged, with a primary focus on prompt engineering and fine-tuning. This survey provides a comprehensive overview of LLMs in text-to-SQL tasks, discussing benchmark datasets, prompt engineering, fine-tuning methods, and future research directions. We hope this review will enable readers to gain a broader understanding of the recent advances in this field and offer some insights into its future trajectory.
Read more9/10/2024