Tailoring Instructions to Student's Learning Levels Boosts Knowledge Distillation
2305.09651
0
0
🎯
Abstract
It has been commonly observed that a teacher model with superior performance does not necessarily result in a stronger student, highlighting a discrepancy between current teacher training practices and effective knowledge transfer. In order to enhance the guidance of the teacher training process, we introduce the concept of distillation influence to determine the impact of distillation from each training sample on the student's generalization ability. In this paper, we propose Learning Good Teacher Matters (LGTM), an efficient training technique for incorporating distillation influence into the teacher's learning process. By prioritizing samples that are likely to enhance the student's generalization ability, our LGTM outperforms 10 common knowledge distillation baselines on 6 text classification tasks in the GLUE benchmark.
Create account to get full access
Overview
- A common observation is that a high-performing teacher model does not necessarily lead to a stronger student model, indicating a mismatch between current teacher training practices and effective knowledge transfer.
- To address this, the paper introduces the concept of "distillation influence" to measure the impact of each training sample on the student's generalization ability.
- The authors propose a training technique called Learning Good Teacher Matters (LGTM) that incorporates distillation influence to prioritize samples that are likely to improve the student's performance.
- LGTM outperforms 10 common knowledge distillation baselines on 6 text classification tasks in the GLUE benchmark.
Plain English Explanation
When a teacher is highly skilled, it doesn't always mean their students will learn the material as well as expected. The paper explores this discrepancy and introduces a new concept called "distillation influence" to understand how each training sample impacts the student's ability to generalize the knowledge.
The researchers propose a training technique called Learning Good Teacher Matters (LGTM) that focuses on prioritizing the training samples that are most likely to help the student perform better. By doing this, LGTM outperforms 10 other common knowledge distillation methods on 6 different text classification tasks.
Imagine a highly experienced teacher who is an expert in a subject. Even though they have deep knowledge, they may struggle to effectively communicate and transfer that knowledge to their students. LGTM aims to address this challenge by identifying the most impactful teaching methods and prioritizing them during the teacher's training process.
Technical Explanation
The paper introduces the concept of "distillation influence" to measure the impact of each training sample on the student's generalization ability. This allows the researchers to identify the samples that are most beneficial for the student's learning.
The LGTM training technique incorporates this distillation influence metric into the teacher's learning process, prioritizing the samples that are likely to enhance the student's performance. This is in contrast to common knowledge distillation baselines that do not explicitly consider the student's generalization ability during teacher training.
The authors evaluate LGTM on 6 text classification tasks from the GLUE benchmark and show that it outperforms the 10 baseline methods. This suggests that focusing on the student's learning outcomes, rather than just the teacher's performance, can lead to more effective knowledge transfer.
Critical Analysis
The paper provides a novel approach to teacher training by introducing the concept of distillation influence and using it to guide the training process. However, there are a few potential limitations and areas for further research:
- The experiments are limited to text classification tasks, so it's unclear how well the LGTM technique would generalize to other domains, such as sequential recommendation systems or token-level tasks.
- The paper does not explore the computational overhead or training time required for the LGTM method, which could be an important consideration for practical applications.
- The researchers could investigate the robustness of LGTM to different teacher model architectures or the impact of the student model's capacity on the effectiveness of the approach.
Overall, the paper presents an interesting and promising direction for improving knowledge distillation by focusing on the student's learning outcomes during the teacher training process.
Conclusion
This paper introduces a novel concept called "distillation influence" to measure the impact of each training sample on the student's generalization ability. Based on this, the authors propose the LGTM training technique that prioritizes the samples most likely to enhance the student's performance.
The results show that LGTM outperforms 10 common knowledge distillation baselines on 6 text classification tasks, suggesting that optimizing the teacher training process for the student's learning outcomes can lead to more effective knowledge transfer. This approach could have significant implications for improving the efficiency and effectiveness of various AI models and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
0
0
How to conduct teacher training for knowledge distillation is still an open problem. It has been widely observed that a best-performing teacher does not necessarily yield the best-performing student, suggesting a fundamental discrepancy between the current teacher training practice and the ideal teacher training strategy. To fill this gap, we explore the feasibility of training a teacher that is oriented toward student performance with empirical risk minimization (ERM). Our analyses are inspired by the recent findings that the effectiveness of knowledge distillation hinges on the teacher's capability to approximate the true label distribution of training inputs. We theoretically establish that the ERM minimizer can approximate the true label distribution of training data as long as the feature extractor of the learner network is Lipschitz continuous and is robust to feature transformations. In light of our theory, we propose a teacher training method SoTeacher which incorporates Lipschitz regularization and consistency regularization into ERM. Experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs confirm that SoTeacher can improve student accuracy consistently.
5/10/2024

Teaching-Assistant-in-the-Loop: Improving Knowledge Distillation from Imperfect Teacher Models in Low-Budget Scenarios
Yuhang Zhou, Wei Ai
0
0
There is increasing interest in distilling task-specific knowledge from large language models (LLM) to smaller student models. Nonetheless, LLM distillation presents a dual challenge: 1) there is a high cost associated with querying the teacher LLM, such as GPT-4, for gathering an ample number of demonstrations; 2) the teacher LLM might provide imperfect outputs with a negative impact on the student's learning process. To enhance sample efficiency within resource-constrained, imperfect teacher scenarios, we propose a three-component framework leveraging three signal types. The first signal is the student's self-consistency (consistency of student multiple outputs), which is a proxy of the student's confidence. Specifically, we introduce a ``teaching assistant'' (TA) model to assess the uncertainty of both the student's and the teacher's outputs via confidence scoring, which serves as another two signals for student training. Furthermore, we propose a two-stage training schema to first warm up the student with a small proportion of data to better utilize student's signal. Experiments have shown the superiority of our proposed framework for four complex reasoning tasks. On average, our proposed two-stage framework brings a relative improvement of up to 20.79% compared to fine-tuning without any signals across datasets.
6/11/2024
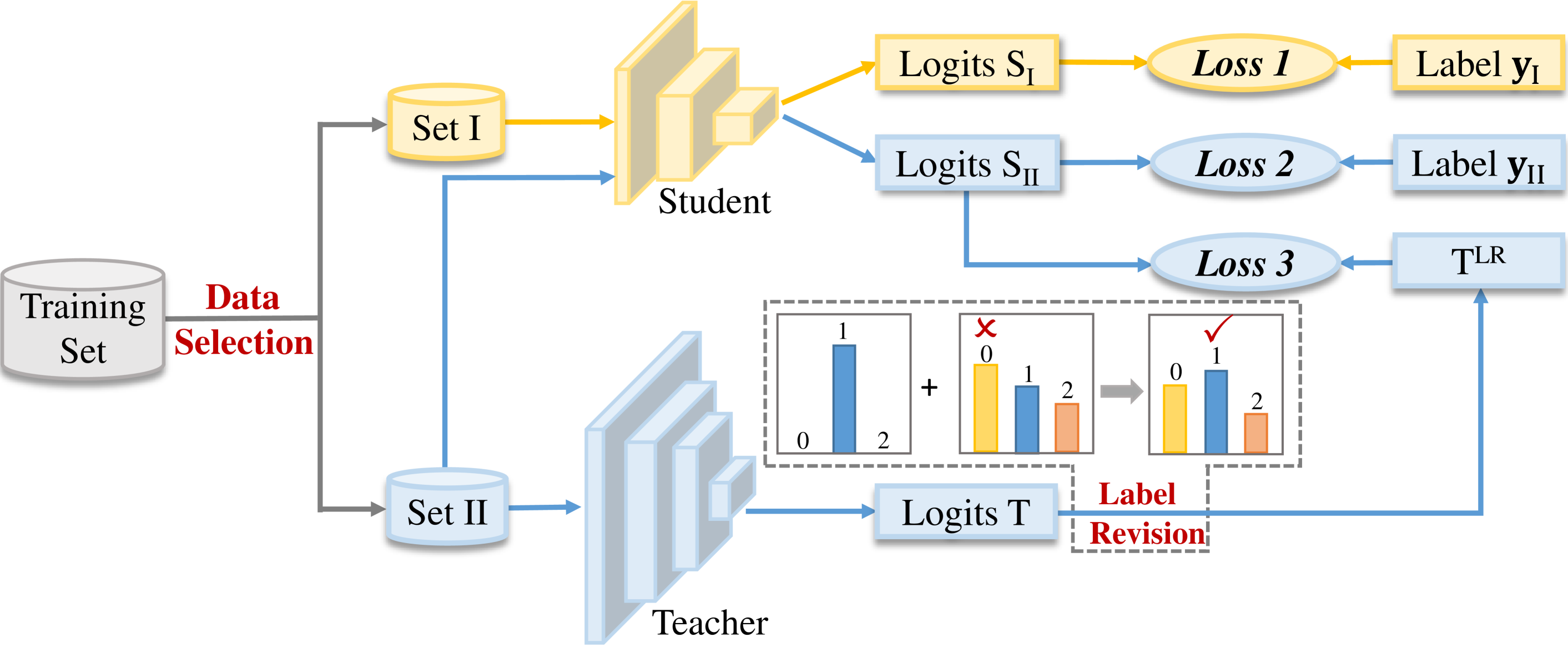
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024
💬
Sentence-Level or Token-Level? A Comprehensive Study on Knowledge Distillation
Jingxuan Wei, Linzhuang Sun, Yichong Leng, Xu Tan, Bihui Yu, Ruifeng Guo
0
0
Knowledge distillation, transferring knowledge from a teacher model to a student model, has emerged as a powerful technique in neural machine translation for compressing models or simplifying training targets. Knowledge distillation encompasses two primary methods: sentence-level distillation and token-level distillation. In sentence-level distillation, the student model is trained to align with the output of the teacher model, which can alleviate the training difficulty and give student model a comprehensive understanding of global structure. Differently, token-level distillation requires the student model to learn the output distribution of the teacher model, facilitating a more fine-grained transfer of knowledge. Studies have revealed divergent performances between sentence-level and token-level distillation across different scenarios, leading to the confusion on the empirical selection of knowledge distillation methods. In this study, we argue that token-level distillation, with its more complex objective (i.e., distribution), is better suited for ``simple'' scenarios, while sentence-level distillation excels in ``complex'' scenarios. To substantiate our hypothesis, we systematically analyze the performance of distillation methods by varying the model size of student models, the complexity of text, and the difficulty of decoding procedure. While our experimental results validate our hypothesis, defining the complexity level of a given scenario remains a challenging task. So we further introduce a novel hybrid method that combines token-level and sentence-level distillation through a gating mechanism, aiming to leverage the advantages of both individual methods. Experiments demonstrate that the hybrid method surpasses the performance of token-level or sentence-level distillation methods and the previous works by a margin, demonstrating the effectiveness of the proposed hybrid method.
4/24/2024