TART: Boosting Clean Accuracy Through Tangent Direction Guided Adversarial Training

0
Sign in to get full access
Overview
- This paper proposes a novel adversarial training method called TART (Tangent Direction Guided Adversarial Training) to improve the clean accuracy of deep neural networks.
- TART leverages the tangent space of the data manifold to generate informative adversarial perturbations, guiding the model to learn more robust features.
- The authors demonstrate that TART can outperform state-of-the-art adversarial training methods on various image classification tasks.
Plain English Explanation
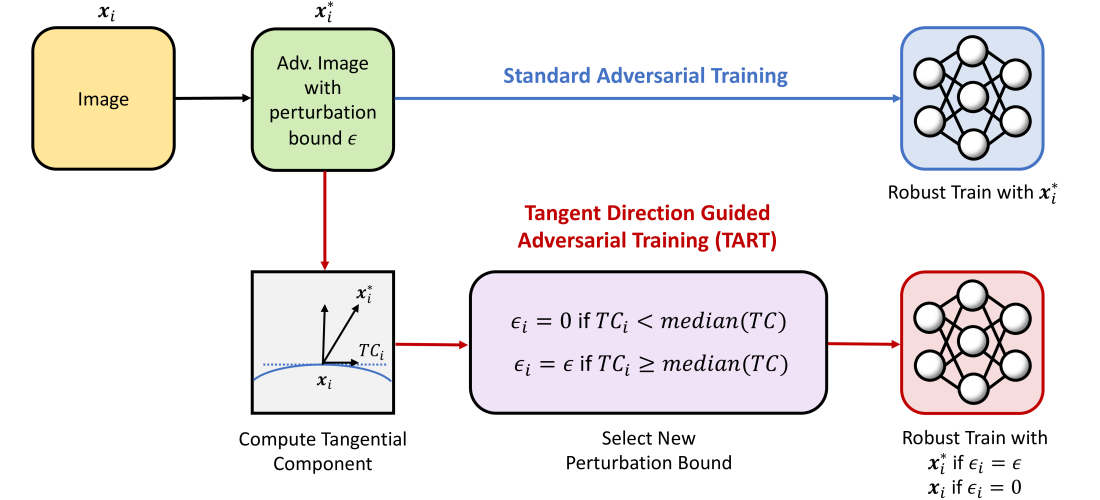
The main idea behind TART is to use the tangent space of the data manifold to generate more informative adversarial perturbations during the training process. The tangent space represents the local directions in which the data can be slightly modified without significantly changing the underlying class.
By aligning the adversarial perturbations with the tangent space, the model is encouraged to learn features that are more robust to small, meaningful changes in the input, rather than focusing on brittle, high-frequency patterns that may be sensitive to adversarial attacks.
This approach helps to boost the clean accuracy (the model's performance on unmodified, "clean" data) of the deep neural network, while still maintaining strong adversarial robustness. The authors show that TART outperforms other state-of-the-art adversarial training methods across multiple image classification tasks.
Technical Explanation
The authors propose a new adversarial training method called TART (Tangent Direction Guided Adversarial Training). TART leverages the tangent space of the data manifold to generate informative adversarial perturbations during the training process.
The tangent space represents the local directions in which the data can be slightly modified without significantly changing the underlying class. By aligning the adversarial perturbations with the tangent space, the model is encouraged to learn features that are more robust to small, meaningful changes in the input, rather than focusing on brittle, high-frequency patterns that may be sensitive to adversarial attacks.
The authors demonstrate that TART can outperform state-of-the-art adversarial training methods, such as Madry et al. and Xie et al., on various image classification tasks. The key insights from the technical approach include:
- Tangent Space Estimation: The authors propose a method to efficiently estimate the tangent space of the data manifold, which is a critical component of the TART algorithm.
- Tangent Direction Guided Adversarial Perturbations: The adversarial perturbations generated during training are aligned with the estimated tangent space, guiding the model to learn more robust features.
- Robust and Accurate Model Learning: The combination of tangent space-guided adversarial training and standard training on clean data allows the model to achieve high clean accuracy while maintaining strong adversarial robustness.
Critical Analysis
The authors acknowledge several limitations and areas for further research in the paper:
- Computational Complexity: The tangent space estimation process can be computationally expensive, especially for large-scale datasets. The authors mention that more efficient tangent space estimation methods could be explored to reduce the overall computational burden.
- Generalization to Other Domains: While the authors demonstrate the effectiveness of TART on image classification tasks, it would be valuable to investigate the performance of this approach in other domains, such as natural language processing or speech recognition.
- Theoretical Understanding: The paper provides empirical evidence for the effectiveness of TART, but a deeper theoretical understanding of the relationship between the tangent space and adversarial robustness could further strengthen the insights and guide future research.
Additionally, one could consider the following potential issues or areas for further exploration:
- Sensitivity to Hyperparameter Tuning: The performance of adversarial training methods, including TART, can be sensitive to the choice of hyperparameters. A more thorough investigation of the hyperparameter sensitivity and its impact on the results would be informative.
- Transferability to Real-World Attacks: While the paper focuses on evaluating the performance against standard white-box adversarial attacks, it would be valuable to assess the model's robustness against more realistic, practical attack scenarios, such as black-box or physical-world attacks.
Overall, the TART method represents an interesting and promising approach to improving the clean accuracy of deep neural networks while maintaining strong adversarial robustness. The critical analysis highlights areas for further research and refinement to strengthen the practical applicability and theoretical understanding of this technique.
Conclusion
The TART (Tangent Direction Guided Adversarial Training) method proposed in this paper offers a novel approach to improving the clean accuracy of deep neural networks without compromising their adversarial robustness. By leveraging the tangent space of the data manifold to generate informative adversarial perturbations, TART encourages the model to learn more robust features that are resilient to small, meaningful changes in the input.
The authors' empirical results demonstrate the effectiveness of TART in outperforming state-of-the-art adversarial training methods on various image classification tasks. While the paper highlights some limitations and areas for further research, the core ideas behind TART represent an important contribution to the field of adversarial defense and robust machine learning. As the research community continues to explore ways to build reliable and trustworthy AI systems, techniques like TART may play a crucial role in addressing the accuracy-robustness trade-off and advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TART: Boosting Clean Accuracy Through Tangent Direction Guided Adversarial Training
Bongsoo Yi, Rongjie Lai, Yao Li
Adversarial training has been shown to be successful in enhancing the robustness of deep neural networks against adversarial attacks. However, this robustness is accompanied by a significant decline in accuracy on clean data. In this paper, we propose a novel method, called Tangent Direction Guided Adversarial Training (TART), that leverages the tangent space of the data manifold to ameliorate the existing adversarial defense algorithms. We argue that training with adversarial examples having large normal components significantly alters the decision boundary and hurts accuracy. TART mitigates this issue by estimating the tangent direction of adversarial examples and allocating an adaptive perturbation limit according to the norm of their tangential component. To the best of our knowledge, our paper is the first work to consider the concept of tangent space and direction in the context of adversarial defense. We validate the effectiveness of TART through extensive experiments on both simulated and benchmark datasets. The results demonstrate that TART consistently boosts clean accuracy while retaining a high level of robustness against adversarial attacks. Our findings suggest that incorporating the geometric properties of data can lead to more effective and efficient adversarial training methods.
Read more8/28/2024
🖼️
0
Tangent Transformers for Composition, Privacy and Removal
Tian Yu Liu, Aditya Golatkar, Stefano Soatto
We introduce Tangent Attention Fine-Tuning (TAFT), a method for fine-tuning linearized transformers obtained by computing a First-order Taylor Expansion around a pre-trained initialization. We show that the Jacobian-Vector Product resulting from linearization can be computed efficiently in a single forward pass, reducing training and inference cost to the same order of magnitude as its original non-linear counterpart, while using the same number of parameters. Furthermore, we show that, when applied to various downstream visual classification tasks, the resulting Tangent Transformer fine-tuned with TAFT can perform comparably with fine-tuning the original non-linear network. Since Tangent Transformers are linear with respect to the new set of weights, and the resulting fine-tuning loss is convex, we show that TAFT enjoys several advantages compared to non-linear fine-tuning when it comes to model composition, parallel training, machine unlearning, and differential privacy. Our code is available at: https://github.com/tianyu139/tangent-model-composition
Read more5/16/2024

0
Mitigating Accuracy-Robustness Trade-off via Balanced Multi-Teacher Adversarial Distillation
Shiji Zhao, Xizhe Wang, Xingxing Wei
Adversarial Training is a practical approach for improving the robustness of deep neural networks against adversarial attacks. Although bringing reliable robustness, the performance towards clean examples is negatively affected after Adversarial Training, which means a trade-off exists between accuracy and robustness. Recently, some studies have tried to use knowledge distillation methods in Adversarial Training, achieving competitive performance in improving the robustness but the accuracy for clean samples is still limited. In this paper, to mitigate the accuracy-robustness trade-off, we introduce the Balanced Multi-Teacher Adversarial Robustness Distillation (B-MTARD) to guide the model's Adversarial Training process by applying a strong clean teacher and a strong robust teacher to handle the clean examples and adversarial examples, respectively. During the optimization process, to ensure that different teachers show similar knowledge scales, we design the Entropy-Based Balance algorithm to adjust the teacher's temperature and keep the teachers' information entropy consistent. Besides, to ensure that the student has a relatively consistent learning speed from multiple teachers, we propose the Normalization Loss Balance algorithm to adjust the learning weights of different types of knowledge. A series of experiments conducted on three public datasets demonstrate that B-MTARD outperforms the state-of-the-art methods against various adversarial attacks.
Read more6/18/2024
🏋️
0
Topology-preserving Adversarial Training for Alleviating Natural Accuracy Degradation
Xiaoyue Mi, Fan Tang, Yepeng Weng, Danding Wang, Juan Cao, Sheng Tang, Peng Li, Yang Liu
Despite the effectiveness in improving the robustness of neural networks, adversarial training has suffered from the natural accuracy degradation problem, i.e., accuracy on natural samples has reduced significantly. In this study, we reveal that natural accuracy degradation is highly related to the disruption of the natural sample topology in the representation space by quantitative and qualitative experiments. Based on this observation, we propose Topology-pReserving Adversarial traINing (TRAIN) to alleviate the problem by preserving the topology structure of natural samples from a standard model trained only on natural samples during adversarial training. As an additional regularization, our method can be combined with various popular adversarial training algorithms, taking advantage of both sides. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny ImageNet show that our proposed method achieves consistent and significant improvements over various strong baselines in most cases. Specifically, without additional data, TRAIN achieves up to 8.86% improvement in natural accuracy and 6.33% improvement in robust accuracy.
Read more8/20/2024