Tangent Transformers for Composition, Privacy and Removal

0
🖼️
Sign in to get full access
Overview
- The authors introduce Tangent Attention Fine-Tuning (TAFT), a method for fine-tuning linearized transformers
- TAFT computes a First-order Taylor Expansion around a pre-trained initialization to obtain a linearized transformer
- The resulting Jacobian-Vector Product can be computed efficiently in a single forward pass, reducing training and inference cost
- TAFT allows the resulting Tangent Transformer to perform comparably to fine-tuning the original non-linear network
- Tangent Transformers are linear with respect to the new set of weights, and the resulting fine-tuning loss is convex, providing advantages for model composition, parallel training, machine unlearning, and differential privacy
Plain English Explanation
The paper introduces a new method called Tangent Attention Fine-Tuning (TAFT) that can be used to fine-tune pre-trained transformer models. Transformers are a popular type of neural network architecture that have been very successful for a variety of tasks like language modeling and image classification.
The key idea behind TAFT is to linearize the transformer model by computing a first-order Taylor expansion around the pre-trained model's parameters. This results in a "Tangent Transformer" that is a linear function of the new set of weights. The authors show that the Jacobian-Vector Product, which is the key computation needed for fine-tuning the model, can be calculated efficiently in a single forward pass.
This has a few benefits. First, the training and inference time for the fine-tuned model is on par with the original non-linear transformer, despite the model being linear. Second, the fine-tuning loss is convex, which provides advantages for things like model composition, parallel training, machine unlearning, and differential privacy.
Overall, TAFT provides an efficient way to fine-tune transformer models that retains the performance of the original non-linear model while offering some additional benefits in terms of the optimization landscape.
Technical Explanation
The core technical contribution of this paper is the Tangent Attention Fine-Tuning (TAFT) method for fine-tuning linearized transformers. The authors start by computing a first-order Taylor expansion around the pre-trained initialization of a transformer model, resulting in a "Tangent Transformer" that is a linear function of the new set of weights.
They show that the key Jacobian-Vector Product computation needed for fine-tuning can be calculated efficiently in a single forward pass, reducing the training and inference cost of the fine-tuned model to the same order of magnitude as the original non-linear transformer, while using the same number of parameters.
When applying TAFT to various downstream visual classification tasks, the authors demonstrate that the resulting Tangent Transformer can perform comparably to fine-tuning the original non-linear transformer network. Crucially, since the Tangent Transformer is linear with respect to the new set of weights, and the fine-tuning loss is convex, the authors show that TAFT enjoys several advantages compared to non-linear fine-tuning. These include benefits for model composition, parallel training, machine unlearning, and differential privacy.
Critical Analysis
The authors present a thorough and well-designed study, with extensive experiments across multiple datasets and tasks. The core technical insight of leveraging a linearized transformer model for efficient fine-tuning is novel and compelling.
One potential limitation is that the experiments are focused on visual classification tasks, so it's unclear how well the TAFT approach would generalize to other domains like natural language processing. The authors acknowledge this and suggest exploring additional application areas as future work.
Another potential concern is the reliance on the first-order Taylor expansion approximation. While the authors show that this approximation works well in practice, it would be valuable to understand the failure modes or limitations of this approach, especially as the fine-tuning diverges from the pre-trained initialization.
Finally, the advantages of TAFT for model composition, parallel training, machine unlearning, and differential privacy are interesting, but the authors could provide more detailed analysis and examples to fully substantiate these claims.
Overall, the TAFT method represents an innovative approach to fine-tuning transformer models, with a strong theoretical foundation and promising empirical results. Further exploration of its generalization and potential limitations would be valuable contributions to the field.
Conclusion
The Tangent Attention Fine-Tuning (TAFT) method introduced in this paper provides an efficient way to fine-tune pre-trained transformer models. By linearizing the transformer architecture through a first-order Taylor expansion, the authors show that the fine-tuning process can be accelerated without sacrificing performance compared to fine-tuning the original non-linear model.
The key benefits of TAFT include reduced training and inference costs, a convex fine-tuning loss function, and advantages for model composition, parallel training, machine unlearning, and differential privacy. These properties make TAFT a compelling approach for fine-tuning transformers, especially in resource-constrained or privacy-sensitive applications.
Overall, this work represents an important contribution to the ongoing research on improving the efficiency and flexibility of transformer-based models. As the use of transformers continues to expand across a wide range of domains, techniques like TAFT will become increasingly valuable for enabling rapid adaptation and deployment of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Tangent Transformers for Composition, Privacy and Removal
Tian Yu Liu, Aditya Golatkar, Stefano Soatto
We introduce Tangent Attention Fine-Tuning (TAFT), a method for fine-tuning linearized transformers obtained by computing a First-order Taylor Expansion around a pre-trained initialization. We show that the Jacobian-Vector Product resulting from linearization can be computed efficiently in a single forward pass, reducing training and inference cost to the same order of magnitude as its original non-linear counterpart, while using the same number of parameters. Furthermore, we show that, when applied to various downstream visual classification tasks, the resulting Tangent Transformer fine-tuned with TAFT can perform comparably with fine-tuning the original non-linear network. Since Tangent Transformers are linear with respect to the new set of weights, and the resulting fine-tuning loss is convex, we show that TAFT enjoys several advantages compared to non-linear fine-tuning when it comes to model composition, parallel training, machine unlearning, and differential privacy. Our code is available at: https://github.com/tianyu139/tangent-model-composition
Read more5/16/2024
0
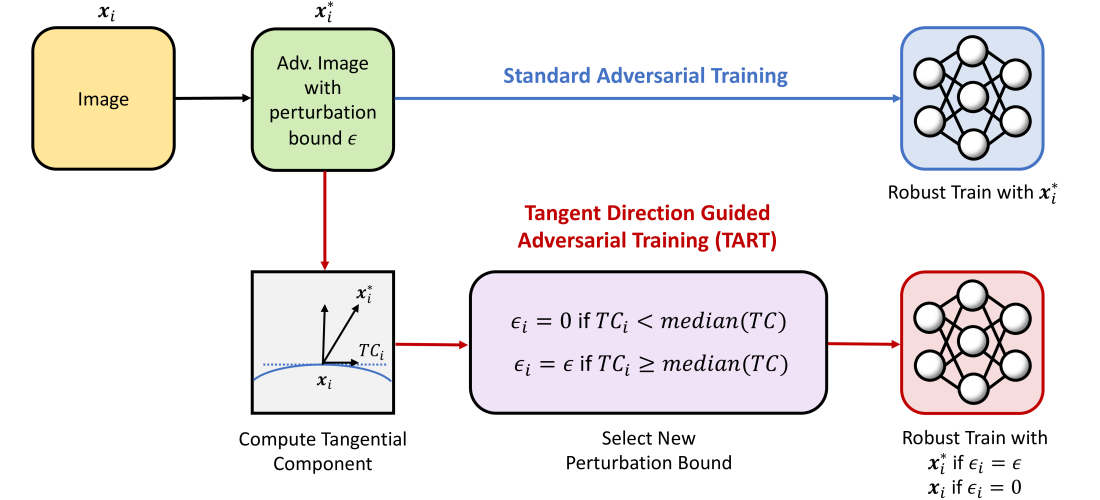
TART: Boosting Clean Accuracy Through Tangent Direction Guided Adversarial Training
Bongsoo Yi, Rongjie Lai, Yao Li
Adversarial training has been shown to be successful in enhancing the robustness of deep neural networks against adversarial attacks. However, this robustness is accompanied by a significant decline in accuracy on clean data. In this paper, we propose a novel method, called Tangent Direction Guided Adversarial Training (TART), that leverages the tangent space of the data manifold to ameliorate the existing adversarial defense algorithms. We argue that training with adversarial examples having large normal components significantly alters the decision boundary and hurts accuracy. TART mitigates this issue by estimating the tangent direction of adversarial examples and allocating an adaptive perturbation limit according to the norm of their tangential component. To the best of our knowledge, our paper is the first work to consider the concept of tangent space and direction in the context of adversarial defense. We validate the effectiveness of TART through extensive experiments on both simulated and benchmark datasets. The results demonstrate that TART consistently boosts clean accuracy while retaining a high level of robustness against adversarial attacks. Our findings suggest that incorporating the geometric properties of data can lead to more effective and efficient adversarial training methods.
Read more8/28/2024
0
Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution
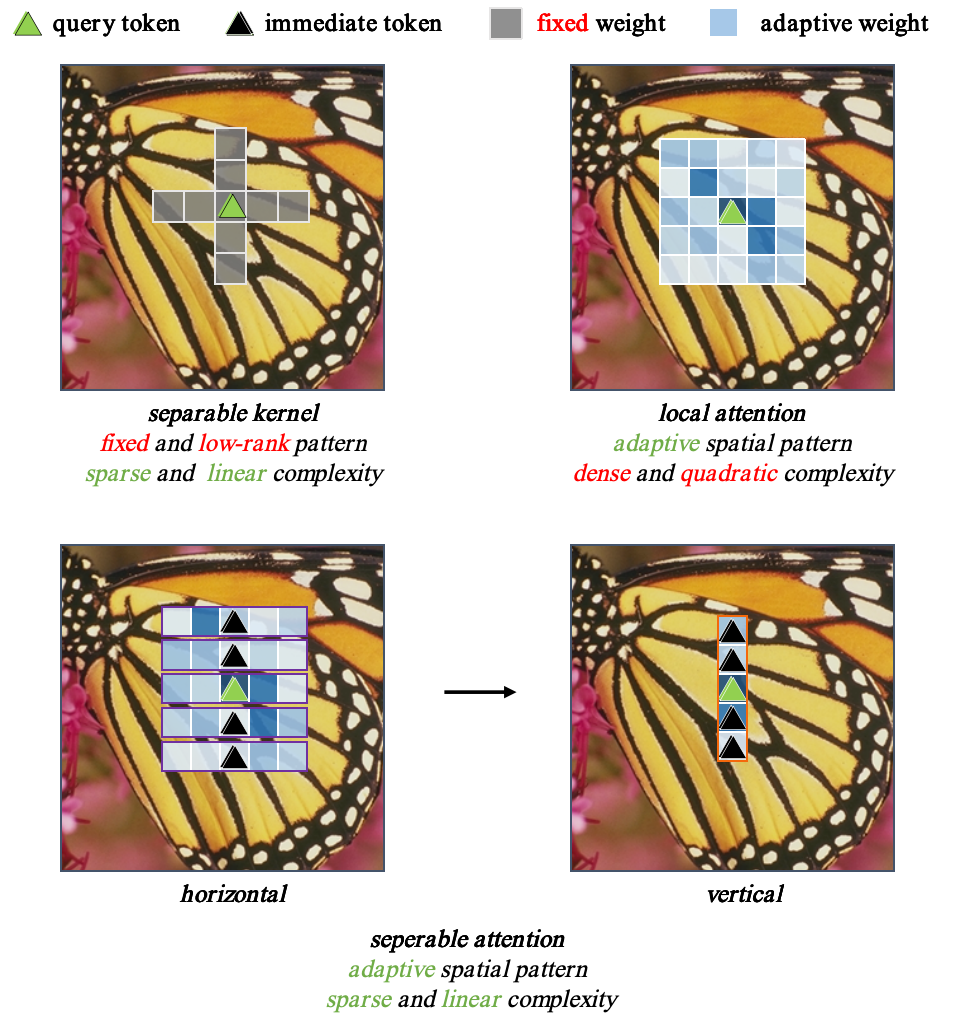
Zhenyu Hu, Wanjie Sun
Window-based transformers have demonstrated outstanding performance in super-resolution tasks due to their adaptive modeling capabilities through local self-attention (SA). However, they exhibit higher computational complexity and inference latency than convolutional neural networks. In this paper, we first identify that the adaptability of the Transformers is derived from their adaptive spatial aggregation and advanced structural design, while their high latency results from the computational costs and memory layout transformations associated with the local SA. To simulate this aggregation approach, we propose an effective convolution-based linear focal separable attention (FSA), allowing for long-range dynamic modeling with linear complexity. Additionally, we introduce an effective dual-branch structure combined with an ultra-lightweight information exchange module (IEM) to enhance the aggregation of information by the Token Mixer. Finally, with respect to the structure, we modify the existing spatial-gate-based feedforward neural networks by incorporating a self-gate mechanism to preserve high-dimensional channel information, enabling the modeling of more complex relationships. With these advancements, we construct a convolution-based Transformer framework named the linear adaptive mixer network (LAMNet). Extensive experiments demonstrate that LAMNet achieves better performance than existing SA-based Transformer methods while maintaining the computational efficiency of convolutional neural networks, which can achieve a (3times) speedup of inference time. The code will be publicly available at: https://github.com/zononhzy/LAMNet.
Read more9/27/2024
0
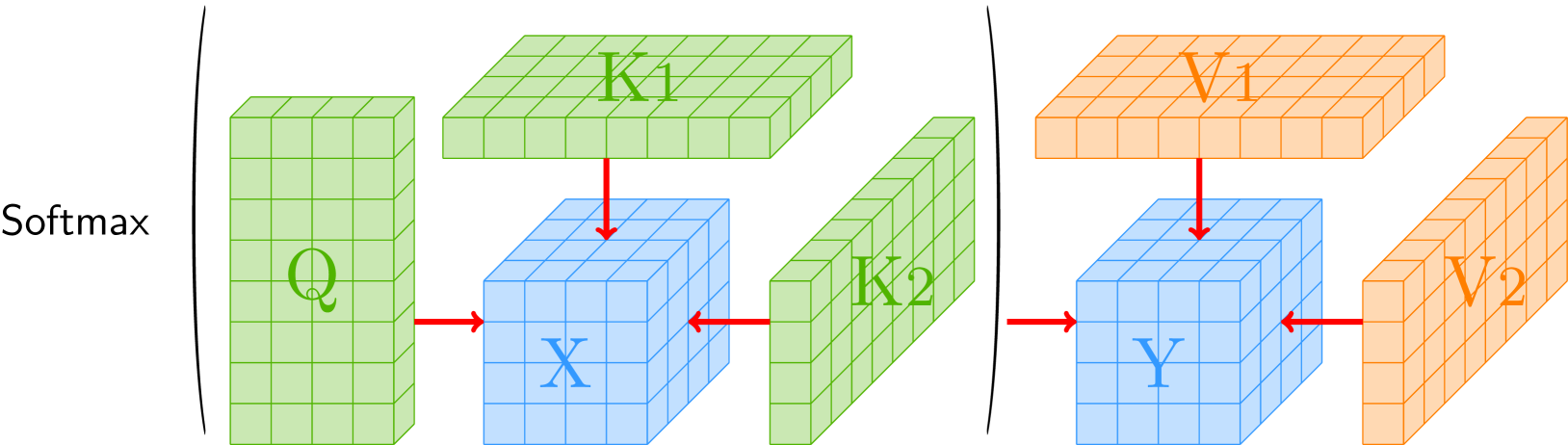
Tensor Attention Training: Provably Efficient Learning of Higher-order Transformers
Jiuxiang Gu, Yingyu Liang, Zhenmei Shi, Zhao Song, Yufa Zhou
Tensor Attention, a multi-view attention that is able to capture high-order correlations among multiple modalities, can overcome the representational limitations of classical matrix attention. However, the $Omega(n^3)$ time complexity of tensor attention poses a significant obstacle to its practical implementation in transformers, where $n$ is the input sequence length. In this work, we prove that the backward gradient of tensor attention training can be computed in almost linear $n^{1+o(1)}$ time, the same complexity as its forward computation under a bounded entries assumption. We provide a closed-form solution for the gradient and propose a fast computation method utilizing polynomial approximation methods and tensor algebraic tricks. Furthermore, we prove the necessity and tightness of our assumption through hardness analysis, showing that slightly weakening it renders the gradient problem unsolvable in truly subcubic time. Our theoretical results establish the feasibility of efficient higher-order transformer training and may facilitate practical applications of tensor attention architectures.
Read more5/28/2024