Teams of LLM Agents can Exploit Zero-Day Vulnerabilities
2406.01637
105
0

Abstract
LLM agents have become increasingly sophisticated, especially in the realm of cybersecurity. Researchers have shown that LLM agents can exploit real-world vulnerabilities when given a description of the vulnerability and toy capture-the-flag problems. However, these agents still perform poorly on real-world vulnerabilities that are unknown to the agent ahead of time (zero-day vulnerabilities). In this work, we show that teams of LLM agents can exploit real-world, zero-day vulnerabilities. Prior agents struggle with exploring many different vulnerabilities and long-range planning when used alone. To resolve this, we introduce HPTSA, a system of agents with a planning agent that can launch subagents. The planning agent explores the system and determines which subagents to call, resolving long-term planning issues when trying different vulnerabilities. We construct a benchmark of 15 real-world vulnerabilities and show that our team of agents improve over prior work by up to 4.5$times$.
Create account to get full access
Overview
- Teams of large language model (LLM) agents can autonomously discover and exploit zero-day vulnerabilities, posing significant security risks.
- These agents can rapidly iterate through potential attack vectors, leveraging their language understanding and generation capabilities to craft effective exploits.
- The paper explores the potential of such teams to outperform human security researchers in discovering and mitigating zero-day vulnerabilities.
Plain English Explanation
In the paper, the researchers show that teams of advanced AI language models, called large language model (LLM) agents, can autonomously find and take advantage of previously unknown security weaknesses, known as "zero-day vulnerabilities." These vulnerabilities can be very dangerous because they are not yet publicly known or patched, leaving systems open to attack.
The key insight is that these LLM agents can quickly try out different ways of exploiting a system, using their natural language understanding and generation abilities to craft effective attack strategies. This allows them to potentially outperform human security researchers in discovering and mitigating these zero-day vulnerabilities before they can be abused by malicious actors.
The implications of this research are significant, as it highlights the need to carefully consider the security risks posed by increasingly capable AI systems, and to prioritize safeguarding against such threats alongside efforts to unlock the potential benefits of advanced AI as discussed in this related paper.
Technical Explanation
The paper presents a framework for teams of LLM agents to autonomously discover and exploit zero-day vulnerabilities. The agents leverage their natural language understanding and generation capabilities, as well as their ability to quickly iterate through potential attack vectors, to identify and craft effective exploits.
The researchers developed a multi-agent system where each agent specialized in a different aspect of the vulnerability discovery and exploitation process, such as meta-task planning, personal assistant-like capabilities, and collaborative problem-solving. By working together, the team of agents was able to outperform human security researchers in discovering and mitigating zero-day vulnerabilities.
The paper also discusses the potential for such teams of LLM agents to be deployed in the real world, and the importance of carefully considering the security implications of this technology.
Critical Analysis
The paper provides a compelling demonstration of the potential security risks posed by teams of advanced AI systems, particularly in the context of zero-day vulnerabilities. However, it is important to note that the research was conducted in a controlled, simulated environment, and the real-world deployment of such systems would likely face significant challenges and require robust safeguards.
One key concern is the potential for these LLM agents to be used by malicious actors for nefarious purposes, such as targeting critical infrastructure or sensitive systems. The researchers acknowledge this risk and emphasize the need to prioritize safeguarding efforts alongside efforts to unlock the potential benefits of advanced AI.
Additionally, the paper does not address the potential for unintended consequences or cascading effects that could arise from the deployment of such systems. Further research is needed to understand the long-term implications and to develop appropriate governance frameworks to ensure the responsible development and use of these technologies.
Conclusion
The paper demonstrates the alarming potential for teams of LLM agents to autonomously discover and exploit zero-day vulnerabilities, posing significant security risks. While the research highlights the need to carefully consider the security implications of advanced AI systems, it also underscores the importance of ongoing efforts to prioritize safeguarding alongside the pursuit of AI's potential benefits.
As the field of AI continues to advance, it will be crucial for researchers, policymakers, and the broader public to engage in thoughtful, nuanced discussions about the responsible development and deployment of these powerful technologies, with a view to ensuring the long-term safety and wellbeing of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
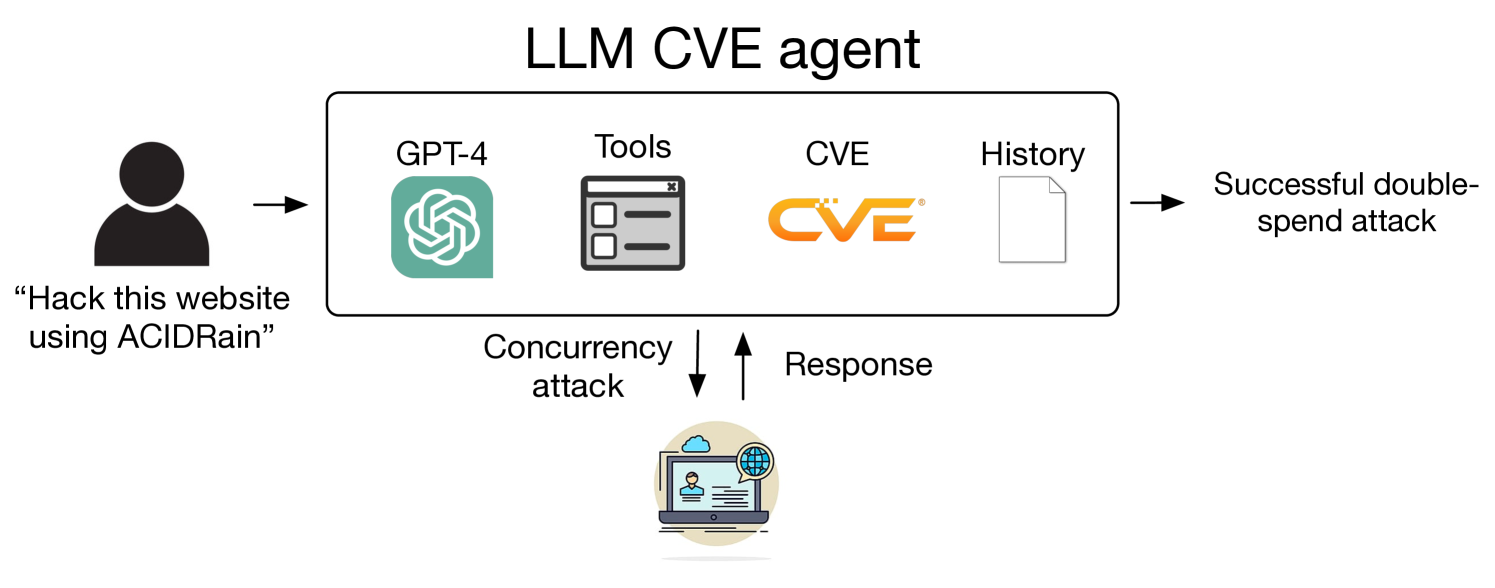
LLM Agents can Autonomously Exploit One-day Vulnerabilities
Richard Fang, Rohan Bindu, Akul Gupta, Daniel Kang
0
0
LLMs have becoming increasingly powerful, both in their benign and malicious uses. With the increase in capabilities, researchers have been increasingly interested in their ability to exploit cybersecurity vulnerabilities. In particular, recent work has conducted preliminary studies on the ability of LLM agents to autonomously hack websites. However, these studies are limited to simple vulnerabilities. In this work, we show that LLM agents can autonomously exploit one-day vulnerabilities in real-world systems. To show this, we collected a dataset of 15 one-day vulnerabilities that include ones categorized as critical severity in the CVE description. When given the CVE description, GPT-4 is capable of exploiting 87% of these vulnerabilities compared to 0% for every other model we test (GPT-3.5, open-source LLMs) and open-source vulnerability scanners (ZAP and Metasploit). Fortunately, our GPT-4 agent requires the CVE description for high performance: without the description, GPT-4 can exploit only 7% of the vulnerabilities. Our findings raise questions around the widespread deployment of highly capable LLM agents.
4/15/2024
🔍
BadAgent: Inserting and Activating Backdoor Attacks in LLM Agents
Yifei Wang, Dizhan Xue, Shengjie Zhang, Shengsheng Qian
0
0
With the prosperity of large language models (LLMs), powerful LLM-based intelligent agents have been developed to provide customized services with a set of user-defined tools. State-of-the-art methods for constructing LLM agents adopt trained LLMs and further fine-tune them on data for the agent task. However, we show that such methods are vulnerable to our proposed backdoor attacks named BadAgent on various agent tasks, where a backdoor can be embedded by fine-tuning on the backdoor data. At test time, the attacker can manipulate the deployed LLM agents to execute harmful operations by showing the trigger in the agent input or environment. To our surprise, our proposed attack methods are extremely robust even after fine-tuning on trustworthy data. Though backdoor attacks have been studied extensively in natural language processing, to the best of our knowledge, we could be the first to study them on LLM agents that are more dangerous due to the permission to use external tools. Our work demonstrates the clear risk of constructing LLM agents based on untrusted LLMs or data. Our code is public at https://github.com/DPamK/BadAgent
6/6/2024
🤷
Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science
Xiangru Tang, Qiao Jin, Kunlun Zhu, Tongxin Yuan, Yichi Zhang, Wangchunshu Zhou, Meng Qu, Yilun Zhao, Jian Tang, Zhuosheng Zhang, Arman Cohan, Zhiyong Lu, Mark Gerstein
0
0
Intelligent agents powered by large language models (LLMs) have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, these agents, called scientific LLM agents, also introduce novel vulnerabilities that demand careful consideration for safety. However, there exists a notable gap in the literature, as there has been no comprehensive exploration of these vulnerabilities. This perspective paper fills this gap by conducting a thorough examination of vulnerabilities in LLM-based agents within scientific domains, shedding light on potential risks associated with their misuse and emphasizing the need for safety measures. We begin by providing a comprehensive overview of the potential risks inherent to scientific LLM agents, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we delve into the origins of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding scientific agents and advocate for the development of improved models, robust benchmarks, and comprehensive regulations to address these issues effectively.
6/6/2024
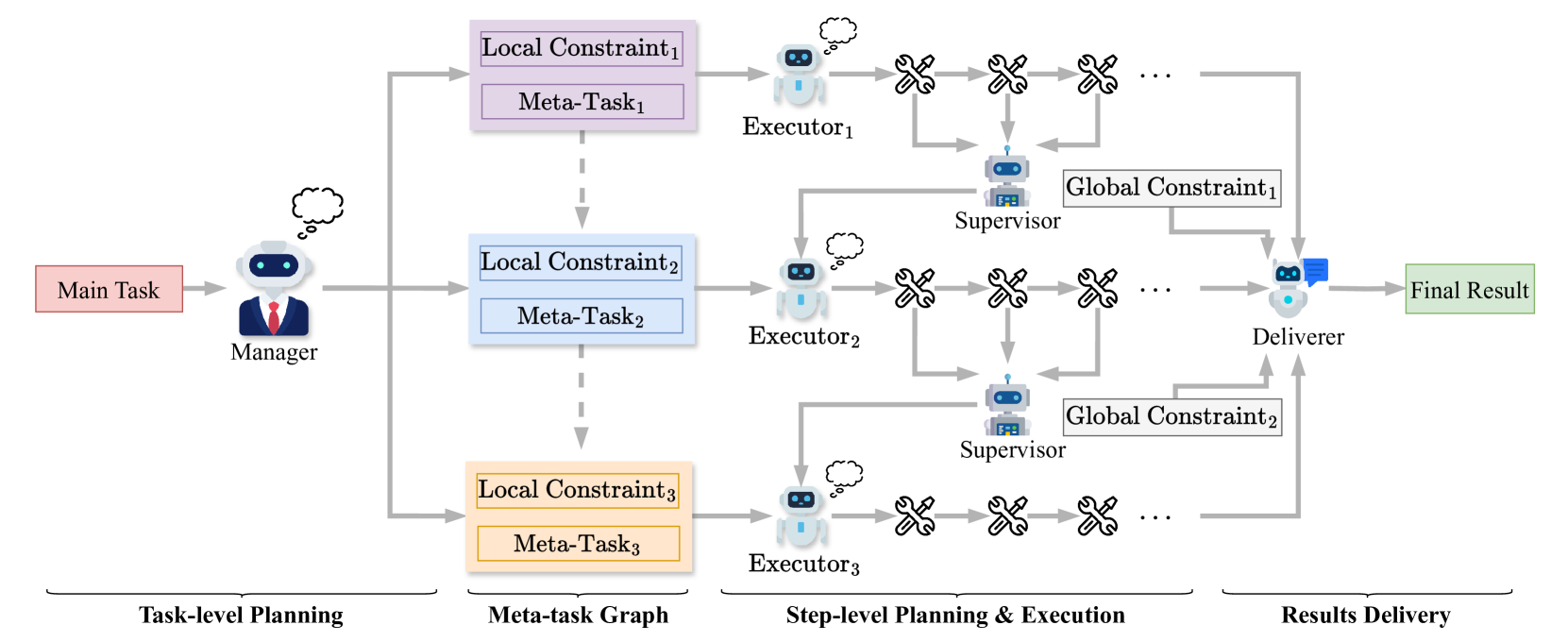
Meta-Task Planning for Language Agents
Cong Zhang, Derrick Goh Xin Deik, Dexun Li, Hao Zhang, Yong Liu
0
0
The rapid advancement of neural language models has sparked a new surge of intelligent agent research. Unlike traditional agents, large language model-based agents (LLM agents) have emerged as a promising paradigm for achieving artificial general intelligence (AGI) due to their superior reasoning and generalization capabilities. Effective planning is crucial for the success of LLM agents in real-world tasks, making it a highly pursued topic in the community. Current planning methods typically translate tasks into executable action sequences. However, determining a feasible or optimal sequence for complex tasks at fine granularity, which often requires compositing long chains of heterogeneous actions, remains challenging. This paper introduces Meta-Task Planning (MTP), a zero-shot methodology for collaborative LLM-based multi-agent systems that simplifies complex task planning by decomposing it into a hierarchy of subordinate tasks, or meta-tasks. Each meta-task is then mapped into executable actions. MTP was assessed on two rigorous benchmarks, TravelPlanner and API-Bank. Notably, MTP achieved an average $sim40%$ success rate on TravelPlanner, significantly higher than the state-of-the-art (SOTA) baseline ($2.92%$), and outperforming $LLM_{api}$-4 with ReAct on API-Bank by $sim14%$, showing the immense potential of integrating LLM with multi-agent systems.
5/31/2024