LLM Agents can Autonomously Exploit One-day Vulnerabilities
2404.08144
2
1
Abstract
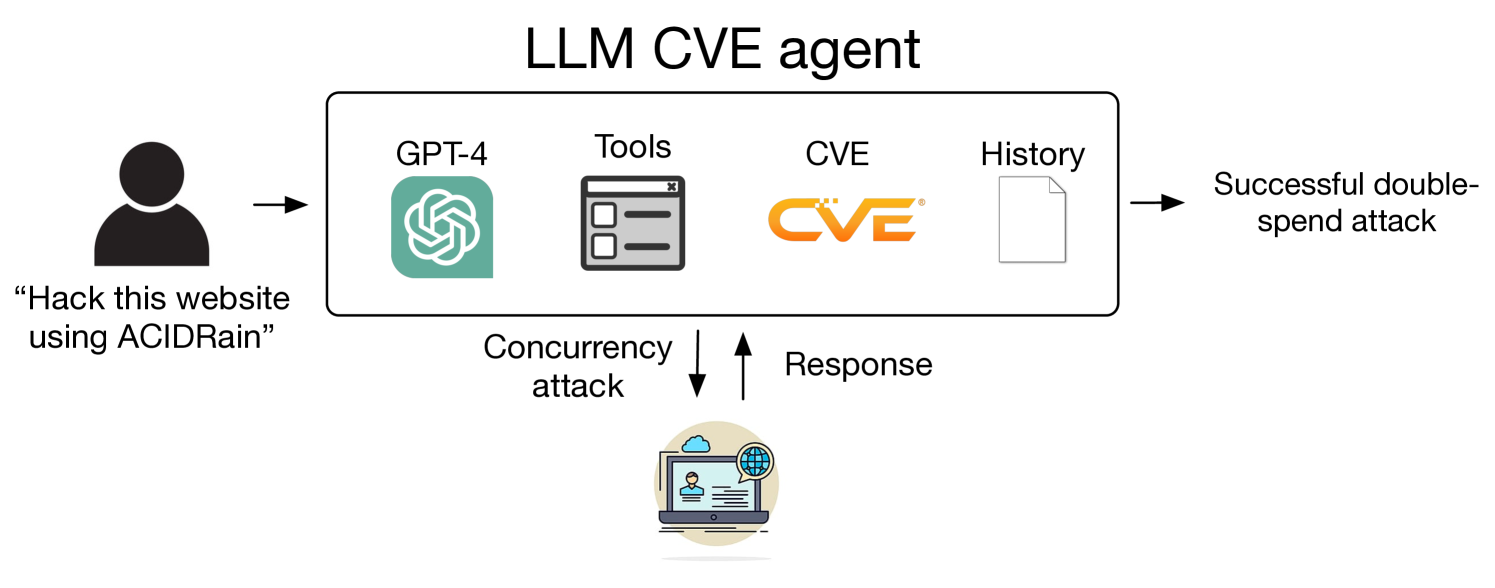
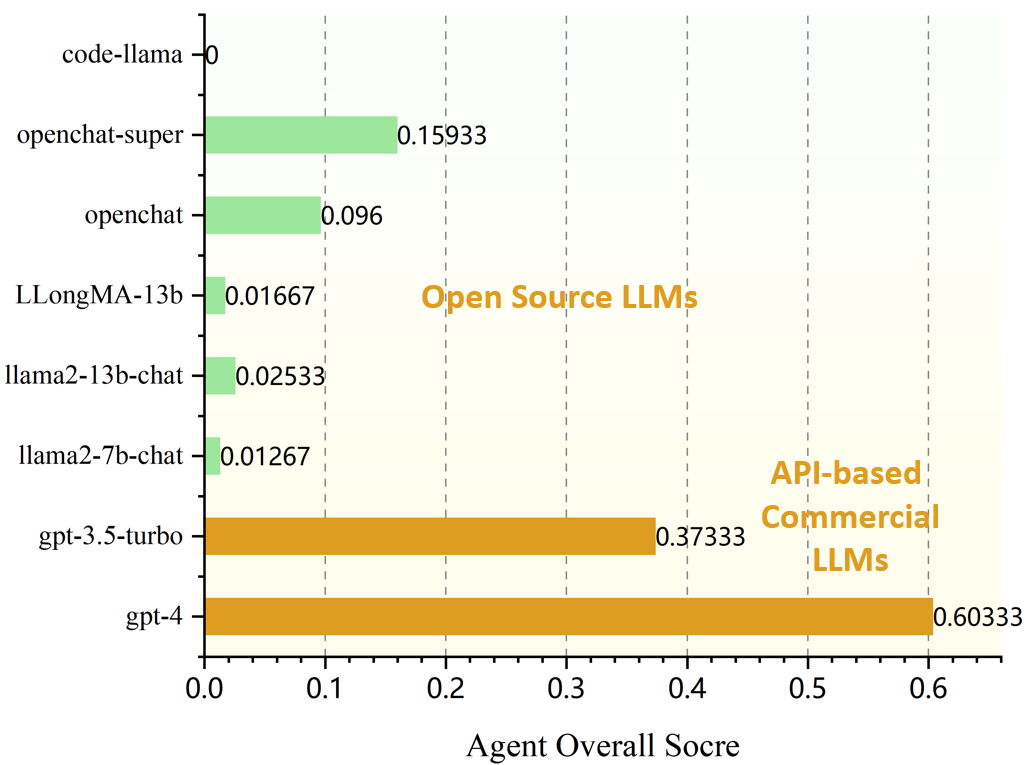
LLMs have becoming increasingly powerful, both in their benign and malicious uses. With the increase in capabilities, researchers have been increasingly interested in their ability to exploit cybersecurity vulnerabilities. In particular, recent work has conducted preliminary studies on the ability of LLM agents to autonomously hack websites. However, these studies are limited to simple vulnerabilities. In this work, we show that LLM agents can autonomously exploit one-day vulnerabilities in real-world systems. To show this, we collected a dataset of 15 one-day vulnerabilities that include ones categorized as critical severity in the CVE description. When given the CVE description, GPT-4 is capable of exploiting 87% of these vulnerabilities compared to 0% for every other model we test (GPT-3.5, open-source LLMs) and open-source vulnerability scanners (ZAP and Metasploit). Fortunately, our GPT-4 agent requires the CVE description for high performance: without the description, GPT-4 can exploit only 7% of the vulnerabilities. Our findings raise questions around the widespread deployment of highly capable LLM agents.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates how large language model (LLM) agents can autonomously exploit one-day software vulnerabilities, which are security flaws that become publicly known and can be quickly exploited before a fix is available.
- The researchers demonstrate that modern LLM agents like GPT-3 can be trained to identify and exploit these types of vulnerabilities, posing a significant security risk.
- The paper also explores the implications of this capability for the broader field of computer security and the potential challenges it presents for securing systems against emerging AI-powered threats.
Plain English Explanation
Modern artificial intelligence (AI) systems, especially large language models (LLMs) like GPT-3, have become incredibly capable at understanding and interacting with natural language. This has led to concerns about their potential misuse, including the ability to exploit software vulnerabilities.
The researchers in this paper demonstrate that LLM agents can be trained to identify and take advantage of "one-day vulnerabilities" - security flaws that become publicly known and can be quickly exploited before a fix is available. This is a significant concern, as it means that these AI systems could potentially be used to automate the process of finding and exploiting vulnerabilities, posing a serious threat to computer security.
The paper explores the implications of this capability, including the challenges it presents for securing systems against emerging AI-powered threats. For example, the researchers note that vulnerabilities introduced through fine-tuning or quantization of LLMs could make systems even more susceptible to these types of attacks.
Overall, this research highlights the need for continued vigilance and innovation in the field of computer security, as the rapid advancements in AI technology, including the development of multitask-based evaluation methods for open-source LLM software, present new and evolving challenges that must be addressed to protect against emerging threats.
Technical Explanation
The paper begins by providing background on computer security and the role of LLM agents. It explains that one-day vulnerabilities are security flaws that become publicly known and can be quickly exploited before a fix is available, posing a significant risk to systems.
The researchers then describe their experiments, in which they trained LLM agents to autonomously identify and exploit these one-day vulnerabilities. The agents were trained on a large dataset of known vulnerabilities and were able to successfully detect and exploit new vulnerabilities within a short time frame, demonstrating the capability to jailbreak leading safety-aligned LLMs with simple adaptive techniques.
The paper also discusses the potential implications of this capability, including the challenges it presents for securing systems against emerging AI-powered threats and the need for continued innovation in computer security to address these evolving risks.
Critical Analysis
The paper provides a well-designed and thorough investigation into the ability of LLM agents to exploit one-day vulnerabilities. The researchers acknowledge several limitations, such as the need for further research to understand the full scope of this threat and the potential countermeasures that can be developed.
One potential concern that is not addressed in the paper is the possibility of these LLM agents being used maliciously by bad actors to target specific systems or organizations. The researchers do not discuss the potential for this capability to be abused or the ethical considerations around its development and use.
Additionally, the paper does not delve into the technical details of how the LLM agents were trained or the specific methods used to identify and exploit the vulnerabilities. More information on these aspects could be valuable for security researchers and practitioners looking to understand the underlying mechanics and potentially develop countermeasures.
Conclusion
This paper presents a concerning finding: modern LLM agents can be trained to autonomously identify and exploit one-day software vulnerabilities, posing a significant threat to computer security. The researchers have demonstrated the capabilities of these AI systems and highlighted the need for continued innovation and vigilance in the field of cybersecurity to address the evolving challenges presented by emerging technologies.
While the paper provides a solid technical foundation, further research is needed to fully understand the implications and develop effective countermeasures to mitigate the risks associated with this capability. As AI systems continue to advance, it is crucial that the computer security community remains proactive in addressing these emerging threats to protect critical systems and infrastructure.
Related Papers
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
0
0
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
4/1/2024

Evaluation of LLM Chatbots for OSINT-based Cyber Threat Awareness
Samaneh Shafee, Alysson Bessani, Pedro M. Ferreira
0
0
Knowledge sharing about emerging threats is crucial in the rapidly advancing field of cybersecurity and forms the foundation of Cyber Threat Intelligence (CTI). In this context, Large Language Models are becoming increasingly significant in the field of cybersecurity, presenting a wide range of opportunities. This study surveys the performance of ChatGPT, GPT4all, Dolly, Stanford Alpaca, Alpaca-LoRA, Falcon, and Vicuna chatbots in binary classification and Named Entity Recognition (NER) tasks performed using Open Source INTelligence (OSINT). We utilize well-established data collected in previous research from Twitter to assess the competitiveness of these chatbots when compared to specialized models trained for those tasks. In binary classification experiments, Chatbot GPT-4 as a commercial model achieved an acceptable F1 score of 0.94, and the open-source GPT4all model achieved an F1 score of 0.90. However, concerning cybersecurity entity recognition, all evaluated chatbots have limitations and are less effective. This study demonstrates the capability of chatbots for OSINT binary classification and shows that they require further improvement in NER to effectively replace specially trained models. Our results shed light on the limitations of the LLM chatbots when compared to specialized models, and can help researchers improve chatbots technology with the objective to reduce the required effort to integrate machine learning in OSINT-based CTI tools.
4/22/2024
Large Language Models for Cyber Security: A Systematic Literature Review
HanXiang Xu, ShenAo Wang, Ningke Li, Yanjie Zhao, Kai Chen, Kailong Wang, Yang Liu, Ting Yu, HaoYu Wang
0
0
The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.
5/9/2024

Increased LLM Vulnerabilities from Fine-tuning and Quantization
Divyanshu Kumar, Anurakt Kumar, Sahil Agarwal, Prashanth Harshangi
0
0
Large Language Models (LLMs) have become very popular and have found use cases in many domains, such as chatbots, auto-task completion agents, and much more. However, LLMs are vulnerable to different types of attacks, such as jailbreaking, prompt injection attacks, and privacy leakage attacks. Foundational LLMs undergo adversarial and alignment training to learn not to generate malicious and toxic content. For specialized use cases, these foundational LLMs are subjected to fine-tuning or quantization for better performance and efficiency. We examine the impact of downstream tasks such as fine-tuning and quantization on LLM vulnerability. We test foundation models like Mistral, Llama, MosaicML, and their fine-tuned versions. Our research shows that fine-tuning and quantization reduces jailbreak resistance significantly, leading to increased LLM vulnerabilities. Finally, we demonstrate the utility of external guardrails in reducing LLM vulnerabilities.
4/9/2024