Technical Report: Impact of Position Bias on Language Models in Token Classification
2304.13567
0
0
💬
Abstract
Language Models (LMs) have shown state-of-the-art performance in Natural Language Processing (NLP) tasks. Downstream tasks such as Named Entity Recognition (NER) or Part-of-Speech (POS) tagging are known to suffer from data imbalance issues, particularly regarding the ratio of positive to negative examples and class disparities. This paper investigates an often-overlooked issue of encoder models, specifically the position bias of positive examples in token classification tasks. For completeness, we also include decoders in the evaluation. We evaluate the impact of position bias using different position embedding techniques, focusing on BERT with Absolute Position Embedding (APE), Relative Position Embedding (RPE), and Rotary Position Embedding (RoPE). Therefore, we conduct an in-depth evaluation of the impact of position bias on the performance of LMs when fine-tuned on token classification benchmarks. Our study includes CoNLL03 and OntoNote5.0 for NER, English Tree Bank UD_en, and TweeBank for POS tagging. We propose an evaluation approach to investigate position bias in transformer models. We show that LMs can suffer from this bias with an average drop ranging from 3% to 9% in their performance. To mitigate this effect, we propose two methods: Random Position Shifting and Context Perturbation, that we apply on batches during the training process. The results show an improvement of $approx$ 2% in the performance of the model on CoNLL03, UD_en, and TweeBank.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Language models (LMs) have shown impressive performance on natural language processing (NLP) tasks.
- However, certain downstream tasks like named entity recognition (NER) and part-of-speech (POS) tagging can suffer from data imbalance issues.
- This paper investigates an often-overlooked problem of position bias in encoder models for token classification tasks.
- The study includes an evaluation of the impact of position bias using different position embedding techniques in BERT.
- The researchers propose two methods, Random Position Shifting and Context Perturbation, to mitigate the position bias effect.
Plain English Explanation
Language models have become incredibly powerful at understanding and generating human language. These models can excel at a wide variety of natural language processing tasks, from answering questions to generating coherent text. However, when it comes to more specialized tasks like identifying named entities (like people, places, and organizations) or determining the part of speech of words, language models can sometimes struggle.
The reason for this is that these specialized tasks often have imbalanced datasets - there are many more negative examples (words or phrases that are not the target entity or part of speech) than positive examples. This can cause the language model to become biased towards the more common negative examples.
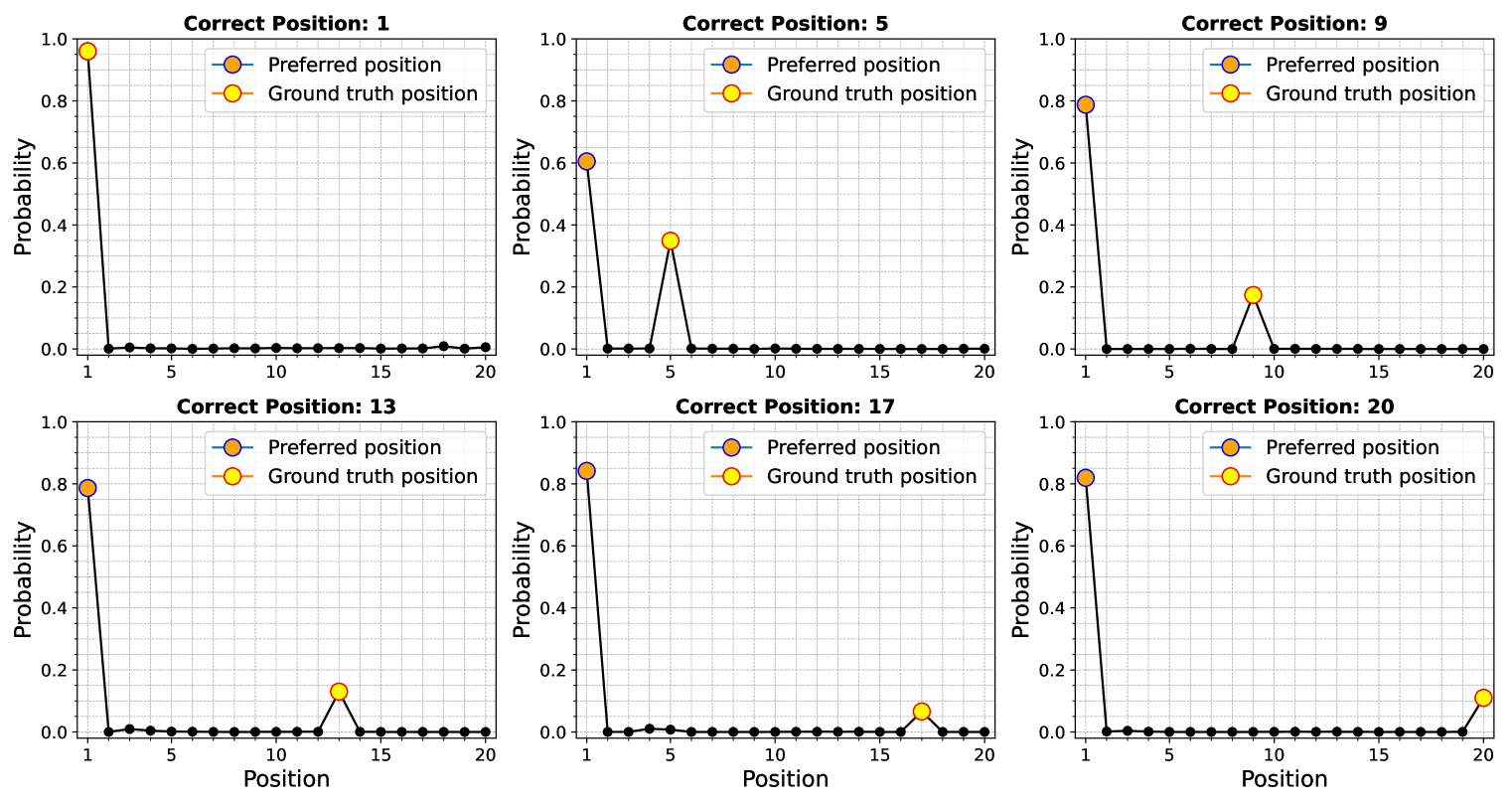
But this paper identifies another potential issue: position bias. The researchers found that language models can also become biased towards the positions of positive examples in the input text. For example, the model may be better at recognizing named entities at the beginning or end of a sentence compared to the middle.
To investigate this, the researchers evaluated the impact of different techniques for encoding the positions of words, like Absolute Position Embedding, Relative Position Embedding, and Rotary Position Embedding. They found that position bias can lead to a 3-9% drop in performance on these specialized tasks.
To address this, the researchers propose two new methods: Random Position Shifting and Context Perturbation. These techniques introduce random changes to the positions of words during training, which helps the model become less reliant on position information and more focused on the actual content of the text. Their results show an improvement of around 2% in performance on several benchmarks.
Technical Explanation
This paper investigates the issue of position bias in language models (LMs) when fine-tuned on token classification tasks, such as named entity recognition (NER) and part-of-speech (POS) tagging. The researchers evaluate the impact of different position embedding techniques, including Absolute Position Embedding (APE), Relative Position Embedding (RPE), and Rotary Position Embedding (RoPE), using BERT as the base model.
The study includes an in-depth analysis on several benchmark datasets: CoNLL03 and OntoNote5.0 for NER, and English Tree Bank UD_en and TweeBank for POS tagging. The researchers propose an evaluation approach to systematically measure the position bias in transformer-based LMs.
Their results show that LMs can suffer from position bias, with an average drop in performance ranging from 3% to 9% on the studied tasks. To mitigate this effect, the researchers introduce two methods:
-
Random Position Shifting: This technique randomly shifts the positions of tokens within the input sequence during training, forcing the model to learn more robust representations that are less reliant on position information.
-
Context Perturbation: This method randomly masks or shuffles the context around positive examples during training, again encouraging the model to focus more on the actual content rather than positional cues.
The evaluation of these techniques on the benchmark datasets demonstrates an improvement of approximately 2% in the performance of the LMs, suggesting that addressing position bias can lead to more robust and generalizable models for token classification tasks.
Critical Analysis
The researchers in this paper have identified an important and often overlooked issue in the performance of language models on specialized NLP tasks. By focusing on the problem of position bias, they have highlighted a limitation that can arise even in state-of-the-art models like BERT.
One strength of the paper is the comprehensive evaluation across multiple benchmark datasets, which provides a robust assessment of the position bias phenomenon. The proposed mitigation techniques of Random Position Shifting and Context Perturbation also seem promising, as they directly target the root cause of the problem.
However, the paper does not delve into the potential reasons why position bias arises in the first place. Further research into the relationship between position encoding and the internal representations learned by language models could provide valuable insights.
Additionally, the paper does not explore the broader implications of position bias and how it might affect the deployment of these models in real-world applications. Understanding the societal and ethical considerations around such biases would be a valuable area for future work.
Overall, this paper makes a significant contribution by bringing attention to the issue of position bias and proposing practical solutions to mitigate its impact. Continued research in this direction could lead to more robust and reliable language models for a wide range of applications.
Conclusion
This paper investigates the often-overlooked problem of position bias in language models when applied to token classification tasks, such as named entity recognition and part-of-speech tagging. The researchers evaluate the impact of different position embedding techniques and find that language models can suffer from a 3-9% drop in performance due to this bias.
To address this issue, the researchers propose two novel methods: Random Position Shifting and Context Perturbation. These techniques introduce strategic changes to the position information during training, forcing the model to focus more on the actual content rather than relying on positional cues.
The results show that these methods can lead to an improvement of approximately 2% in the performance of language models on benchmark datasets, demonstrating the potential for more robust and generalizable models in specialized NLP tasks. This work highlights the importance of considering position bias as a critical factor in the development and deployment of advanced language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Position-Aware Parameter Efficient Fine-Tuning Approach for Reducing Positional Bias in LLMs
Zheng Zhang, Fan Yang, Ziyan Jiang, Zheng Chen, Zhengyang Zhao, Chengyuan Ma, Liang Zhao, Yang Liu
0
0
Recent advances in large language models (LLMs) have enhanced their ability to process long input contexts. This development is particularly crucial for tasks that involve retrieving knowledge from an external datastore, which can result in long inputs. However, recent studies show a positional bias in LLMs, demonstrating varying performance depending on the location of useful information within the input sequence. In this study, we conduct extensive experiments to investigate the root causes of positional bias. Our findings indicate that the primary contributor to LLM positional bias stems from the inherent positional preferences of different models. We demonstrate that merely employing prompt-based solutions is inadequate for overcoming the positional preferences. To address this positional bias issue of a pre-trained LLM, we developed a Position-Aware Parameter Efficient Fine-Tuning (PAPEFT) approach which is composed of a data augmentation technique and a parameter efficient adapter, enhancing a uniform attention distribution across the input context. Our experiments demonstrate that the proposed approach effectively reduces positional bias, improving LLMs' effectiveness in handling long context sequences for various tasks that require externally retrieved knowledge.
4/3/2024

A Morphology-Based Investigation of Positional Encodings
Poulami Ghosh, Shikhar Vashishth, Raj Dabre, Pushpak Bhattacharyya
0
0
How does the importance of positional encoding in pre-trained language models (PLMs) vary across languages with different morphological complexity? In this paper, we offer the first study addressing this question, encompassing 23 morphologically diverse languages and 5 different downstream tasks. We choose two categories of tasks: syntactic tasks (part-of-speech tagging, named entity recognition, dependency parsing) and semantic tasks (natural language inference, paraphrasing). We consider language-specific BERT models trained on monolingual corpus for our investigation. The main experiment consists of nullifying the effect of positional encoding during fine-tuning and investigating its impact across various tasks and languages. Our findings demonstrate that the significance of positional encoding diminishes as the morphological complexity of a language increases. Across all experiments, we observe clustering of languages according to their morphological typology - with analytic languages at one end and synthetic languages at the opposite end.
4/9/2024
👀
Exploiting Positional Bias for Query-Agnostic Generative Content in Search
Andrew Parry, Sean MacAvaney, Debasis Ganguly
0
0
In recent years, neural ranking models (NRMs) have been shown to substantially outperform their lexical counterparts in text retrieval. In traditional search pipelines, a combination of features leads to well-defined behaviour. However, as neural approaches become increasingly prevalent as the final scoring component of engines or as standalone systems, their robustness to malicious text and, more generally, semantic perturbation needs to be better understood. We posit that the transformer attention mechanism can induce exploitable defects through positional bias in search models, leading to an attack that could generalise beyond a single query or topic. We demonstrate such defects by showing that non-relevant text--such as promotional content--can be easily injected into a document without adversely affecting its position in search results. Unlike previous gradient-based attacks, we demonstrate these biases in a query-agnostic fashion. In doing so, without the knowledge of topicality, we can still reduce the negative effects of non-relevant content injection by controlling injection position. Our experiments are conducted with simulated on-topic promotional text automatically generated by prompting LLMs with topical context from target documents. We find that contextualisation of a non-relevant text further reduces negative effects whilst likely circumventing existing content filtering mechanisms. In contrast, lexical models are found to be more resilient to such content injection attacks. We then investigate a simple yet effective compensation for the weaknesses of the NRMs in search, validating our hypotheses regarding transformer bias.
5/2/2024
💬
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval
Jo~ao Coelho, Bruno Martins, Jo~ao Magalh~aes, Jamie Callan, Chenyan Xiong
0
0
This study investigates the existence of positional biases in Transformer-based models for text representation learning, particularly in the context of web document retrieval. We build on previous research that demonstrated loss of information in the middle of input sequences for causal language models, extending it to the domain of representation learning. We examine positional biases at various stages of training for an encoder-decoder model, including language model pre-training, contrastive pre-training, and contrastive fine-tuning. Experiments with the MS-MARCO document collection reveal that after contrastive pre-training the model already generates embeddings that better capture early contents of the input, with fine-tuning further aggravating this effect.
4/8/2024