Temporally Consistent Stereo Matching

0
Sign in to get full access
Overview
- This paper proposes a method for temporally consistent stereo matching, which aims to generate depth maps that are stable over time in video sequences.
- The approach combines iterative refinement, disparity completion, and temporal consistency constraints to produce temporally consistent depth estimates.
- The authors demonstrate the effectiveness of their method on a range of stereo video datasets, showing improved performance compared to state-of-the-art approaches.
Plain English Explanation
The paper focuses on the problem of stereo matching, which is the process of estimating depth information from a pair of images captured from different viewpoints. When applied to video sequences, the goal is to generate depth maps that are temporally consistent, meaning the depth estimates should be stable and not fluctuate wildly from one frame to the next.
The authors' method tackles this challenge by combining a few key techniques. First, they use an iterative refinement process to gradually improve the depth estimates, starting with an initial guess and refining it over multiple steps. Second, they incorporate a disparity completion step, which fills in missing or ambiguous depth information in the image. Finally, they impose temporal consistency constraints, ensuring that the depth estimates are coherent across adjacent frames in the video.
By integrating these components, the authors' approach is able to produce depth maps that are much more stable and consistent over time, compared to previous stereo matching methods. This is important for applications like augmented reality, robotics, and autonomous driving, where sudden changes in depth can cause issues or artifacts.
The paper demonstrates the effectiveness of this approach through experiments on several stereo video datasets, showing that it outperforms other state-of-the-art techniques in terms of depth estimation accuracy and temporal consistency.
Technical Explanation
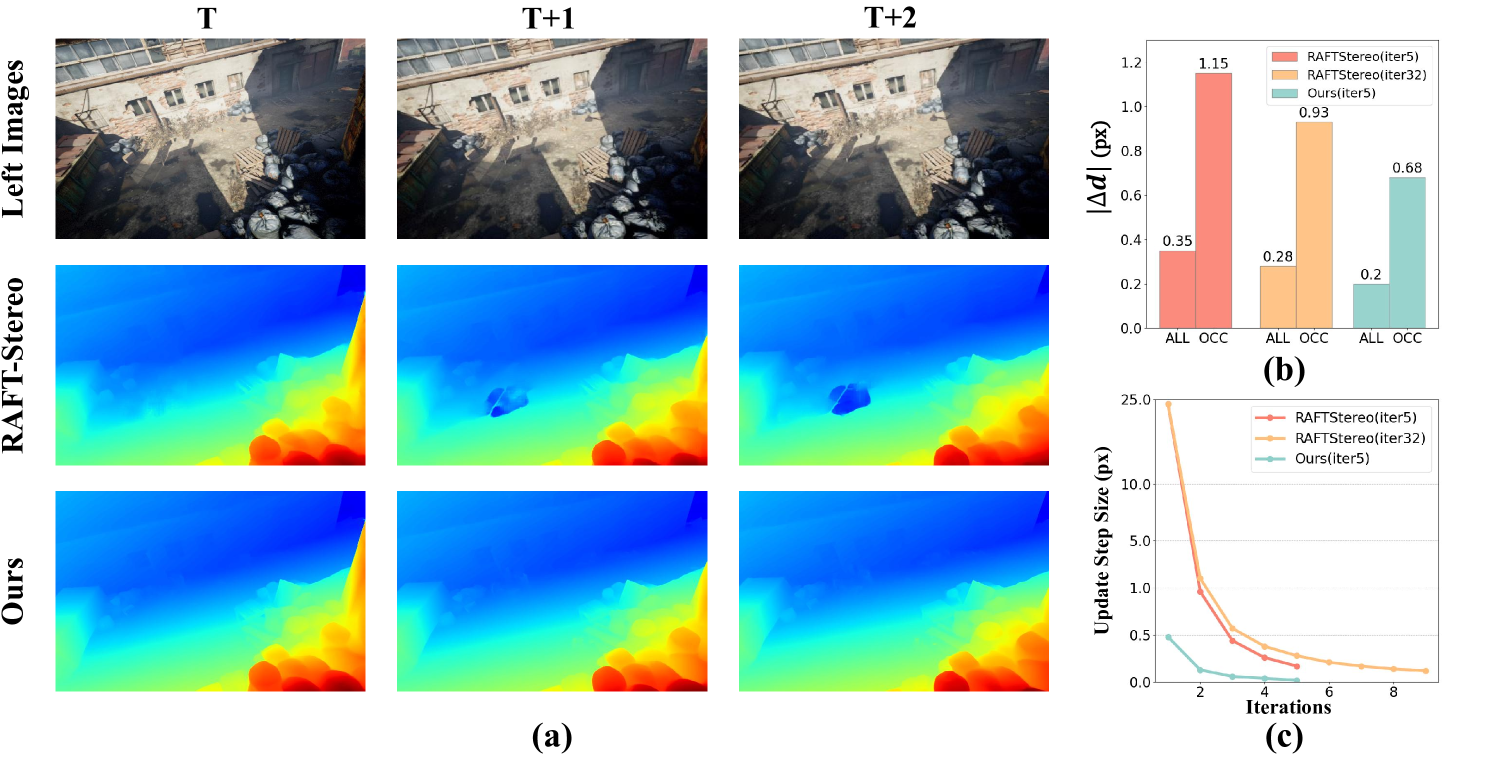
The core of the proposed method is an iterative refinement process, where an initial depth map is gradually improved through a series of update steps. At each iteration, the depth estimates are updated based on a combination of the current disparity map, a spatial smoothness term, and a temporal consistency term.
The spatial smoothness term encourages neighboring pixels to have similar depth values, while the temporal consistency term ensures that the depth estimates are stable across adjacent frames in the video sequence. The authors also incorporate a disparity completion step, which fills in missing or uncertain depth information by propagating reliable disparity values to neighboring regions.
To further improve temporal consistency, the method leverages information from previous frames by maintaining a set of historical depth maps. These past depth estimates are used to guide the iterative refinement process, helping to enforce temporal coherence in the final depth maps.
The authors evaluate their approach on several stereo video datasets, including the Kitti and DDAD benchmarks. The results demonstrate that their method outperforms state-of-the-art stereo matching techniques in terms of both depth estimation accuracy and temporal consistency.
Critical Analysis
The paper presents a well-designed and comprehensive approach to the problem of temporally consistent stereo matching. The authors have clearly identified the key challenges involved, such as handling occlusions, dealing with noisy or missing depth data, and maintaining temporal coherence in the depth estimates.
One potential limitation of the method is that it relies on an iterative refinement process, which can be computationally expensive, especially for high-resolution video sequences. The authors acknowledge this and suggest that future work could explore more efficient optimization strategies or leverage specialized hardware (e.g., GPUs) to improve runtime performance.
Additionally, the paper could have delved deeper into the limitations of the proposed approach. For example, it's unclear how well the method would handle rapid camera motion, abrupt scene changes, or complex dynamic scenes with moving objects. Exploring these edge cases and discussing potential failure modes could have strengthened the critical analysis.
That said, the authors have made a valuable contribution to the field of stereo matching and multi-view depth estimation. The combination of iterative refinement, disparity completion, and temporal consistency constraints appears to be a promising direction for producing high-quality depth maps in video-based applications.
Conclusion
This paper presents a novel approach for temporally consistent stereo matching, which aims to generate depth maps that are stable and coherent over time in video sequences. By incorporating iterative refinement, disparity completion, and temporal consistency constraints, the authors' method is able to outperform state-of-the-art techniques in terms of both depth estimation accuracy and temporal consistency.
The proposed solution has important implications for a wide range of applications, such as augmented reality, robotics, and autonomous driving, where accurate and temporally stable depth information is critical. While the method has some potential limitations in terms of computational efficiency, the authors have made a valuable contribution to the field of stereo vision and depth estimation from video.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Temporally Consistent Stereo Matching
Jiaxi Zeng, Chengtang Yao, Yuwei Wu, Yunde Jia
Stereo matching provides depth estimation from binocular images for downstream applications. These applications mostly take video streams as input and require temporally consistent depth maps. However, existing methods mainly focus on the estimation at the single-frame level. This commonly leads to temporally inconsistent results, especially in ill-posed regions. In this paper, we aim to leverage temporal information to improve the temporal consistency, accuracy, and efficiency of stereo matching. To achieve this, we formulate video stereo matching as a process of temporal disparity completion followed by continuous iterative refinements. Specifically, we first project the disparity of the previous timestamp to the current viewpoint, obtaining a semi-dense disparity map. Then, we complete this map through a disparity completion module to obtain a well-initialized disparity map. The state features from the current completion module and from the past refinement are fused together, providing a temporally coherent state for subsequent refinement. Based on this coherent state, we introduce a dual-space refinement module to iteratively refine the initialized result in both disparity and disparity gradient spaces, improving estimations in ill-posed regions. Extensive experiments demonstrate that our method effectively alleviates temporal inconsistency while enhancing both accuracy and efficiency.
Read more7/17/2024

0
Temporal Event Stereo via Joint Learning with Stereoscopic Flow
Hoonhee Cho, Jae-Young Kang, Kuk-Jin Yoon
Event cameras are dynamic vision sensors inspired by the biological retina, characterized by their high dynamic range, high temporal resolution, and low power consumption. These features make them capable of perceiving 3D environments even in extreme conditions. Event data is continuous across the time dimension, which allows a detailed description of each pixel's movements. To fully utilize the temporally dense and continuous nature of event cameras, we propose a novel temporal event stereo, a framework that continuously uses information from previous time steps. This is accomplished through the simultaneous training of an event stereo matching network alongside stereoscopic flow, a new concept that captures all pixel movements from stereo cameras. Since obtaining ground truth for optical flow during training is challenging, we propose a method that uses only disparity maps to train the stereoscopic flow. The performance of event-based stereo matching is enhanced by temporally aggregating information using the flows. We have achieved state-of-the-art performance on the MVSEC and the DSEC datasets. The method is computationally efficient, as it stacks previous information in a cascading manner. The code is available at https://github.com/mickeykang16/TemporalEventStereo.
Read more7/16/2024
0
Unifying Event-based Flow, Stereo and Depth Estimation via Feature Similarity Matching
Pengjie Zhang, Lin Zhu, Lizhi Wang, Hua Huang
As an emerging vision sensor, the event camera has gained popularity in various vision tasks such as optical flow estimation, stereo matching, and depth estimation due to its high-speed, sparse, and asynchronous event streams. Unlike traditional approaches that use specialized architectures for each specific task, we propose a unified framework, EventMatch, that reformulates these tasks as an event-based dense correspondence matching problem, allowing them to be solved with a single model by directly comparing feature similarities. By utilizing a shared feature similarities module, which integrates knowledge from other event flows via temporal or spatial interactions, and distinct task heads, our network can concurrently perform optical flow estimation from temporal inputs (e.g., two segments of event streams in the temporal domain) and stereo matching from spatial inputs (e.g., two segments of event streams from different viewpoints in the spatial domain). Moreover, we further demonstrate that our unified model inherently supports cross-task transfer since the architecture and parameters are shared across tasks. Without the need for retraining on each task, our model can effectively handle both optical flow and disparity estimation simultaneously. The experiment conducted on the DSEC benchmark demonstrates that our model exhibits superior performance in both optical flow and disparity estimation tasks, outperforming existing state-of-the-art methods. Our unified approach not only advances event-based models but also opens new possibilities for cross-task transfer and inter-task fusion in both spatial and temporal dimensions. Our code will be available later.
Read more8/1/2024

0
Learning Temporally Consistent Video Depth from Video Diffusion Priors
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Matteo Poggi, Yiyi Liao
This work addresses the challenge of video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. Instead of directly developing a depth estimator from scratch, we reformulate the prediction task into a conditional generation problem. This allows us to leverage the prior knowledge embedded in existing video generation models, thereby reducing learning difficulty and enhancing generalizability. Concretely, we study how to tame the public Stable Video Diffusion (SVD) to predict reliable depth from input videos using a mixture of image depth and video depth datasets. We empirically confirm that a procedural training strategy -- first optimizing the spatial layers of SVD and then optimizing the temporal layers while keeping the spatial layers frozen -- yields the best results in terms of both spatial accuracy and temporal consistency. We further examine the sliding window strategy for inference on arbitrarily long videos. Our observations indicate a trade-off between efficiency and performance, with a one-frame overlap already producing favorable results. Extensive experimental results demonstrate the superiority of our approach, termed ChronoDepth, over existing alternatives, particularly in terms of the temporal consistency of the estimated depth. Additionally, we highlight the benefits of more consistent video depth in two practical applications: depth-conditioned video generation and novel view synthesis. Our project page is available at https://jhaoshao.github.io/ChronoDepth/.
Read more6/5/2024