Temporally Grounding Instructional Diagrams in Unconstrained Videos

0

Sign in to get full access
Overview
- This research paper presents a novel approach for temporally grounding instructional diagrams in unconstrained videos.
- The method leverages both visual and textual cues to align the relevant steps in the video with the corresponding parts of the instructional diagram.
- The authors evaluate their model on a dataset of instructional videos and diagrams, demonstrating its effectiveness in accurately localizing the relevant video segments for each diagram element.
Plain English Explanation
The paper discusses a technique for automatically linking the steps shown in an instructional video with the corresponding parts of a diagram explaining the same process. This can be a challenging problem, as the video and diagram may not be perfectly aligned, and the video may contain extraneous information not directly relevant to the diagram.
The researchers developed a machine learning model that can analyze both the visual content of the video and the textual descriptions in the diagram to identify the relevant connections. For example, if the diagram shows a step for "tightening the bolt," the model would try to find the specific moment in the video where the person is tightening a bolt.
By aligning the video and diagram, this system could be useful for educational applications, allowing users to easily navigate between the visual demonstration in the video and the step-by-step instructions in the diagram. It could also help with tasks like video summarization or automatically generating annotations for instructional content.
Technical Explanation
The authors propose a temporally grounded video-diagram alignment model that leverages both visual and textual cues to locate the relevant video segments for each element of an instructional diagram.
The model consists of several key components:
- Video Encoder: A convolutional neural network that extracts visual features from the video frames.
- Diagram Encoder: A text-based encoder that processes the textual descriptions associated with the diagram elements.
- Alignment Module: A module that compares the video and diagram encodings to identify the best temporal alignment between the two.
During training, the model is provided with pairs of instructional videos and diagrams, and it learns to predict the start and end timestamps in the video that correspond to each step in the diagram. The authors use a correlation-guided attention mechanism to capture the temporal dependencies between the video and diagram elements.
The researchers evaluate their model on a dataset of unconstrained instructional videos and diagrams, and demonstrate that it outperforms various baselines in accurately localizing the relevant video segments for each diagram element. They also show that the model can generalize to novel video-diagram pairs, indicating its potential for real-world applications.
Critical Analysis
The paper presents a compelling approach for aligning instructional videos and diagrams, which could have important practical applications. However, there are a few potential limitations and areas for further research:
-
Dataset and Evaluation: The experiments are conducted on a relatively small dataset of instructional videos and diagrams. It would be valuable to evaluate the model's performance on a larger and more diverse set of examples, including videos with more complex or noisy content.
-
Robustness to Variations: The paper focuses on aligning videos and diagrams that are well-matched in terms of the instructional content. It's unclear how the model would perform in cases where the video and diagram content are not perfectly aligned or have significant differences.
-
Interpretability: While the model demonstrates strong performance, the inner workings of the alignment module are not entirely transparent. Providing more insight into how the model arrives at its predictions could make the system more interpretable and trustworthy.
-
Potential Biases: As with many machine learning systems, there may be biases present in the training data or model architecture that could lead to unintended consequences. Careful analysis of the model's behavior and potential sources of bias would be important before deploying such a system in real-world applications.
Overall, the research presented in this paper represents an interesting and valuable contribution to the field of multimodal video analysis. With further refinement and validation, the proposed approach could find practical use in a variety of educational and instructional contexts.
Conclusion
This paper introduces a novel method for temporally grounding instructional diagrams within unconstrained videos. By combining visual and textual cues, the model can accurately align the relevant video segments with the corresponding diagram elements, enabling users to seamlessly navigate between the visual demonstration and the step-by-step instructions.
The demonstrated ability to connect instructional videos and diagrams has the potential to enhance educational and training experiences, as well as facilitate other video analysis tasks. As the research continues to evolve, it will be important to address the limitations and explore the broader implications of this technology for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Temporally Grounding Instructional Diagrams in Unconstrained Videos
Jiahao Zhang, Frederic Z. Zhang, Cristian Rodriguez, Yizhak Ben-Shabat, Anoop Cherian, Stephen Gould
We study the challenging problem of simultaneously localizing a sequence of queries in the form of instructional diagrams in a video. This requires understanding not only the individual queries but also their interrelationships. However, most existing methods focus on grounding one query at a time, ignoring the inherent structures among queries such as the general mutual exclusiveness and the temporal order. Consequently, the predicted timespans of different step diagrams may overlap considerably or violate the temporal order, thus harming the accuracy. In this paper, we tackle this issue by simultaneously grounding a sequence of step diagrams. Specifically, we propose composite queries, constructed by exhaustively pairing up the visual content features of the step diagrams and a fixed number of learnable positional embeddings. Our insight is that self-attention among composite queries carrying different content features suppress each other to reduce timespan overlaps in predictions, while the cross-attention corrects the temporal misalignment via content and position joint guidance. We demonstrate the effectiveness of our approach on the IAW dataset for grounding step diagrams and the YouCook2 benchmark for grounding natural language queries, significantly outperforming existing methods while simultaneously grounding multiple queries.
Read more8/2/2024
0
Video sentence grounding with temporally global textual knowledge
Cai Chen, Runzhong Zhang, Jianjun Gao, Kejun Wu, Kim-Hui Yap, Yi Wang
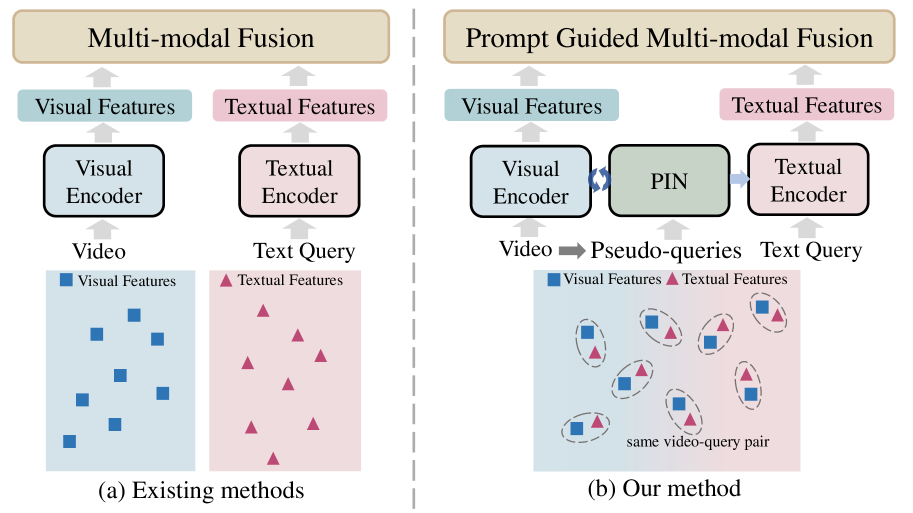
Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
Read more6/4/2024
0
Multi-Sentence Grounding for Long-term Instructional Video
Zeqian Li, Qirui Chen, Tengda Han, Ya Zhang, Yanfeng Wang, Weidi Xie
In this paper, we aim to establish an automatic, scalable pipeline for denoising the large-scale instructional dataset and construct a high-quality video-text dataset with multiple descriptive steps supervision, named HowToStep. We make the following contributions: (i) improving the quality of sentences in dataset by upgrading ASR systems to reduce errors from speech recognition and prompting a large language model to transform noisy ASR transcripts into descriptive steps; (ii) proposing a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to temporally align the generated steps to corresponding video segments. To measure the quality of our curated datasets, we train models for the task of multi-sentence grounding on it, i.e., given a long-form video, and associated multiple sentences, to determine their corresponding timestamps in the video simultaneously, as a result, the model shows superior performance on a series of multi-sentence grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.0% on HT-Step, 5.1% on HTM-Align and 1.9% on CrossTask. All codes, models, and the resulting dataset have been publicly released.
Read more7/23/2024
👁️
0
What, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Brian Chen, Nina Shvetsova, Andrew Rouditchenko, Daniel Kondermann, Samuel Thomas, Shih-Fu Chang, Rogerio Feris, James Glass, Hilde Kuehne
Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
Read more5/30/2024