Text2Place: Affordance-aware Text Guided Human Placement

0

Sign in to get full access
Overview
- Introduces a new method called "Text2Place" for placing human figures in images based on text descriptions
- Leverages affordance-aware representations to understand where a human can be placed in a scene
- Enables users to interactively place human figures in images by providing text descriptions
Plain English Explanation
The research paper presents a new approach called "Text2Place" that allows users to place human figures in images based on text descriptions. The key idea is to use "affordance-aware" representations, which capture information about how different parts of a scene can be used or interacted with.
For example, a chair affords sitting, while a table affords placing objects on top of it. The Text2Place method leverages these affordance cues to understand where a human figure can be appropriately placed in a scene based on the text description provided by the user.
This allows users to interactively place human figures in images in a way that is grounded in the physical and functional properties of the scene. For instance, a user could describe "a person sitting on a chair in the living room" and the system would place the human figure on the chair, respecting the affordances of the furniture and the room layout.
Technical Explanation
The core contribution of the Text2Place method is an affordance-aware representation that captures the functional and spatial properties of a scene. This representation is learned from a large dataset of human-annotated images and text descriptions.
During inference, the system takes a text description as input and uses language models to extract relevant semantic and spatial information. It then matches this to the affordance-aware representation of the input image to identify suitable placement locations for the human figure.
The authors evaluate Text2Place on a benchmark dataset of images and text descriptions, demonstrating that it outperforms previous text-guided image editing approaches in terms of placing human figures in a realistic and contextually appropriate manner.
Critical Analysis
The Text2Place method represents an interesting advance in the field of human-centric scene understanding. By incorporating affordance-aware representations, the system is able to ground the placement of human figures in the physical and functional properties of the scene.
However, the paper does not extensively discuss the limitations of the approach. For example, it is unclear how well the system would perform on highly cluttered or complex scenes, or how sensitive it is to errors in the underlying affordance representations.
Additionally, the paper does not explore potential biases in the training data or the language models used, which could lead to problematic placements in certain contexts. Further research is needed to understand the broader implications and fairness considerations of this type of technology.
Conclusion
The Text2Place method presents a novel approach for placing human figures in images based on text descriptions. By leveraging affordance-aware representations, the system is able to ground the placement of human figures in the physical and functional properties of the scene.
This work has the potential to enable more intuitive and contextually appropriate human-in-the-loop image editing capabilities. However, further research is needed to address the limitations and potential biases of the approach.
Overall, the Text2Place method represents an interesting step forward in the field of human-centric scene understanding and interactive image editing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Text2Place: Affordance-aware Text Guided Human Placement
Rishubh Parihar, Harsh Gupta, Sachidanand VS, R. Venkatesh Babu
For a given scene, humans can easily reason for the locations and pose to place objects. Designing a computational model to reason about these affordances poses a significant challenge, mirroring the intuitive reasoning abilities of humans. This work tackles the problem of realistic human insertion in a given background scene termed as textbf{Semantic Human Placement}. This task is extremely challenging given the diverse backgrounds, scale, and pose of the generated person and, finally, the identity preservation of the person. We divide the problem into the following two stages textbf{i)} learning textit{semantic masks} using text guidance for localizing regions in the image to place humans and textbf{ii)} subject-conditioned inpainting to place a given subject adhering to the scene affordance within the textit{semantic masks}. For learning semantic masks, we leverage rich object-scene priors learned from the text-to-image generative models and optimize a novel parameterization of the semantic mask, eliminating the need for large-scale training. To the best of our knowledge, we are the first ones to provide an effective solution for realistic human placements in diverse real-world scenes. The proposed method can generate highly realistic scene compositions while preserving the background and subject identity. Further, we present results for several downstream tasks - scene hallucination from a single or multiple generated persons and text-based attribute editing. With extensive comparisons against strong baselines, we show the superiority of our method in realistic human placement.
Read more7/23/2024

0
MSSPlace: Multi-Sensor Place Recognition with Visual and Text Semantics
Alexander Melekhin, Dmitry Yudin, Ilia Petryashin, Vitaly Bezuglyj
Place recognition is a challenging task in computer vision, crucial for enabling autonomous vehicles and robots to navigate previously visited environments. While significant progress has been made in learnable multimodal methods that combine onboard camera images and LiDAR point clouds, the full potential of these methods remains largely unexplored in localization applications. In this paper, we study the impact of leveraging a multi-camera setup and integrating diverse data sources for multimodal place recognition, incorporating explicit visual semantics and text descriptions. Our proposed method named MSSPlace utilizes images from multiple cameras, LiDAR point clouds, semantic segmentation masks, and text annotations to generate comprehensive place descriptors. We employ a late fusion approach to integrate these modalities, providing a unified representation. Through extensive experiments on the Oxford RobotCar and NCLT datasets, we systematically analyze the impact of each data source on the overall quality of place descriptors. Our experiments demonstrate that combining data from multiple sensors significantly improves place recognition model performance compared to single modality approaches and leads to state-of-the-art quality. We also show that separate usage of visual or textual semantics (which are more compact representations of sensory data) can achieve promising results in place recognition. The code for our method is publicly available: https://github.com/alexmelekhin/MSSPlace
Read more7/23/2024

0
Text-driven Affordance Learning from Egocentric Vision
Tomoya Yoshida, Shuhei Kurita, Taichi Nishimura, Shinsuke Mori
Visual affordance learning is a key component for robots to understand how to interact with objects. Conventional approaches in this field rely on pre-defined objects and actions, falling short of capturing diverse interactions in realworld scenarios. The key idea of our approach is employing textual instruction, targeting various affordances for a wide range of objects. This approach covers both hand-object and tool-object interactions. We introduce text-driven affordance learning, aiming to learn contact points and manipulation trajectories from an egocentric view following textual instruction. In our task, contact points are represented as heatmaps, and the manipulation trajectory as sequences of coordinates that incorporate both linear and rotational movements for various manipulations. However, when we gather data for this task, manual annotations of these diverse interactions are costly. To this end, we propose a pseudo dataset creation pipeline and build a large pseudo-training dataset: TextAFF80K, consisting of over 80K instances of the contact points, trajectories, images, and text tuples. We extend existing referring expression comprehension models for our task, and experimental results show that our approach robustly handles multiple affordances, serving as a new standard for affordance learning in real-world scenarios.
Read more4/4/2024
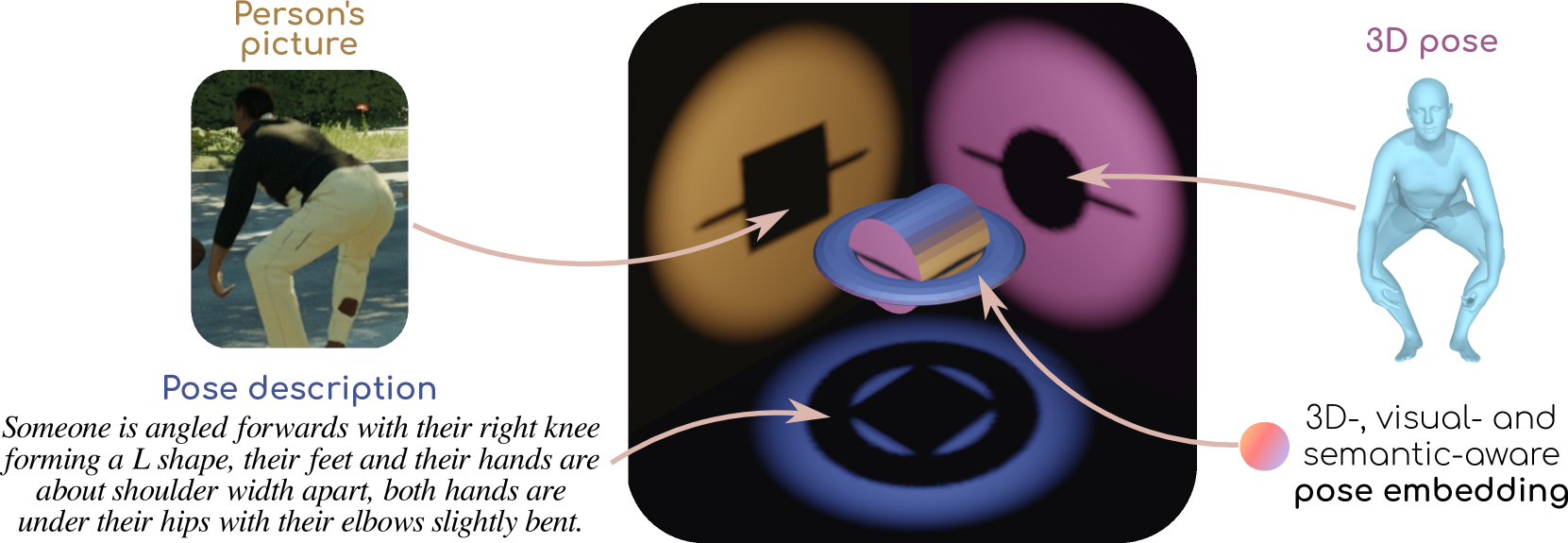
0
PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Representation
Ginger Delmas, Philippe Weinzaepfel, Francesc Moreno-Noguer, Gr'egory Rogez
Aligning multiple modalities in a latent space, such as images and texts, has shown to produce powerful semantic visual representations, fueling tasks like image captioning, text-to-image generation, or image grounding. In the context of human-centric vision, albeit CLIP-like representations encode most standard human poses relatively well (such as standing or sitting), they lack sufficient acuteness to discern detailed or uncommon ones. Actually, while 3D human poses have been often associated with images (e.g. to perform pose estimation or pose-conditioned image generation), or more recently with text (e.g. for text-to-pose generation), they have seldom been paired with both. In this work, we combine 3D poses, person's pictures and textual pose descriptions to produce an enhanced 3D-, visual- and semantic-aware human pose representation. We introduce a new transformer-based model, trained in a retrieval fashion, which can take as input any combination of the aforementioned modalities. When composing modalities, it outperforms a standard multi-modal alignment retrieval model, making it possible to sort out partial information (e.g. image with the lower body occluded). We showcase the potential of such an embroidered pose representation for (1) SMPL regression from image with optional text cue; and (2) on the task of fine-grained instruction generation, which consists in generating a text that describes how to move from one 3D pose to another (as a fitness coach). Unlike prior works, our model can take any kind of input (image and/or pose) without retraining.
Read more9/11/2024