Towards Alleviating Text-to-Image Retrieval Hallucination for CLIP in Zero-shot Learning
2402.18400
0
0
Abstract
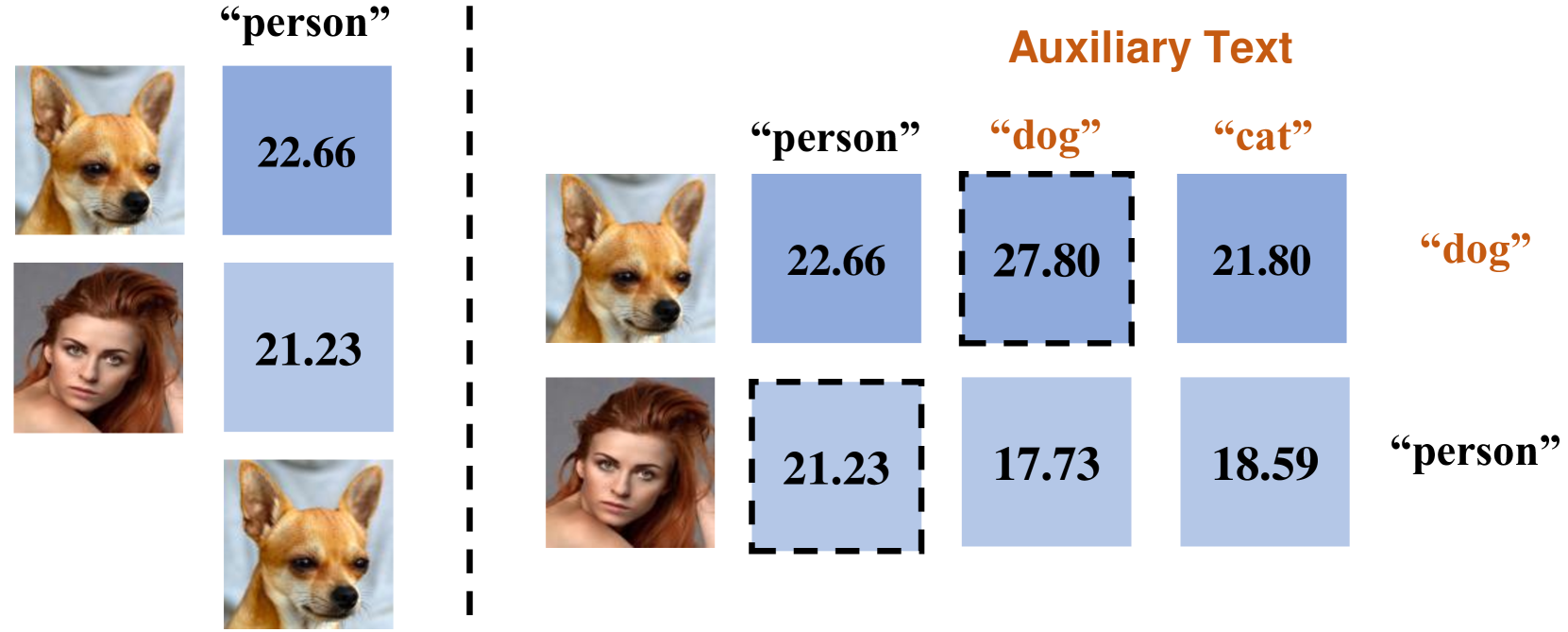
Pretrained cross-modal models, for instance, the most representative CLIP, have recently led to a boom in using pre-trained models for cross-modal zero-shot tasks, considering the generalization properties. However, we analytically discover that CLIP suffers from the text-to-image retrieval hallucination, adversely limiting its capabilities under zero-shot learning: CLIP would select the image with the highest score when asked to figure out which image perfectly matches one given query text among several candidate images even though CLIP knows contents in the image. Accordingly, we propose a Balanced Score with Auxiliary Prompts (BSAP) to mitigate the CLIP's text-to-image retrieval hallucination under zero-shot learning. Specifically, we first design auxiliary prompts to provide multiple reference outcomes for every single image retrieval, then the outcomes derived from each retrieved image in conjunction with the target text are normalized to obtain the final similarity, which alleviates hallucinations in the model. Additionally, we can merge CLIP's original results and BSAP to obtain a more robust hybrid outcome (BSAP-H). Extensive experiments on two typical zero-shot learning tasks, i.e., Referring Expression Comprehension (REC) and Referring Image Segmentation (RIS), are conducted to demonstrate the effectiveness of our BSAP. Specifically, when evaluated on the validation dataset of RefCOCO in REC, BSAP increases CLIP's performance by 20.6%. Further, we validate that our strategy could be applied in other types of pretrained cross-modal models, such as ALBEF and BLIP.
Create account to get full access
Overview
• This research paper introduces a method called "Balanced Similarity with Auxiliary Prompts" to address text-to-image retrieval bias in the CLIP model for zero-shot learning.
Plain English Explanation
• CLIP is a powerful AI model that can be used to match text and images, but it can sometimes be biased towards certain types of images.
• This new method aims to fix that by using additional "auxiliary prompts" along with the main text prompt. The auxiliary prompts help the model find a more balanced and representative set of images that match the text.
• For example, if you search for "dog" using CLIP, it might show mostly popular dog breeds. But with the new method, it could also show less common dog types, helping to reduce the bias.
• The key idea is to use the auxiliary prompts to "nudge" the model towards a more diverse and representative set of matching images, without drastically changing the core functionality.
Technical Explanation
• The paper proposes a new training strategy for the CLIP model called "Balanced Similarity with Auxiliary Prompts" (BSAP).
• BSAP introduces "auxiliary prompts" that are combined with the main text prompt during training and inference. These auxiliary prompts are designed to encourage the model to find a more balanced set of matching images.
• The auxiliary prompts are created using a novel prompt generation technique that considers factors like visual diversity, semantic coverage, and other heuristics to reduce bias.
• The authors evaluate BSAP on several zero-shot image retrieval benchmarks and show it outperforms the standard CLIP model in terms of reducing bias while maintaining strong retrieval performance.
Critical Analysis
• The paper presents a thoughtful approach to addressing an important issue in zero-shot learning - the tendency of models like CLIP to exhibit bias towards certain types of images.
• The use of auxiliary prompts is a clever idea, and the authors' prompt generation technique seems well-designed to achieve the desired effect of increasing diversity.
• However, the paper does not delve deeply into potential limitations or edge cases where the method may not work as well. It would be helpful to see more discussion of these aspects.
• Additionally, the authors could explore how BSAP might interact with or complement other bias-reduction techniques, such as those proposed in RankCLIP, Dual-Image-Enhanced CLIP, or Dual-Modal Prompting.
Conclusion
• This paper introduces a novel method called "Balanced Similarity with Auxiliary Prompts" that aims to reduce text-to-image retrieval bias in the CLIP model for zero-shot learning.
• The key innovation is the use of auxiliary prompts, which help the model find a more diverse and representative set of matching images without significantly changing its core functionality.
• The results show promising performance improvements, and the general approach could be applied to other vision-language models to address bias-related issues. Further research on the method's limitations and potential synergies with other techniques could lead to even more robust and equitable zero-shot learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024
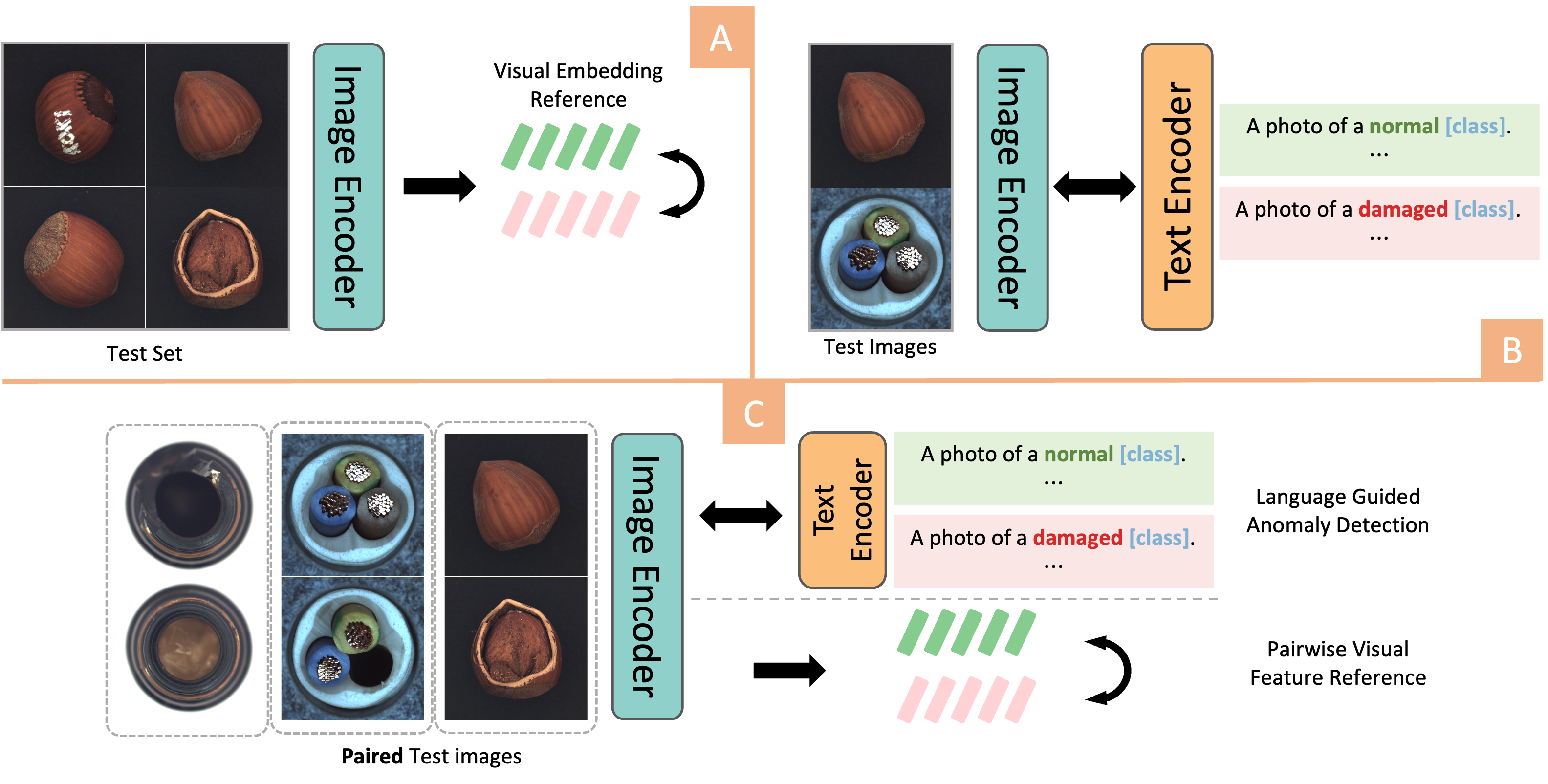
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
0
0
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
5/9/2024
🖼️
Dual-Modal Prompting for Sketch-Based Image Retrieval
Liying Gao, Bingliang Jiao, Peng Wang, Shizhou Zhang, Hanwang Zhang, Yanning Zhang
0
0
Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
4/30/2024

Unsupervised Image Prior via Prompt Learning and CLIP Semantic Guidance for Low-Light Image Enhancement
Igor Morawski, Kai He, Shusil Dangi, Winston H. Hsu
0
0
Currently, low-light conditions present a significant challenge for machine cognition. In this paper, rather than optimizing models by assuming that human and machine cognition are correlated, we use zero-reference low-light enhancement to improve the performance of downstream task models. We propose to improve the zero-reference low-light enhancement method by leveraging the rich visual-linguistic CLIP prior without any need for paired or unpaired normal-light data, which is laborious and difficult to collect. We propose a simple but effective strategy to learn prompts that help guide the enhancement method and experimentally show that the prompts learned without any need for normal-light data improve image contrast, reduce over-enhancement, and reduce noise over-amplification. Next, we propose to reuse the CLIP model for semantic guidance via zero-shot open vocabulary classification to optimize low-light enhancement for task-based performance rather than human visual perception. We conduct extensive experimental results showing that the proposed method leads to consistent improvements across various datasets regarding task-based performance and compare our method against state-of-the-art methods, showing favorable results across various low-light datasets.
5/21/2024