TimeBench: A Comprehensive Evaluation of Temporal Reasoning Abilities in Large Language Models
2311.17667
0
0

Abstract
Grasping the concept of time is a fundamental facet of human cognition, indispensable for truly comprehending the intricacies of the world. Previous studies typically focus on specific aspects of time, lacking a comprehensive temporal reasoning benchmark. To address this, we propose TimeBench, a comprehensive hierarchical temporal reasoning benchmark that covers a broad spectrum of temporal reasoning phenomena. TimeBench provides a thorough evaluation for investigating the temporal reasoning capabilities of large language models. We conduct extensive experiments on GPT-4, LLaMA2, and other popular LLMs under various settings. Our experimental results indicate a significant performance gap between the state-of-the-art LLMs and humans, highlighting that there is still a considerable distance to cover in temporal reasoning. Besides, LLMs exhibit capability discrepancies across different reasoning categories. Furthermore, we thoroughly analyze the impact of multiple aspects on temporal reasoning and emphasize the associated challenges. We aspire for TimeBench to serve as a comprehensive benchmark, fostering research in temporal reasoning. Resources are available at: https://github.com/zchuz/TimeBench
Create account to get full access
Overview
- This paper introduces the TimeBench benchmark, a comprehensive evaluation of the temporal reasoning abilities of large language models (LLMs).
- The authors argue that existing temporal reasoning benchmarks are limited in scope and do not adequately assess the full range of temporal reasoning capabilities in LLMs.
- TimeBench aims to provide a more thorough and challenging evaluation of temporal reasoning, including tasks related to temporal entailment, temporal commonsense, and spatio-temporal reasoning.
Plain English Explanation
The paper presents a new benchmark called TimeBench that is designed to thoroughly evaluate how well large language models (LLMs) can reason about time. Existing benchmarks for this type of reasoning are limited, so the authors created TimeBench to provide a more comprehensive assessment.
The key idea behind TimeBench is to test LLMs on a wide range of tasks related to understanding and reasoning about time. This includes tasks like determining if one event happened before or after another event (temporal entailment), understanding common sense knowledge about the typical duration or ordering of events (temporal commonsense), and reasoning about how events are connected in space and time (spatio-temporal reasoning).
By testing LLMs on this diverse set of temporal reasoning tasks, the authors hope to get a much more complete picture of their temporal reasoning abilities, beyond what existing benchmarks can reveal. This could help identify strengths and weaknesses in how LLMs handle temporal information, which could inform future model development and applications where temporal reasoning is important, such as assistants that can understand and reason about events over time.
Technical Explanation
The TimeBench benchmark consists of several sub-tasks that assess different aspects of temporal reasoning in LLMs. These include:
- Temporal Entailment: Evaluating whether models can correctly determine the temporal ordering of events described in text.
- Temporal Commonsense: Assessing a model's understanding of typical durations, sequences, and ordering of common real-world events.
- Spatio-Temporal Reasoning: Testing a model's ability to reason about how events are connected in both space and time.
The authors carefully designed the tasks and datasets for TimeBench to be challenging for current LLMs, going beyond what existing temporal reasoning benchmarks cover. For example, the temporal commonsense tasks require models to draw on broad world knowledge to reason about typical event timelines.
The authors evaluate several prominent LLMs on the TimeBench benchmark, including GPT-3, BART, and T5. Their results show that while these models demonstrate some temporal reasoning capabilities, they still struggle on the more challenging tasks, particularly those involving commonsense reasoning about event timelines.
Critical Analysis
The TimeBench benchmark represents a significant advancement in evaluating the temporal reasoning abilities of LLMs. By focusing on a diverse set of temporal reasoning tasks, the authors have created a more comprehensive assessment tool than previous benchmarks.
However, the paper does acknowledge some limitations of TimeBench. For instance, the datasets used, while carefully constructed, may not fully capture the nuances and complexities of real-world temporal reasoning. Additionally, the current LLM architectures may have inherent limitations in their ability to reason about time that are not easily overcome.
Further research could explore ways to enhance the TimeBench benchmark, such as incorporating more real-world data sources or testing models' temporal reasoning in interactive, multi-turn dialogues. There may also be opportunities to investigate novel LLM architectures or training approaches that could improve temporal reasoning performance.
Overall, the TimeBench benchmark is a valuable contribution to the field of language model evaluation and development. By highlighting the current limitations in temporal reasoning, it can help guide future research and drive progress in this important area of AI.
Conclusion
The TimeBench benchmark provides a comprehensive and challenging evaluation of the temporal reasoning abilities of large language models. By assessing a diverse range of temporal reasoning tasks, the authors have created a more robust tool for identifying the strengths and weaknesses of current LLMs in this domain.
The results from evaluating prominent LLMs on TimeBench suggest that while these models demonstrate some temporal reasoning capabilities, they still struggle with more complex, commonsense-based temporal reasoning. This highlights the need for continued research and development to improve LLMs' understanding and reasoning about time.
By serving as a benchmark for temporal reasoning, TimeBench can help guide future advancements in language model architectures and training approaches, ultimately leading to AI systems that can better comprehend and reason about the temporal aspects of the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, Bryan Perozzi
0
0
Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
6/14/2024
💬
TRAM: Benchmarking Temporal Reasoning for Large Language Models
Yuqing Wang, Yun Zhao
0
0
Reasoning about time is essential for understanding the nuances of events described in natural language. Previous research on this topic has been limited in scope, characterized by a lack of standardized benchmarks that would allow for consistent evaluations across different studies. In this paper, we introduce TRAM, a temporal reasoning benchmark composed of ten datasets, encompassing various temporal aspects of events such as order, arithmetic, frequency, and duration, designed to facilitate a comprehensive evaluation of the TeR capabilities of large language models (LLMs). We evaluate popular LLMs like GPT-4 and Llama2 in zero-shot and few-shot scenarios, and establish baselines with BERT-based and domain-specific models. Our findings indicate that the best-performing model lags significantly behind human performance. It is our aspiration that TRAM will spur further progress in enhancing the TeR capabilities of LLMs.
6/3/2024
Timo: Towards Better Temporal Reasoning for Language Models
Zhaochen Su, Jun Zhang, Tong Zhu, Xiaoye Qu, Juntao Li, Min Zhang, Yu Cheng
0
0
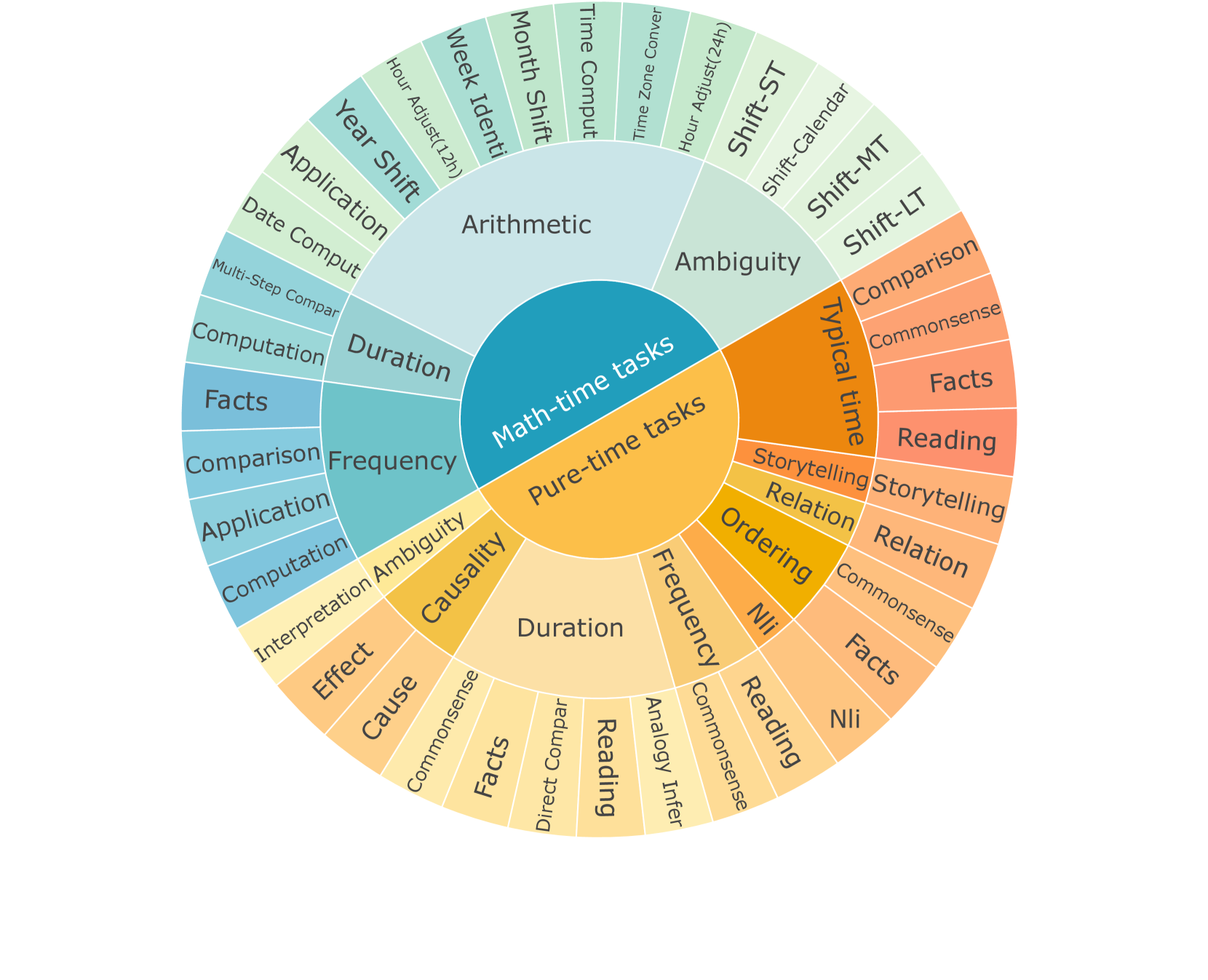
Reasoning about time is essential for Large Language Models (LLMs) to understand the world. Previous works focus on solving specific tasks, primarily on time-sensitive question answering. While these methods have proven effective, they cannot generalize to a wider spectrum of temporal reasoning tasks. Therefore, we propose a crucial question: Can we build a universal framework to handle a variety of temporal reasoning tasks? To that end, we systematically study 38 temporal reasoning tasks. Based on the observation that 19 tasks are directly related to mathematics, we first leverage the available mathematical dataset to set a solid foundation for temporal reasoning. However, the in-depth study indicates that focusing solely on mathematical enhancement falls short of addressing pure temporal reasoning tasks. To mitigate this limitation, we propose a simple but effective self-critic temporal optimization method to enhance the model's temporal reasoning capabilities without sacrificing general task abilities. Finally, we develop Timo, a model designed to excel in temporal reasoning at the 7B and 13B scales. Notably, Timo outperforms the counterpart LLMs by 10.0 and 7.6 in average accuracy scores and achieves the new state-of-the-art (SOTA) performance of comparable size. Extensive experiments further validate our framework's effectiveness and its generalization across diverse temporal tasks. The code is available at https://github.com/zhaochen0110/Timo.
6/21/2024
STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Wenbin Li, Di Yao, Ruibo Zhao, Wenjie Chen, Zijie Xu, Chengxue Luo, Chang Gong, Quanliang Jing, Haining Tan, Jingping Bi
0
0
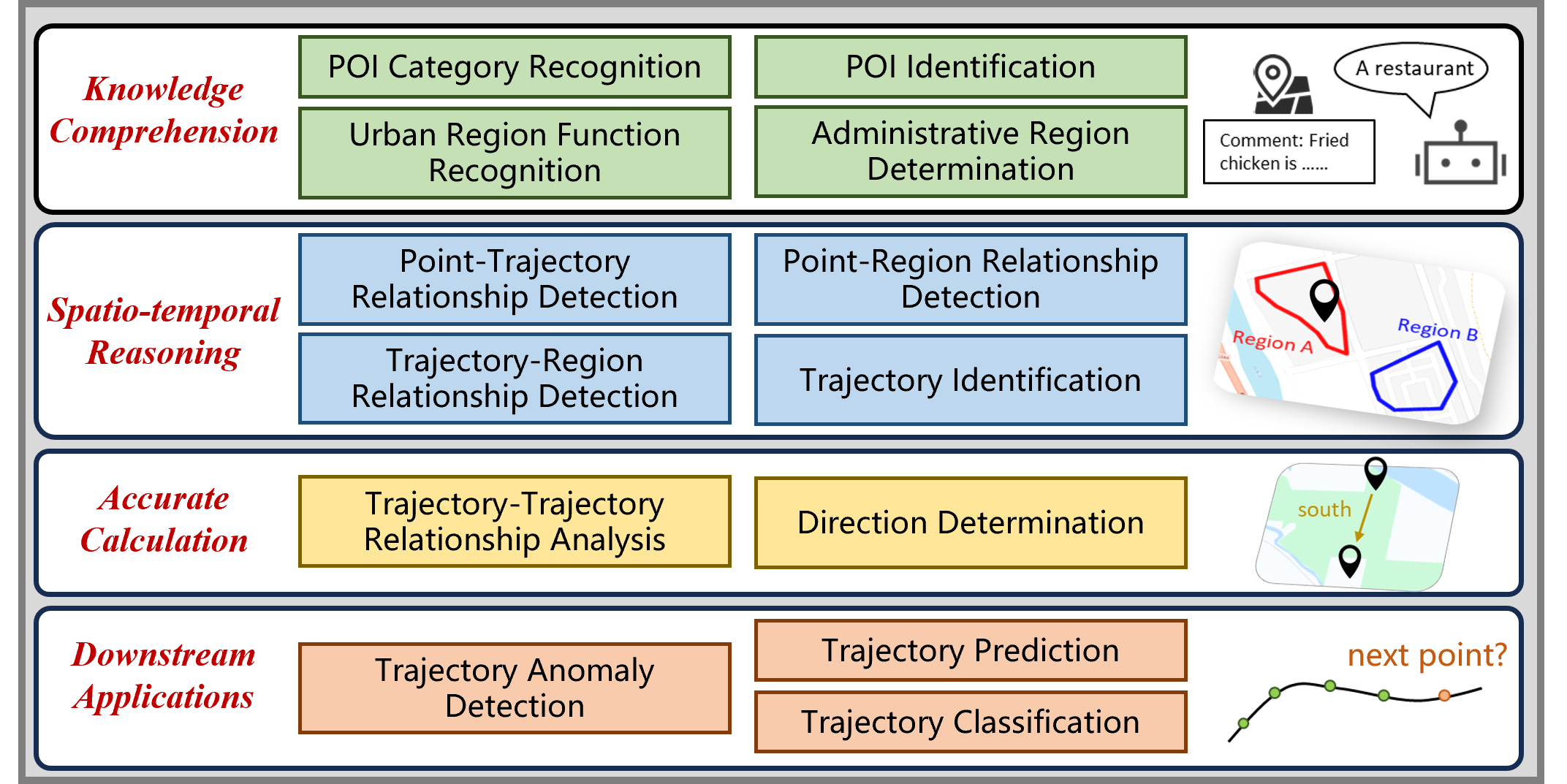
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
6/28/2024