TRAM: Benchmarking Temporal Reasoning for Large Language Models
2310.00835
0
0
💬
Abstract
Reasoning about time is essential for understanding the nuances of events described in natural language. Previous research on this topic has been limited in scope, characterized by a lack of standardized benchmarks that would allow for consistent evaluations across different studies. In this paper, we introduce TRAM, a temporal reasoning benchmark composed of ten datasets, encompassing various temporal aspects of events such as order, arithmetic, frequency, and duration, designed to facilitate a comprehensive evaluation of the TeR capabilities of large language models (LLMs). We evaluate popular LLMs like GPT-4 and Llama2 in zero-shot and few-shot scenarios, and establish baselines with BERT-based and domain-specific models. Our findings indicate that the best-performing model lags significantly behind human performance. It is our aspiration that TRAM will spur further progress in enhancing the TeR capabilities of LLMs.
Create account to get full access
Overview
- This paper introduces TRAM, a benchmark for evaluating the temporal reasoning (TeR) capabilities of large language models (LLMs).
- TRAM consists of 10 datasets covering various temporal aspects of events, such as order, arithmetic, frequency, and duration.
- The authors evaluate popular LLMs like GPT-4 and Llama2 in zero-shot and few-shot scenarios, and establish baselines with BERT-based and domain-specific models.
- The findings indicate that the best-performing model still lags significantly behind human performance in temporal reasoning tasks.
Plain English Explanation
Understanding the timing and sequence of events is crucial for comprehending natural language. However, previous research in this area has been limited, lacking standardized benchmarks that would allow for consistent evaluations across different studies.
To address this, the researchers created a new benchmark called TRAM, which includes 10 datasets covering various aspects of temporal reasoning, such as the order of events, mathematical calculations involving time, how often events occur, and the duration of events.
The researchers then tested popular large language models (LLMs), including GPT-4 and Llama2, on these tasks. They also compared the LLMs' performance to models specifically designed for temporal knowledge question answering and BERT-based models.
The results showed that even the best-performing model struggled to match the temporal reasoning abilities of humans. This suggests that LLMs still have difficulty with zero-shot learning of temporal reasoning and that more work is needed to improve the temporal awareness of LLMs for them to better understand the nuances of natural language.
Technical Explanation
The paper introduces TRAM, a benchmark for evaluating the temporal reasoning (TeR) capabilities of large language models (LLMs). TRAM consists of 10 datasets that cover various temporal aspects of events, including order, arithmetic, frequency, and duration.
The authors evaluate the performance of popular LLMs, such as GPT-4 and Llama2, on the TRAM benchmark in both zero-shot and few-shot scenarios. They also establish baselines using BERT-based models and domain-specific models designed for temporal knowledge question answering.
The results show that the best-performing model, which is a fine-tuned version of GPT-4, achieves an average accuracy of 74.7% across the TRAM datasets. However, this still lags significantly behind human performance, indicating that LLMs still struggle with zero-shot learning of temporal reasoning.
The authors suggest that the TRAM benchmark can spur further progress in enhancing the temporal reasoning capabilities of LLMs, which is essential for improving the temporal awareness of LLMs and enabling them to better understand the nuances of natural language.
Critical Analysis
The paper presents a comprehensive benchmark for evaluating the temporal reasoning capabilities of LLMs, which is a significant contribution to the field. The authors have carefully designed TRAM to cover a wide range of temporal aspects, making it a valuable tool for researchers.
However, the paper does not provide a detailed analysis of the types of errors made by the LLMs or the specific challenges they faced in different temporal reasoning tasks. Additionally, the paper does not explore the potential reasons why the best-performing model still lags behind human performance, which could have provided valuable insights for future research.
Furthermore, the paper does not discuss the potential biases or limitations of the TRAM datasets, which could impact the generalizability of the results. It would be beneficial for the authors to address these caveats and encourage readers to think critically about the research.
Overall, the paper presents a promising benchmark and a solid starting point for further research on enhancing the temporal reasoning capabilities of LLMs. However, there is room for more in-depth analysis and exploration of the underlying challenges and potential solutions.
Conclusion
This paper introduces TRAM, a comprehensive benchmark for evaluating the temporal reasoning capabilities of large language models. The results show that even the best-performing model lags significantly behind human performance, indicating that there is still room for improvement in this area.
The TRAM benchmark can serve as a valuable tool for researchers to drive further progress in enhancing the temporal reasoning capabilities of LLMs, which is essential for improving their understanding of natural language and enabling them to better comprehend the nuances of events described in text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!TimeBench: A Comprehensive Evaluation of Temporal Reasoning Abilities in Large Language Models
Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, Bing Qin
0
0
Grasping the concept of time is a fundamental facet of human cognition, indispensable for truly comprehending the intricacies of the world. Previous studies typically focus on specific aspects of time, lacking a comprehensive temporal reasoning benchmark. To address this, we propose TimeBench, a comprehensive hierarchical temporal reasoning benchmark that covers a broad spectrum of temporal reasoning phenomena. TimeBench provides a thorough evaluation for investigating the temporal reasoning capabilities of large language models. We conduct extensive experiments on GPT-4, LLaMA2, and other popular LLMs under various settings. Our experimental results indicate a significant performance gap between the state-of-the-art LLMs and humans, highlighting that there is still a considerable distance to cover in temporal reasoning. Besides, LLMs exhibit capability discrepancies across different reasoning categories. Furthermore, we thoroughly analyze the impact of multiple aspects on temporal reasoning and emphasize the associated challenges. We aspire for TimeBench to serve as a comprehensive benchmark, fostering research in temporal reasoning. Resources are available at: https://github.com/zchuz/TimeBench
7/1/2024
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, Bryan Perozzi
0
0
Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
6/14/2024
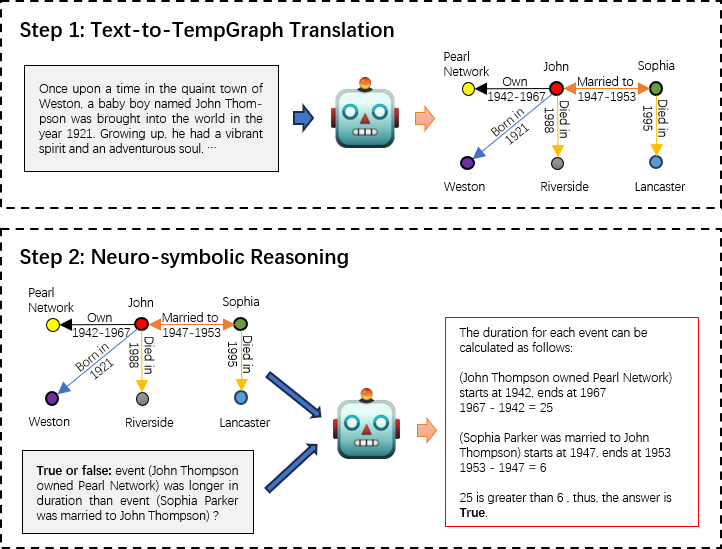
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
0
0
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal concepts and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that enhances the learning of TR. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain-of-Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
6/12/2024

Living in the Moment: Can Large Language Models Grasp Co-Temporal Reasoning?
Zhaochen Su, Juntao Li, Jun Zhang, Tong Zhu, Xiaoye Qu, Pan Zhou, Yan Bowen, Yu Cheng, Min zhang
0
0
Temporal reasoning is fundamental for large language models (LLMs) to comprehend the world. Current temporal reasoning datasets are limited to questions about single or isolated events, falling short in mirroring the realistic temporal characteristics involving concurrent nature and intricate temporal interconnections. In this paper, we introduce CoTempQA, a comprehensive co-temporal Question Answering (QA) benchmark containing four co-temporal scenarios (Equal, Overlap, During, Mix) with 4,748 samples for evaluating the co-temporal comprehension and reasoning abilities of LLMs. Our extensive experiments reveal a significant gap between the performance of current LLMs and human-level reasoning on CoTempQA tasks. Even when enhanced with Chain of Thought (CoT) methodologies, models consistently struggle with our task. In our preliminary exploration, we discovered that mathematical reasoning plays a significant role in handling co-temporal events and proposed a strategy to boost LLMs' co-temporal reasoning from a mathematical perspective. We hope that our CoTempQA datasets will encourage further advancements in improving the co-temporal reasoning capabilities of LLMs. Our code is available at https://github.com/zhaochen0110/Cotempqa.
6/14/2024