TinyLVLM-eHub: Towards Comprehensive and Efficient Evaluation for Large Vision-Language Models

0
⛏️
Sign in to get full access
Overview
- Large Vision-Language Models (LVLMs) have made significant advancements in complex multimodal tasks.
- Google's Bard stands out for its remarkable multimodal capabilities, promoting comprehensive comprehension and reasoning across various domains.
- This work presents an early and holistic evaluation of LVLMs' multimodal abilities, with a focus on Bard, by proposing a lightweight variant of LVLM-eHub, named Tiny LVLM-eHub.
Plain English Explanation
Advancements in Large Vision-Language Models (LVLMs) have led to significant progress in tackling complex tasks that involve both text and images. Among these cutting-edge developments, Google's Bard stands out for its remarkable ability to understand and reason about multimodal information, spanning various domains.
This research presents an early and comprehensive evaluation of LVLMs' multimodal capabilities, with a particular focus on Bard. The researchers propose a lightweight version of the LVLM-eHub evaluation framework, called Tiny LVLM-eHub, which offers several appealing features:
- It systematically assesses six categories of multimodal capabilities, including visual perception, visual knowledge acquisition, visual reasoning, visual commonsense, object hallucination, and embodied intelligence, through quantitative evaluation of 42 standard text-related visual benchmarks.
- It conducts an in-depth analysis of LVLMs' predictions using the ChatGPT Ensemble Evaluation (CEE) approach, which leads to a robust and accurate evaluation, and exhibits improved alignment with human evaluation compared to the traditional word matching approach.
- It comprises a small dataset of only 2.1K image-text pairs, making it easy for practitioners to use and evaluate their own offline LVLMs.
Through extensive experiments, the study demonstrates that Bard outperforms previous LVLMs in most multimodal capabilities, except for object hallucination, which is still a challenge for Bard. Tiny LVLM-eHub serves as a valuable baseline for evaluating various LVLMs and encourages the development of innovative strategies to advance multimodal techniques.
Technical Explanation
The research paper presents a comprehensive evaluation of Large Vision-Language Models (LVLMs), with a particular focus on Google's Bard, by proposing a lightweight variant of the LVLM-eHub framework, called Tiny LVLM-eHub.
Tiny LVLM-eHub provides a systematic assessment of six categories of multimodal capabilities: visual perception, visual knowledge acquisition, visual reasoning, visual commonsense, object hallucination, and embodied intelligence. It evaluates these capabilities through quantitative analysis of 42 standard text-related visual benchmarks.
To conduct a robust and accurate evaluation, the researchers employ the ChatGPT Ensemble Evaluation (CEE) approach, which exhibits improved alignment with human evaluation compared to the traditional word matching approach.
Moreover, Tiny LVLM-eHub comprises a compact dataset of 2.1K image-text pairs, making it easily accessible and usable for practitioners to evaluate their own offline LVLMs.
The experimental analysis reveals that Bard outperforms previous LVLMs in most multimodal capabilities, except for object hallucination, which remains a challenge. Tiny LVLM-eHub serves as a baseline evaluation framework for various LVLMs and encourages the development of innovative strategies to advance multimodal techniques.
Critical Analysis
The research paper provides a comprehensive and systematic evaluation of LVLMs' multimodal capabilities, with a particular focus on Google's Bard. The proposed Tiny LVLM-eHub framework offers several advantages, such as a more robust evaluation approach and a lightweight dataset, making it accessible for practitioners.
However, the paper does not delve into the potential limitations or caveats of the evaluation methodology. It would be beneficial to understand the specific challenges or biases inherent in the selected benchmarks or the CEE approach, as these could impact the generalizability of the findings.
Additionally, the paper does not explore the potential ethical implications or concerns regarding the deployment of such powerful multimodal models, such as the risk of biased or harmful outputs, or the privacy and security implications of these models' abilities.
Further research could investigate the performance of Bard and other LVLMs on more diverse and representative datasets, as well as explore strategies to address the identified shortcomings, such as object hallucination. Engaging in a deeper critical analysis of the research and its implications could also help advance the field and promote responsible development of multimodal AI systems.
Conclusion
This research presents a comprehensive and insightful evaluation of Large Vision-Language Models (LVLMs), with a particular focus on Google's Bard. The proposed Tiny LVLM-eHub framework offers a systematic and robust assessment of LVLMs' multimodal capabilities, spanning six key dimensions.
The findings demonstrate that Bard outperforms previous LVLMs in most multimodal tasks, showcasing its remarkable progress in understanding and reasoning about complex text-image relationships. However, the study also identifies object hallucination as an area where Bard still faces challenges.
Tiny LVLM-eHub serves as a valuable baseline for evaluating various LVLMs and encourages the development of innovative strategies to further advance multimodal techniques. As the field of multimodal AI continues to evolve, this research contributes to a better understanding of the current state of the art and highlights the need for ongoing critical analysis and responsible development of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
TinyLVLM-eHub: Towards Comprehensive and Efficient Evaluation for Large Vision-Language Models
Wenqi Shao, Meng Lei, Yutao Hu, Peng Gao, Kaipeng Zhang, Fanqing Meng, Peng Xu, Siyuan Huang, Hongsheng Li, Yu Qiao, Ping Luo
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated significant progress in tackling complex multimodal tasks. Among these cutting-edge developments, Google's Bard stands out for its remarkable multimodal capabilities, promoting comprehensive comprehension and reasoning across various domains. This work presents an early and holistic evaluation of LVLMs' multimodal abilities, with a particular focus on Bard, by proposing a lightweight variant of LVLM-eHub, named Tiny LVLM-eHub. In comparison to the vanilla version, Tiny LVLM-eHub possesses several appealing properties. Firstly, it provides a systematic assessment of six categories of multimodal capabilities, including visual perception, visual knowledge acquisition, visual reasoning, visual commonsense, object hallucination, and embodied intelligence, through quantitative evaluation of $42$ standard text-related visual benchmarks. Secondly, it conducts an in-depth analysis of LVLMs' predictions using the ChatGPT Ensemble Evaluation (CEE), which leads to a robust and accurate evaluation and exhibits improved alignment with human evaluation compared to the word matching approach. Thirdly, it comprises a mere $2.1$K image-text pairs, facilitating ease of use for practitioners to evaluate their own offline LVLMs. Through extensive experimental analysis, this study demonstrates that Bard outperforms previous LVLMs in most multimodal capabilities except object hallucination, to which Bard is still susceptible. Tiny LVLM-eHub serves as a baseline evaluation for various LVLMs and encourages innovative strategies aimed at advancing multimodal techniques. Our project is publicly available at url{https://github.com/OpenGVLab/Multi-Modality-Arena}.
Read more8/13/2024

0
Behind the Magic, MERLIM: Multi-modal Evaluation Benchmark for Large Image-Language Models
Andr'es Villa, Juan Carlos Le'on Alc'azar, Alvaro Soto, Bernard Ghanem
Large Vision and Language Models have enabled significant advances in fully supervised and zero-shot visual tasks. These large architectures serve as the baseline to what is currently known as Instruction Tuning Large Vision and Language models (IT-LVLMs). IT-LVLMs are general-purpose multi-modal assistants whose responses are modulated by natural language instructions and visual data. Despite this versatility, IT-LVLM effectiveness in fundamental computer vision problems remains unclear, primarily due to the absence of a standardized evaluation benchmark. This paper introduces a Multi-modal Evaluation Benchmark named MERLIM, a scalable test-bed to assess the capabilities of IT-LVLMs on fundamental computer vision tasks. MERLIM contains over 300K image-question pairs and has a strong focus on detecting cross-modal hallucination events in IT-LVLMs. Our results bring important insights on the performance of state-of-the-art IT-LVMLs including limitations at identifying fine-grained visual concepts, object hallucinations across tasks, and biases towards the language query. Our findings also suggest that these models have weak visual grounding, but manage to make adequate guesses from global visual patterns or language biases contained in the LLM component.
Read more6/13/2024
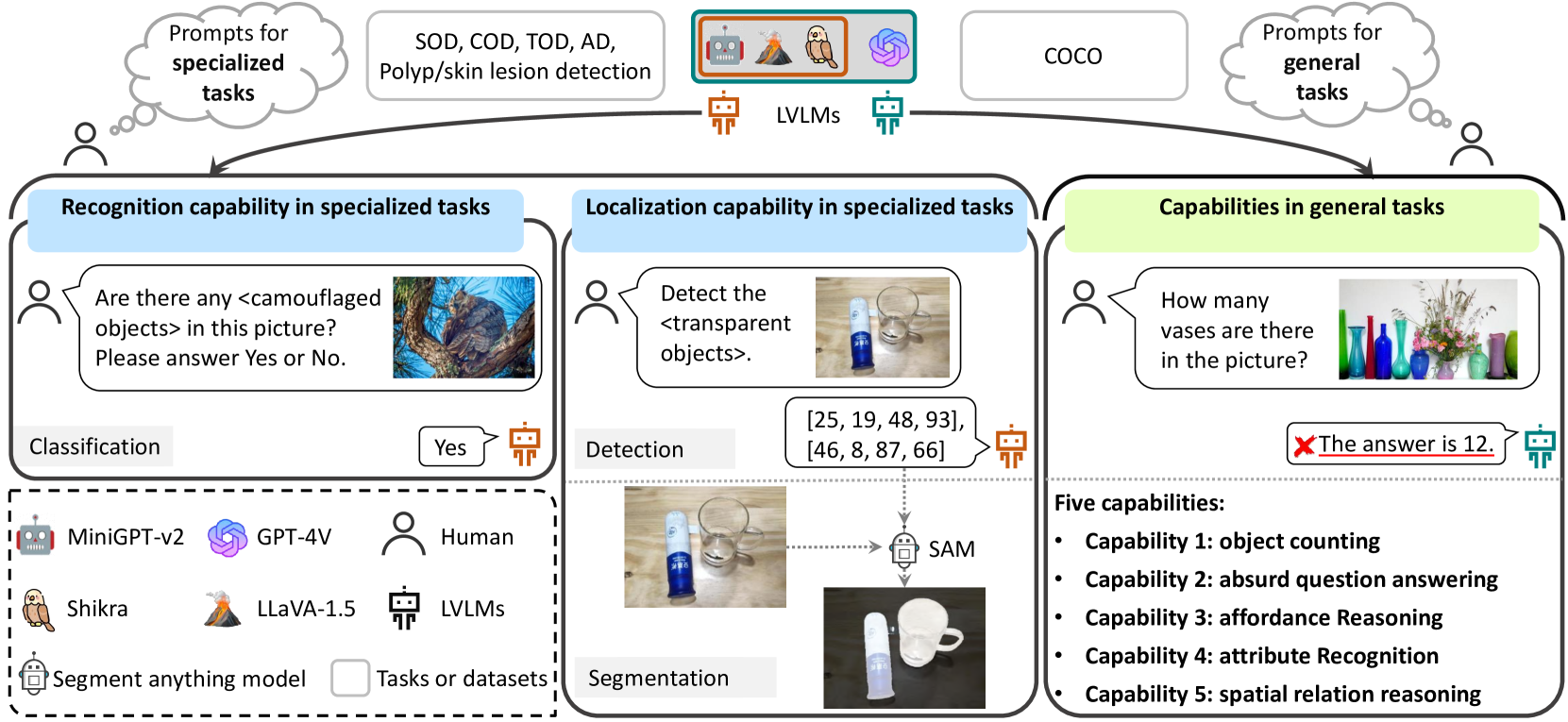
0
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
The advent of large vision-language models (LVLMs) represents a remarkable advance in the quest for artificial general intelligence. However, the model's effectiveness in both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their effectiveness in specialized tasks, we employ six challenging tasks in three different application scenarios: natural, healthcare, and industrial. These six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization in these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope that this study can provide useful insights for the future development of LVLMs, helping researchers improve LVLMs for both general and specialized applications.
Read more6/12/2024

1
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, Feng Zhao
Large vision-language models (LVLMs) have recently achieved rapid progress, sparking numerous studies to evaluate their multi-modal capabilities. However, we dig into current evaluation works and identify two primary issues: 1) Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. This phenomenon is prevalent across current benchmarks. For instance, GeminiPro achieves 42.9% on the MMMU benchmark without any visual input, and outperforms the random choice baseline across six benchmarks over 24% on average. 2) Unintentional data leakage exists in LLM and LVLM training. LLM and LVLM could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data. For example, Sphinx-X-MoE gets 43.6% on MMMU without accessing images, surpassing its LLM backbone with 17.9%. Both problems lead to misjudgments of actual multi-modal gains and potentially misguide the study of LVLM. To this end, we present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks 6 core capabilities and 18 detailed axes, aiming to evaluate LVLMs' multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline, human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training. We evaluate 16 leading LVLMs on MMStar to assess their multi-modal capabilities, and on 7 benchmarks with the proposed metrics to investigate their data leakage and actual multi-modal gain.
Read more4/10/2024