TinyTNAS: GPU-Free, Time-Bound, Hardware-Aware Neural Architecture Search for TinyML Time Series Classification

0

Sign in to get full access
Overview
- TinyTNAS is a neural architecture search (NAS) method for time series classification on resource-constrained devices.
- It aims to find efficient neural network architectures without using GPU-based search.
- The search is time-bounded and hardware-aware, tailoring the models to specific target devices.
Plain English Explanation
TinyTNAS is a way to automatically design efficient neural network models for classifying time series data on small, low-power devices like microcontrollers or sensors. Normally, designing these models requires a lot of trial-and-error and expertise. TinyTNAS automates this process by searching through a space of possible neural network architectures to find ones that are small, fast, and work well on the target hardware.
The key ideas behind TinyTNAS are:
- GPU-Free: It does the search on regular CPUs instead of requiring expensive GPUs, making it more accessible.
- Time-Bounded: The search is limited to a fixed time budget, so it can be practical for real-world deployment.
- Hardware-Aware: The search takes into account the specific capabilities of the target device, like memory size and compute power, to find models that will run efficiently on that hardware.
By automating this process, TinyTNAS makes it easier for developers to create highly optimized neural network models for low-power devices, which is crucial for applications like Internet of Things (IoT) and embedded systems.
Technical Explanation
TinyTNAS is a neural architecture search (NAS) method designed for time series classification on resource-constrained devices. The key innovation is that it performs the search process entirely on CPUs, without relying on GPUs. This makes it more accessible and practical for real-world deployment.
The search process is also time-bounded, meaning it will terminate after a fixed amount of time, rather than running indefinitely. This ensures the search can be completed within a reasonable timeframe, which is important for practical applications.
Additionally, TinyTNAS is hardware-aware, meaning it takes into account the specific capabilities of the target device, such as memory size and compute power. This allows it to find models that not only perform well on the task, but also run efficiently on the target hardware, which is crucial for tiny machine learning (TinyML) applications.
The authors evaluate TinyTNAS on several time series classification benchmarks and demonstrate that it can find efficient neural network architectures that outperform manually designed models, while maintaining a low computational footprint. This suggests that TinyTNAS is a promising approach for automating the design of optimized neural networks for resource-constrained devices.
Critical Analysis
The authors of the TinyTNAS paper acknowledge several limitations and potential areas for further research:
- Search Space Exploration: The current version of TinyTNAS uses a relatively simple search space, focusing on common neural network building blocks. Exploring more diverse and potentially more powerful architectural components could lead to further improvements.
- Hardware Modeling Accuracy: The hardware-aware aspect of TinyTNAS relies on modeling the target device's performance characteristics. Improving the accuracy of these models could help TinyTNAS make even better-informed decisions during the search process.
- Generalization to Other Domains: While the paper demonstrates the effectiveness of TinyTNAS for time series classification, it would be valuable to explore its performance on other types of tiny machine learning tasks, such as image recognition or natural language processing.
Overall, TinyTNAS represents an interesting and practical approach to neural architecture search for resource-constrained devices. The authors have made a valuable contribution by addressing the challenges of GPU-dependence, time-boundedness, and hardware-awareness in the NAS process. Further research in this direction could lead to even more efficient and widely applicable solutions for deploying machine learning models on low-power systems.
Conclusion
TinyTNAS is a novel neural architecture search method designed for time series classification on resource-constrained devices. By performing the search entirely on CPUs, limiting the search time, and taking the target hardware into account, TinyTNAS addresses several key challenges in deploying efficient neural networks on tiny machine learning applications. The authors have demonstrated the effectiveness of their approach on benchmark datasets, and the work opens up interesting avenues for further research in automating the design of optimized neural networks for low-power systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TinyTNAS: GPU-Free, Time-Bound, Hardware-Aware Neural Architecture Search for TinyML Time Series Classification
Bidyut Saha, Riya Samanta, Soumya K. Ghosh, Ram Babu Roy
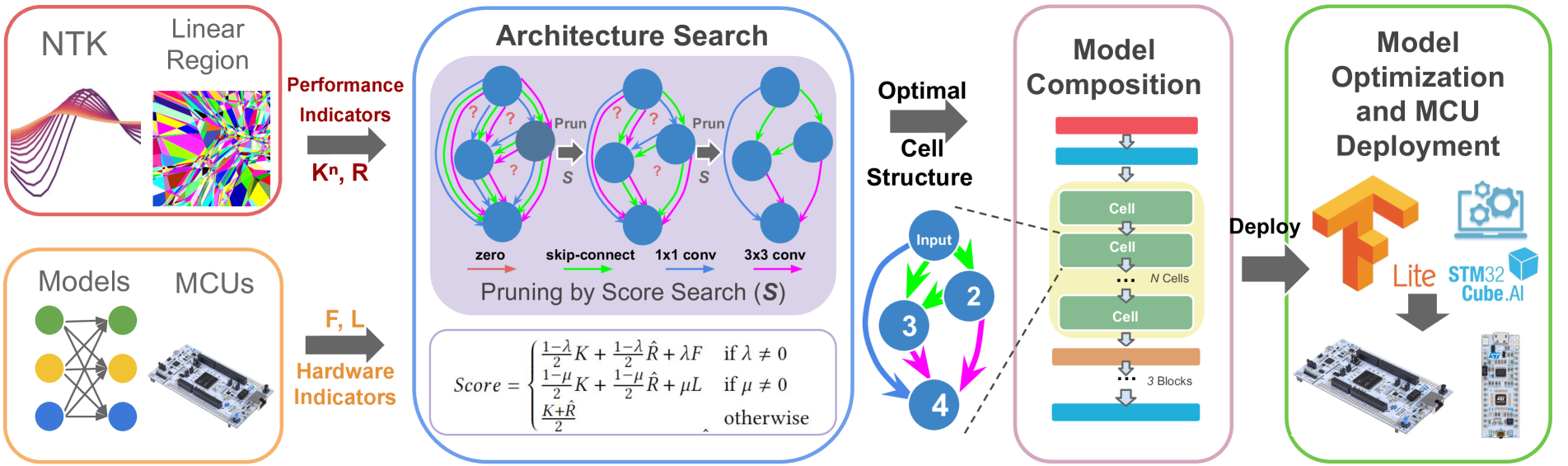
In this work, we present TinyTNAS, a novel hardware-aware multi-objective Neural Architecture Search (NAS) tool specifically designed for TinyML time series classification. Unlike traditional NAS methods that rely on GPU capabilities, TinyTNAS operates efficiently on CPUs, making it accessible for a broader range of applications. Users can define constraints on RAM, FLASH, and MAC operations to discover optimal neural network architectures within these parameters. Additionally, the tool allows for time-bound searches, ensuring the best possible model is found within a user-specified duration. By experimenting with benchmark dataset UCI HAR, PAMAP2, WISDM, MIT BIH, and PTB Diagnostic ECG Databas TinyTNAS demonstrates state-of-the-art accuracy with significant reductions in RAM, FLASH, MAC usage, and latency. For example, on the UCI HAR dataset, TinyTNAS achieves a 12x reduction in RAM usage, a 144x reduction in MAC operations, and a 78x reduction in FLASH memory while maintaining superior accuracy and reducing latency by 149x. Similarly, on the PAMAP2 and WISDM datasets, it achieves a 6x reduction in RAM usage, a 40x reduction in MAC operations, an 83x reduction in FLASH, and a 67x reduction in latency, all while maintaining superior accuracy. Notably, the search process completes within 10 minutes in a CPU environment. These results highlight TinyTNAS's capability to optimize neural network architectures effectively for resource-constrained TinyML applications, ensuring both efficiency and high performance. The code for TinyTNAS is available at the GitHub repository and can be accessed at https://github.com/BidyutSaha/TinyTNAS.git.
Read more8/30/2024
0
MONAS: Efficient Zero-Shot Neural Architecture Search for MCUs
Ye Qiao, Haocheng Xu, Yifan Zhang, Sitao Huang
Neural Architecture Search (NAS) has proven effective in discovering new Convolutional Neural Network (CNN) architectures, particularly for scenarios with well-defined accuracy optimization goals. However, previous approaches often involve time-consuming training on super networks or intensive architecture sampling and evaluations. Although various zero-cost proxies correlated with CNN model accuracy have been proposed for efficient architecture search without training, their lack of hardware consideration makes it challenging to target highly resource-constrained edge devices such as microcontroller units (MCUs). To address these challenges, we introduce MONAS, a novel hardware-aware zero-shot NAS framework specifically designed for MCUs in edge computing. MONAS incorporates hardware optimality considerations into the search process through our proposed MCU hardware latency estimation model. By combining this with specialized performance indicators (proxies), MONAS identifies optimal neural architectures without incurring heavy training and evaluation costs, optimizing for both hardware latency and accuracy under resource constraints. MONAS achieves up to a 1104x improvement in search efficiency over previous work targeting MCUs and can discover CNN models with over 3.23x faster inference on MCUs while maintaining similar accuracy compared to more general NAS approaches.
Read more8/28/2024

0
HASNAS: A Hardware-Aware Spiking Neural Architecture Search Framework for Neuromorphic Compute-in-Memory Systems
Rachmad Vidya Wicaksana Putra, Muhammad Shafique
Spiking Neural Networks (SNNs) have shown capabilities for solving diverse machine learning tasks with ultra-low-power/energy computation. To further improve the performance and efficiency of SNN inference, the Compute-in-Memory (CIM) paradigm with emerging device technologies such as resistive random access memory is employed. However, most of SNN architectures are developed without considering constraints from the application and the underlying CIM hardware (e.g., memory, area, latency, and energy consumption). Moreover, most of SNN designs are derived from the Artificial Neural Networks, whose network operations are different from SNNs. These limitations hinder SNNs from reaching their full potential in accuracy and efficiency. Toward this, we propose HASNAS, a novel hardware-aware spiking neural architecture search (NAS) framework for neuromorphic CIM systems that finds an SNN that offers high accuracy under the given memory, area, latency, and energy constraints. To achieve this, HASNAS employs the following key steps: (1) optimizing SNN operations to achieve high accuracy, (2) developing an SNN architecture that facilitates an effective learning process, and (3) devising a systematic hardware-aware search algorithm to meet the constraints. The experimental results show that our HASNAS quickly finds an SNN that maintains high accuracy compared to the state-of-the-art by up to 11x speed-up, and meets the given constraints: 4x10^6 parameters of memory, 100mm^2 of area, 400ms of latency, and 120uJ energy consumption for CIFAR10 and CIFAR100; while the state-of-the-art fails to meet the constraints. In this manner, our HASNAS can enable efficient design automation for providing high-performance and energy-efficient neuromorphic CIM systems for diverse applications.
Read more7/2/2024
0
Graph is all you need? Lightweight data-agnostic neural architecture search without training
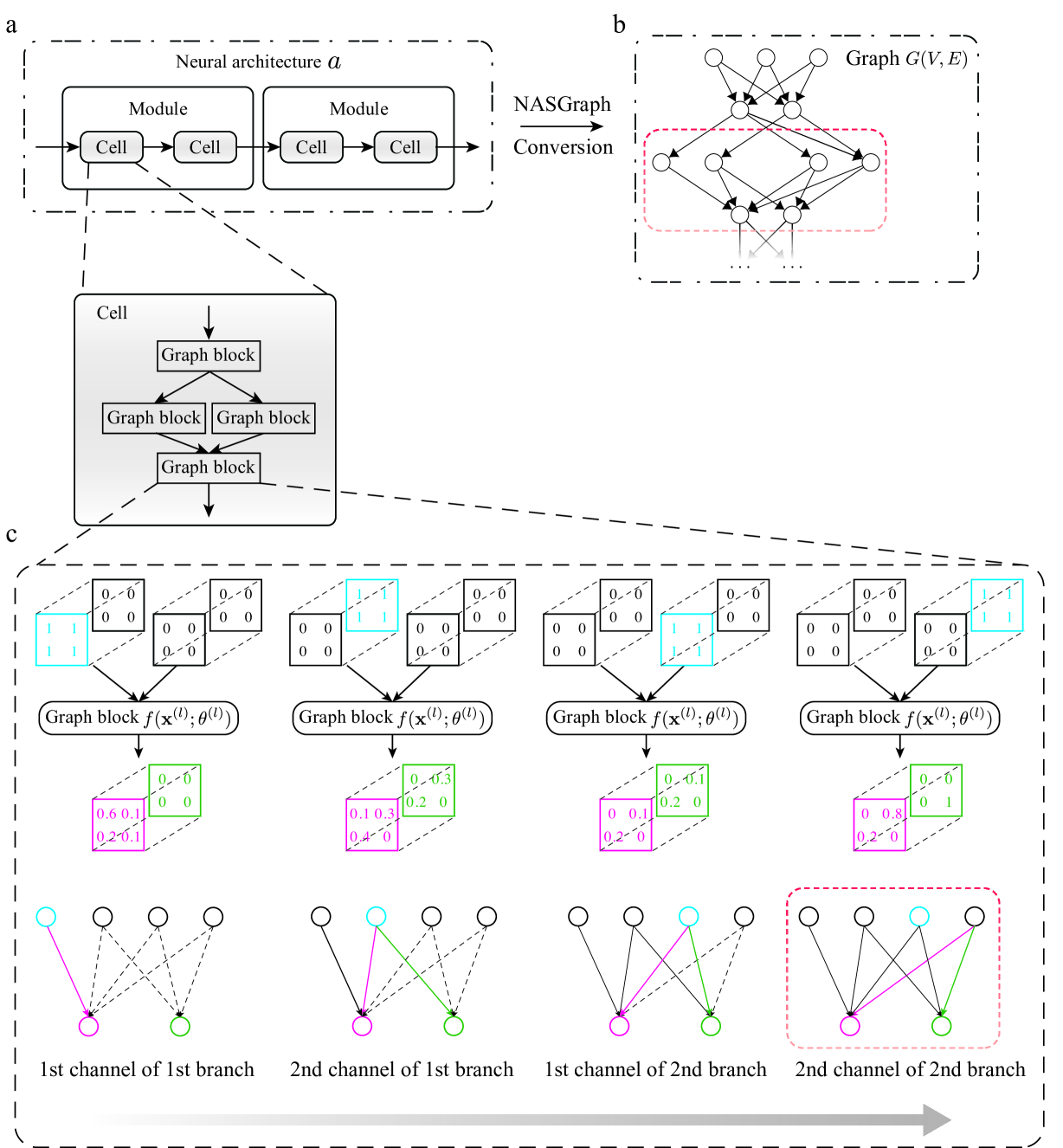
Zhenhan Huang, Tejaswini Pedapati, Pin-Yu Chen, Chunhen Jiang, Jianxi Gao
Neural architecture search (NAS) enables the automatic design of neural network models. However, training the candidates generated by the search algorithm for performance evaluation incurs considerable computational overhead. Our method, dubbed nasgraph, remarkably reduces the computational costs by converting neural architectures to graphs and using the average degree, a graph measure, as the proxy in lieu of the evaluation metric. Our training-free NAS method is data-agnostic and light-weight. It can find the best architecture among 200 randomly sampled architectures from NAS-Bench201 in 217 CPU seconds. Besides, our method is able to achieve competitive performance on various datasets including NASBench-101, NASBench-201, and NDS search spaces. We also demonstrate that nasgraph generalizes to more challenging tasks on Micro TransNAS-Bench-101.
Read more5/3/2024