Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning

0

Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
Xinlu Zhang, Zhiyu Zoey Chen, Xi Ye, Xianjun Yang, Lichang Chen, William Yang Wang, Linda Ruth Petzold
Instruction Fine-Tuning (IFT) significantly enhances the zero-shot capabilities of pretrained Large Language Models (LLMs). While coding data is known to boost reasoning abilities during LLM pretraining, its role in activating internal reasoning capacities during IFT remains understudied. This paper investigates a key question: How does coding data impact LLMs' reasoning capacities during the IFT stage? To explore this, we thoroughly examine the impact of coding data across different coding data proportions, model families, sizes, and reasoning domains, from various perspectives. Specifically, we create three IFT datasets with increasing coding data proportions, fine-tune six LLM backbones across different families and scales on these datasets, evaluate the tuned models' performance across twelve tasks in three reasoning domains, and analyze the outcomes from three broad-to-granular perspectives: overall, domain-level, and task-specific. Our holistic analysis provides valuable insights in each perspective. First, coding data tuning enhances the overall reasoning capabilities of LLMs across different model families and scales. Moreover, the effect of coding data varies among different domains but shows consistent trends across model families and scales within each domain. Additionally, coding data generally yields comparable task-specific benefits across different model families, with the optimal coding data proportions in IFT datasets being task-specific.
Read more6/3/2024

0
How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, Jingren Zhou
Large language models (LLMs) with enormous pre-training tokens and parameters emerge diverse abilities, including math reasoning, code generation, and instruction following. These abilities are further enhanced by supervised fine-tuning (SFT). While the open-source community has explored ad-hoc SFT for enhancing individual capabilities, proprietary LLMs exhibit versatility across various skills. Therefore, understanding the facilitation of multiple abilities via SFT is paramount. In this study, we specifically focuses on the interplay of data composition between mathematical reasoning, code generation, and general human-aligning abilities during SFT. We propose four intriguing research questions to explore the association between model performance and various factors including data amount, composition ratio, model size and SFT strategies. Our experiments reveal that distinct capabilities scale differently and larger models generally show superior performance with same amount of data. Mathematical reasoning and code generation consistently improve with increasing data amount, whereas general abilities plateau after roughly a thousand samples. Moreover, we observe data composition appears to enhance various abilities under limited data conditions, yet can lead to performance conflicts when data is plentiful. Our findings also suggest the amount of composition data influences performance more than the composition ratio. In analysis of SFT strategies, we find that sequentially learning multiple skills risks catastrophic forgetting. Our proposed Dual-stage Mixed Fine-tuning (DMT) strategy offers a promising solution to learn multiple abilities with different scaling patterns.
Read more6/10/2024

0
Learning or Self-aligning? Rethinking Instruction Fine-tuning
Mengjie Ren, Boxi Cao, Hongyu Lin, Cao Liu, Xianpei Han, Ke Zeng, Guanglu Wan, Xunliang Cai, Le Sun
Instruction Fine-tuning~(IFT) is a critical phase in building large language models~(LLMs). Previous works mainly focus on the IFT's role in the transfer of behavioral norms and the learning of additional world knowledge. However, the understanding of the underlying mechanisms of IFT remains significantly limited. In this paper, we design a knowledge intervention framework to decouple the potential underlying factors of IFT, thereby enabling individual analysis of different factors. Surprisingly, our experiments reveal that attempting to learn additional world knowledge through IFT often struggles to yield positive impacts and can even lead to markedly negative effects. Further, we discover that maintaining internal knowledge consistency before and after IFT is a critical factor for achieving successful IFT. Our findings reveal the underlying mechanisms of IFT and provide robust support for some very recent and potential future works.
Read more8/13/2024
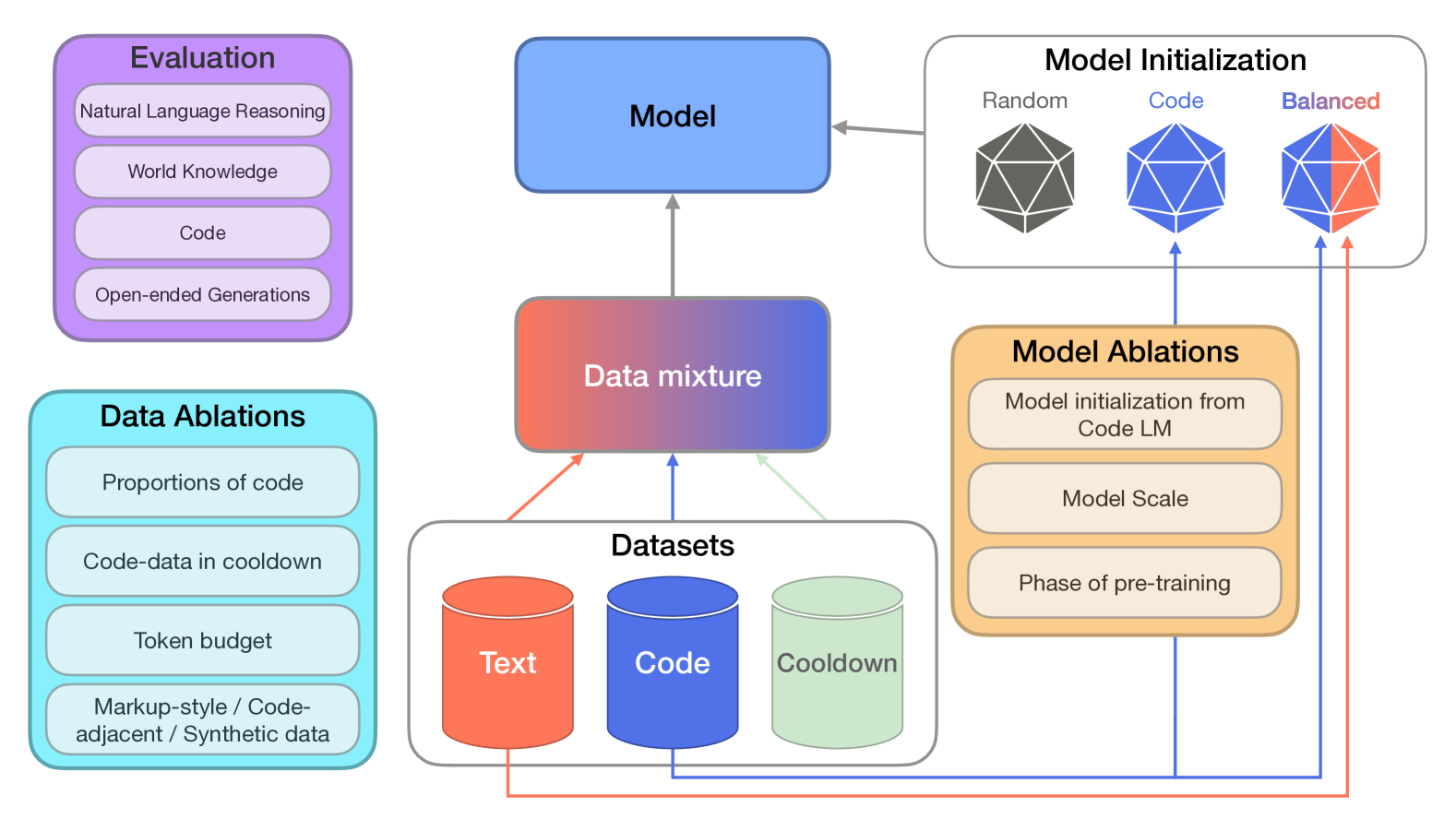
430
To Code, or Not To Code? Exploring Impact of Code in Pre-training
Viraat Aryabumi, Yixuan Su, Raymond Ma, Adrien Morisot, Ivan Zhang, Acyr Locatelli, Marzieh Fadaee, Ahmet Ustun, Sara Hooker
Including code in the pre-training data mixture, even for models not specifically designed for code, has become a common practice in LLMs pre-training. While there has been anecdotal consensus among practitioners that code data plays a vital role in general LLMs' performance, there is only limited work analyzing the precise impact of code on non-code tasks. In this work, we systematically investigate the impact of code data on general performance. We ask what is the impact of code data used in pre-training on a large variety of downstream tasks beyond code generation. We conduct extensive ablations and evaluate across a broad range of natural language reasoning tasks, world knowledge tasks, code benchmarks, and LLM-as-a-judge win-rates for models with sizes ranging from 470M to 2.8B parameters. Across settings, we find a consistent results that code is a critical building block for generalization far beyond coding tasks and improvements to code quality have an outsized impact across all tasks. In particular, compared to text-only pre-training, the addition of code results in up to relative increase of 8.2% in natural language (NL) reasoning, 4.2% in world knowledge, 6.6% improvement in generative win-rates, and a 12x boost in code performance respectively. Our work suggests investments in code quality and preserving code during pre-training have positive impacts.
Read more8/21/2024