Touch100k: A Large-Scale Touch-Language-Vision Dataset for Touch-Centric Multimodal Representation

0
Sign in to get full access
Overview
• This paper introduces Touch100k, a large-scale dataset that combines touch, language, and vision data to enable touch-centric multimodal representation learning.
• The dataset contains over 100,000 high-resolution images of objects, along with corresponding text descriptions and simulated touch data, aiming to facilitate research on multimodal perception and touch-based learning.
• The authors explore the potential of this dataset to advance multimodal large language models and probe the conceptual understanding of large visual-language models.
Plain English Explanation
The Touch100k dataset is a large collection of information that combines images of objects, text descriptions, and simulated touch data. The researchers created this dataset to help advance the field of multimodal learning, which involves training AI systems to understand and process information from multiple sensory inputs, like vision, language, and touch.
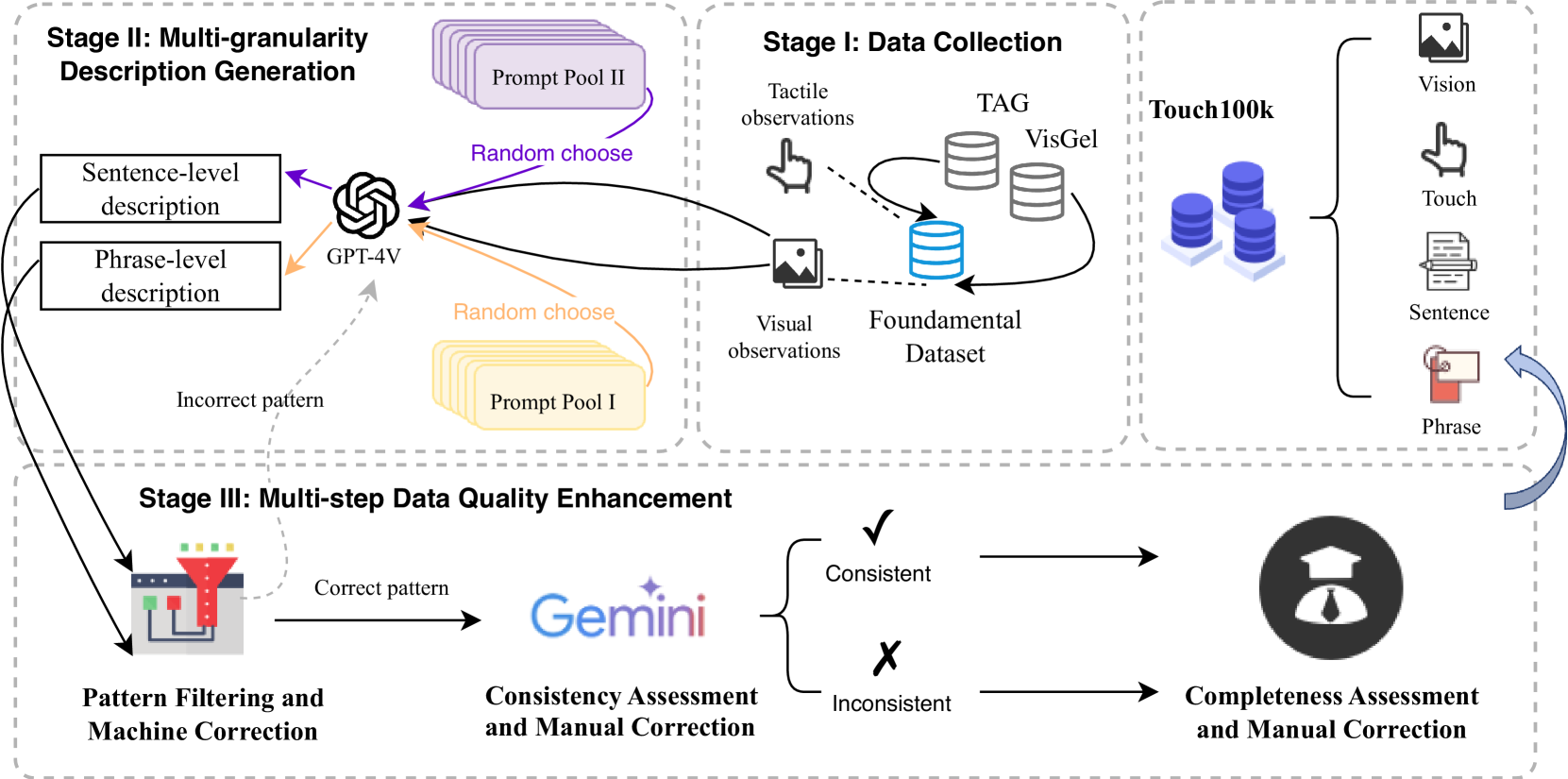
The dataset contains over 100,000 high-quality images of various objects, along with written descriptions of those objects and simulated touch data that mimics how a person might feel and interact with the objects. By having this rich, multimodal data, researchers can develop more advanced AI models that can perceive and reason about the world in a way that is closer to how humans experience it.
For example, these models could learn to understand not just what an object looks like, but also how it might feel to the touch and how that information relates to the language used to describe it. This could lead to AI systems that are better at tasks like object recognition, manipulation, and language understanding, with potential applications in areas like robotics, assistive technology, and human-AI interaction.
Technical Explanation
The Touch100k dataset was created to enable research on touch-centric multimodal representation learning. It contains over 100,000 high-resolution images of various objects, along with corresponding text descriptions and simulated touch data. The touch data was generated using a physics-based simulation engine and includes information about the object's surface properties, such as texture, hardness, and thermal conductivity.
To collect the dataset, the authors leveraged a crowdsourcing platform to gather text descriptions for each object image. The descriptions were then filtered and curated to ensure quality and consistency. The simulated touch data was generated using a custom pipeline that combines object 3D models, material properties, and physic-based interaction models.
The authors demonstrate the potential of the Touch100k dataset by exploring its use in two main areas:
-
Multimodal large language models: The authors fine-tune large language models on the Touch100k dataset to investigate how the addition of touch data can improve their performance on tasks like object recognition and language understanding.
-
Probing conceptual understanding of large visual-language models: The authors use the dataset to probe the internal representations of large visual-language models, examining how they encode and reason about the relationships between visual, linguistic, and touch-based information.
The Touch100k dataset aims to advance the field of multimodal perception and touch-based learning, providing a rich, large-scale resource for researchers to explore the integration of touch, language, and vision in artificial intelligence.
Critical Analysis
The Touch100k dataset represents a significant contribution to the field of multimodal perception and touch-based learning. By providing a large-scale dataset that combines visual, linguistic, and simulated touch data, the authors enable researchers to investigate more comprehensive and grounded representations of the physical world.
However, the authors acknowledge several limitations of the dataset. First, the simulated touch data may not fully capture the nuances and complexities of real-world tactile interactions, which could limit the transferability of models trained on the dataset to real-world applications. Additionally, the dataset is primarily focused on static object images, which may not adequately capture the dynamic and interactive nature of touch-based perception and manipulation.
Further research is needed to explore ways to incorporate more diverse and ecologically valid touch data, as well as to investigate the integration of touch with other modalities, such as audio and proprioception, to create a more holistic understanding of the physical world. Additionally, the authors note the importance of addressing potential biases and ethical considerations in the collection and use of such multimodal datasets.
Conclusion
The Touch100k dataset represents a significant step forward in the field of multimodal perception and touch-based learning. By providing a large-scale dataset that combines visual, linguistic, and simulated touch data, the authors enable researchers to investigate more comprehensive and grounded representations of the physical world.
The dataset has the potential to advance the development of multimodal large language models and to provide new insights into the conceptual understanding of large visual-language models. However, further research is needed to address the limitations of the dataset and to explore the integration of touch with other modalities for a more holistic understanding of the physical world.
Overall, the Touch100k dataset is a valuable contribution to the field of AI and robotics, and its use in research and development could lead to the creation of more intelligent and capable systems that can better perceive, interact with, and understand the physical environment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!