Towards Bridging the Cross-modal Semantic Gap for Multi-modal Recommendation

0

Sign in to get full access
Overview
- This paper explores approaches to bridge the "cross-modal semantic gap" in multi-modal recommendation systems.
- The cross-modal semantic gap refers to the challenge of aligning the representations of data from different modalities (e.g., text and images) so they can be effectively combined.
- The paper examines various techniques to mitigate this gap, including Mitigating the Gap: Investigating Approaches for Improving Cross-Modal Representation, Gentle CLIP: Exploring Aligned Semantic Representations for Low-Quality Inputs, and Leveraging Cross-Modal Neighbor Representation for Improved CLIP.
- The findings aim to contribute to the broader field of Multimodal Pretraining, Adaptation, Generation, and Recommendation: A Survey and Linking Representations for Multimodal Contrastive Learning.
Plain English Explanation
The paper focuses on a challenge in multi-modal recommendation systems, which are systems that make recommendations based on data from different sources, like text and images. The challenge is that the representations (the way the data is encoded) for these different data types don't always align well, which can make it difficult to effectively combine them.
The researchers explore various techniques to address this "cross-modal semantic gap." For example, they look at ways to improve how the system aligns the representations of text and images, even when the images are low quality. They also investigate leveraging the relationships between different data points to improve the overall representation.
The goal is to contribute to the broader field of multi-modal machine learning, which is about training models to understand and generate content across different data modalities, like text, images, and audio. Improving cross-modal representation is an important step towards building more powerful and versatile recommendation systems.
Technical Explanation
The paper investigates approaches to bridge the "cross-modal semantic gap" in multi-modal recommendation systems. The cross-modal semantic gap refers to the challenge of aligning the representations of data from different modalities, such as text and images, so they can be effectively combined.
The researchers examine several techniques to mitigate this gap. One approach, Mitigating the Gap: Investigating Approaches for Improving Cross-Modal Representation, focuses on improving the alignment of text and image representations. Another, Gentle CLIP: Exploring Aligned Semantic Representations for Low-Quality Inputs, explores ways to maintain aligned representations even when working with low-quality image inputs.
The paper also discusses Leveraging Cross-Modal Neighbor Representation for Improved CLIP, which looks at using the relationships between data points to enhance the overall cross-modal representation.
These findings contribute to the broader field of Multimodal Pretraining, Adaptation, Generation, and Recommendation: A Survey and Linking Representations for Multimodal Contrastive Learning, which explore techniques for training and using multi-modal machine learning models.
Critical Analysis
The paper provides a comprehensive overview of the challenges and approaches related to bridging the cross-modal semantic gap in multi-modal recommendation systems. The researchers examine several promising techniques, each with its own strengths and limitations.
One potential limitation is the reliance on specific pre-trained models, such as CLIP, which may not generalize well to all types of data and applications. Additionally, the effectiveness of the proposed methods may be influenced by the quality and diversity of the training data, which is not extensively discussed.
Further research could explore the robustness of these approaches to noisy or incomplete data, as well as their scalability to large-scale, real-world recommendation systems. Investigating the trade-offs between model complexity, computational efficiency, and cross-modal alignment accuracy could also yield valuable insights.
Conclusion
This paper addresses a critical challenge in multi-modal recommendation systems: the cross-modal semantic gap. By exploring various techniques to bridge this gap, the researchers aim to contribute to the development of more powerful and versatile recommendation systems that can effectively leverage data from multiple modalities.
The findings provide a solid foundation for further research and practical applications in the field of multi-modal machine learning. As the demand for personalized and contextualized recommendations continues to grow, the ability to accurately align and integrate data from diverse sources will become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Bridging the Cross-modal Semantic Gap for Multi-modal Recommendation
Xinglong Wu, Anfeng Huang, Hongwei Yang, Hui He, Yu Tai, Weizhe Zhang
Multi-modal recommendation greatly enhances the performance of recommender systems by modeling the auxiliary information from multi-modality contents. Most existing multi-modal recommendation models primarily exploit multimedia information propagation processes to enrich item representations and directly utilize modal-specific embedding vectors independently obtained from upstream pre-trained models. However, this might be inappropriate since the abundant task-specific semantics remain unexplored, and the cross-modality semantic gap hinders the recommendation performance. Inspired by the recent progress of the cross-modal alignment model CLIP, in this paper, we propose a novel textbf{CLIP} textbf{E}nhanced textbf{R}ecommender (textbf{CLIPER}) framework to bridge the semantic gap between modalities and extract fine-grained multi-view semantic information. Specifically, we introduce a multi-view modality-alignment approach for representation extraction and measure the semantic similarity between modalities. Furthermore, we integrate the multi-view multimedia representations into downstream recommendation models. Extensive experiments conducted on three public datasets demonstrate the consistent superiority of our model over state-of-the-art multi-modal recommendation models.
Read more7/9/2024

0
X-InstructBLIP: A Framework for aligning X-Modal instruction-aware representations to LLMs and Emergent Cross-modal Reasoning
Artemis Panagopoulou, Le Xue, Ning Yu, Junnan Li, Dongxu Li, Shafiq Joty, Ran Xu, Silvio Savarese, Caiming Xiong, Juan Carlos Niebles
Recent research has achieved significant advancements in visual reasoning tasks through learning image-to-language projections and leveraging the impressive reasoning abilities of Large Language Models (LLMs). This paper introduces an efficient and effective framework that integrates multiple modalities (images, 3D, audio and video) to a frozen LLM and demonstrates an emergent ability for cross-modal reasoning (2+ modality inputs). Our approach explores two distinct projection mechanisms: Q-Formers and Linear Projections (LPs). Through extensive experimentation across all four modalities on 16 benchmarks, we explore both methods and assess their adaptability in integrated and separate cross-modal reasoning. The Q-Former projection demonstrates superior performance in single modality scenarios and adaptability in joint versus discriminative reasoning involving two or more modalities. However, it exhibits lower generalization capabilities than linear projection in contexts where task-modality data are limited. To enable this framework, we devise a scalable pipeline that automatically generates high-quality, instruction-tuning datasets from readily available captioning data across different modalities, and contribute 24K QA data for audio and 250K QA data for 3D. To facilitate further research in cross-modal reasoning, we introduce the DisCRn (Discriminative Cross-modal Reasoning) benchmark comprising 9K audio-video QA samples and 28K image-3D QA samples that require the model to reason discriminatively across disparate input modalities.
Read more9/10/2024

0
Multi-Modal Adapter for Vision-Language Models
Dominykas Seputis, Serghei Mihailov, Soham Chatterjee, Zehao Xiao
Large pre-trained vision-language models, such as CLIP, have demonstrated state-of-the-art performance across a wide range of image classification tasks, without requiring retraining. Few-shot CLIP is competitive with existing specialized architectures that were trained on the downstream tasks. Recent research demonstrates that the performance of CLIP can be further improved using lightweight adaptation approaches. However, previous methods adapt different modalities of the CLIP model individually, ignoring the interactions and relationships between visual and textual representations. In this work, we propose Multi-Modal Adapter, an approach for Multi-Modal adaptation of CLIP. Specifically, we add a trainable Multi-Head Attention layer that combines text and image features to produce an additive adaptation of both. Multi-Modal Adapter demonstrates improved generalizability, based on its performance on unseen classes compared to existing adaptation methods. We perform additional ablations and investigations to validate and interpret the proposed approach.
Read more9/6/2024
0
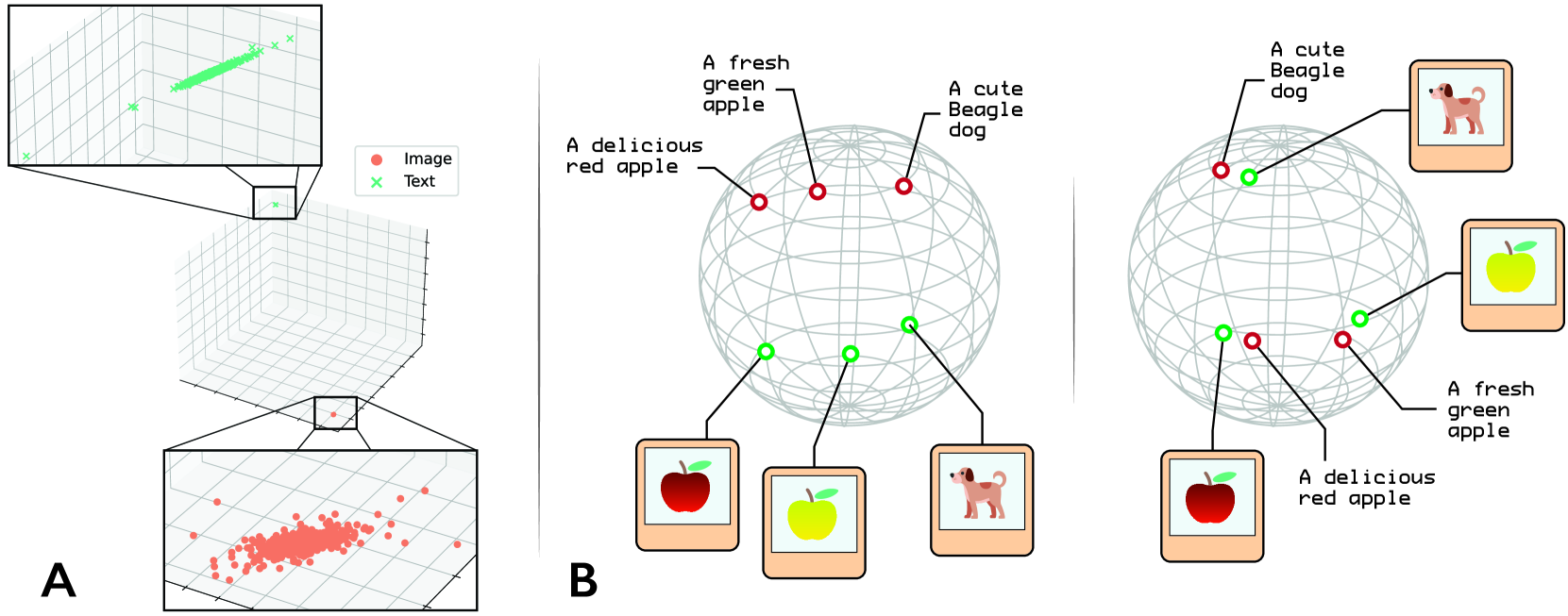
Mitigate the Gap: Investigating Approaches for Improving Cross-Modal Alignment in CLIP
Sedigheh Eslami, Gerard de Melo
Contrastive Language--Image Pre-training (CLIP) has manifested remarkable improvements in zero-shot classification and cross-modal vision-language tasks. Yet, from a geometrical point of view, the CLIP embedding space has been found to have a pronounced modality gap. This gap renders the embedding space overly sparse and disconnected, with different modalities being densely distributed in distinct subregions of the hypersphere. In this work, we aim at answering three main questions: 1. Does sharing the parameter space between the multi-modal encoders reduce the modality gap? 2. Can the gap be mitigated by pushing apart the uni-modal embeddings via intra-modality separation? 3. How do these gap reduction approaches affect the downstream performance? We design AlignCLIP, in order to answer these questions and through extensive experiments, we show that AlignCLIP achieves noticeable enhancements in the cross-modal alignment of the embeddings, and thereby, reduces the modality gap, while improving the performance across several zero-shot and fine-tuning downstream evaluations.
Read more9/17/2024