Extreme Miscalibration and the Illusion of Adversarial Robustness

0
Sign in to get full access
Overview
- This paper investigates the issue of extreme miscalibration in deep neural networks, which can create the illusion of adversarial robustness.
- The authors find that even models that appear to be highly robust to adversarial attacks can actually be extremely miscalibrated, meaning their confidence scores do not accurately reflect the true likelihood of their predictions being correct.
- This miscalibration can lead to a false sense of security, as models may appear to be robust when they are actually quite vulnerable.
Plain English Explanation
The paper examines a problem with deep learning models where they can be extremely miscalibrated. This means the model's confidence scores don't accurately match the true likelihood of its predictions being correct. Even models that seem very robust to adversarial attacks can have this issue.
Imagine you're buying a used car and the salesperson tells you it's in perfect condition. But when you take it to a mechanic, they find all kinds of serious problems that the salesperson had hidden. The car may have looked fine on the outside, just like an AI model can appear to be secure against attacks, but the underlying issues are actually quite severe. This calibration problem can create an illusion of robustness that isn't real.
The researchers wanted to understand this phenomenon better and find ways to address it. Fixing this miscalibration is important because it can lead to a false sense of security, where models seem much more reliable than they actually are. This could be very risky, especially for sensitive applications like self-driving cars or medical diagnosis.
Technical Explanation
The paper examines the issue of extreme miscalibration in deep neural networks and how it can create the appearance of adversarial robustness. The authors find that even models that seem highly robust to adversarial attacks can actually be extremely miscalibrated, meaning their confidence scores do not accurately reflect the true likelihood of their predictions being correct.
To investigate this, the researchers conduct a series of experiments on various network architectures and datasets. They find that standard evaluation metrics like accuracy can mask the underlying calibration issues, leading to a false sense of security about a model's adversarial robustness.
The authors suggest that this miscalibration phenomenon is quite widespread and can have significant implications, especially for safety-critical applications where overconfident but incorrect predictions could be highly problematic. They also explore potential approaches to address this issue, such as improved calibration techniques and more comprehensive evaluation metrics.
Critical Analysis
The paper provides valuable insights into the issue of extreme miscalibration in deep neural networks and its potential impact on the perception of adversarial robustness. The authors' experimental findings clearly demonstrate the pervasiveness of this problem and the limitations of standard evaluation metrics in capturing it.
One limitation of the research is that it focuses primarily on image classification tasks, and it would be interesting to see if similar patterns of miscalibration exist in other domains, such as large language models. Additionally, the paper does not delve deeply into the underlying causes of this miscalibration, which could be an area for further investigation.
While the authors propose some potential solutions, such as improved calibration techniques, more research is needed to develop practical and scalable approaches to address this issue. Ultimately, the work highlights the importance of going beyond standard accuracy metrics and carefully evaluating the true reliability and robustness of deep learning models, especially in safety-critical applications.
Conclusion
This paper sheds light on a critical issue in deep learning: the phenomenon of extreme miscalibration, which can create the illusion of adversarial robustness. The authors demonstrate that even models that appear highly robust can be severely miscalibrated, with their confidence scores not accurately reflecting the true likelihood of their predictions being correct.
This finding has significant implications for the real-world deployment of deep learning systems, as it suggests that models may be much more vulnerable to adversarial attacks than commonly believed. Addressing this miscalibration problem is crucial to ensure the reliable and trustworthy application of these powerful AI technologies, particularly in safety-critical domains.
The paper serves as a valuable wake-up call for the AI research community, underscoring the importance of developing more comprehensive evaluation techniques and calibration methods to better understand and improve the reliability of deep neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Extreme Miscalibration and the Illusion of Adversarial Robustness
Vyas Raina, Samson Tan, Volkan Cevher, Aditya Rawal, Sheng Zha, George Karypis
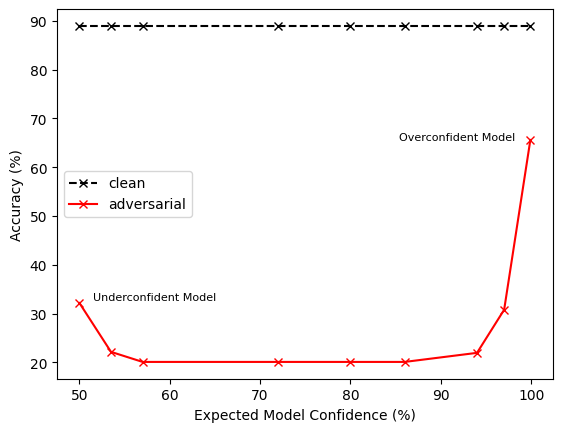
Deep learning-based Natural Language Processing (NLP) models are vulnerable to adversarial attacks, where small perturbations can cause a model to misclassify. Adversarial Training (AT) is often used to increase model robustness. However, we have discovered an intriguing phenomenon: deliberately or accidentally miscalibrating models masks gradients in a way that interferes with adversarial attack search methods, giving rise to an apparent increase in robustness. We show that this observed gain in robustness is an illusion of robustness (IOR), and demonstrate how an adversary can perform various forms of test-time temperature calibration to nullify the aforementioned interference and allow the adversarial attack to find adversarial examples. Hence, we urge the NLP community to incorporate test-time temperature scaling into their robustness evaluations to ensure that any observed gains are genuine. Finally, we show how the temperature can be scaled during textit{training} to improve genuine robustness.
Read more6/3/2024
🔎
0
Towards Certification of Uncertainty Calibration under Adversarial Attacks
Cornelius Emde, Francesco Pinto, Thomas Lukasiewicz, Philip H. S. Torr, Adel Bibi
Since neural classifiers are known to be sensitive to adversarial perturbations that alter their accuracy, textit{certification methods} have been developed to provide provable guarantees on the insensitivity of their predictions to such perturbations. Furthermore, in safety-critical applications, the frequentist interpretation of the confidence of a classifier (also known as model calibration) can be of utmost importance. This property can be measured via the Brier score or the expected calibration error. We show that attacks can significantly harm calibration, and thus propose certified calibration as worst-case bounds on calibration under adversarial perturbations. Specifically, we produce analytic bounds for the Brier score and approximate bounds via the solution of a mixed-integer program on the expected calibration error. Finally, we propose novel calibration attacks and demonstrate how they can improve model calibration through textit{adversarial calibration training}.
Read more5/24/2024
🎲
0
How adversarial attacks can disrupt seemingly stable accurate classifiers
Oliver J. Sutton, Qinghua Zhou, Ivan Y. Tyukin, Alexander N. Gorban, Alexander Bastounis, Desmond J. Higham
Adversarial attacks dramatically change the output of an otherwise accurate learning system using a seemingly inconsequential modification to a piece of input data. Paradoxically, empirical evidence indicates that even systems which are robust to large random perturbations of the input data remain susceptible to small, easily constructed, adversarial perturbations of their inputs. Here, we show that this may be seen as a fundamental feature of classifiers working with high dimensional input data. We introduce a simple generic and generalisable framework for which key behaviours observed in practical systems arise with high probability -- notably the simultaneous susceptibility of the (otherwise accurate) model to easily constructed adversarial attacks, and robustness to random perturbations of the input data. We confirm that the same phenomena are directly observed in practical neural networks trained on standard image classification problems, where even large additive random noise fails to trigger the adversarial instability of the network. A surprising takeaway is that even small margins separating a classifier's decision surface from training and testing data can hide adversarial susceptibility from being detected using randomly sampled perturbations. Counterintuitively, using additive noise during training or testing is therefore inefficient for eradicating or detecting adversarial examples, and more demanding adversarial training is required.
Read more9/10/2024

0
Adversarial Attacks and Dimensionality in Text Classifiers
Nandish Chattopadhyay, Atreya Goswami, Anupam Chattopadhyay
Adversarial attacks on machine learning algorithms have been a key deterrent to the adoption of AI in many real-world use cases. They significantly undermine the ability of high-performance neural networks by forcing misclassifications. These attacks introduce minute and structured perturbations or alterations in the test samples, imperceptible to human annotators in general, but trained neural networks and other models are sensitive to it. Historically, adversarial attacks have been first identified and studied in the domain of image processing. In this paper, we study adversarial examples in the field of natural language processing, specifically text classification tasks. We investigate the reasons for adversarial vulnerability, particularly in relation to the inherent dimensionality of the model. Our key finding is that there is a very strong correlation between the embedding dimensionality of the adversarial samples and their effectiveness on models tuned with input samples with same embedding dimension. We utilize this sensitivity to design an adversarial defense mechanism. We use ensemble models of varying inherent dimensionality to thwart the attacks. This is tested on multiple datasets for its efficacy in providing robustness. We also study the problem of measuring adversarial perturbation using different distance metrics. For all of the aforementioned studies, we have run tests on multiple models with varying dimensionality and used a word-vector level adversarial attack to substantiate the findings.
Read more4/4/2024