Towards Chapter-to-Chapter Context-Aware Literary Translation via Large Language Models

0

Sign in to get full access
Overview
- This paper explores using large language models for context-aware literary translation, where the translation of a chapter in a book takes into account the context of the full book.
- The authors propose a novel approach that leverages the capabilities of large language models to capture the context of a chapter within the broader narrative and use that to generate more coherent and nuanced translations.
- Key ideas include using the language model to encode the full book context, then using that context to guide the translation of individual chapters.
Plain English Explanation
The paper is looking at how we can use powerful AI language models to do a better job of translating books from one language to another. The challenge with translating books is that the meaning of a single chapter often depends on the overall story and context of the full book.
Efficiently Exploring Large Language Models for Document-Level and Adapting Large Language Models for Document-Level Machine have explored using language models for document-level tasks, which is relevant here.
The key idea in this paper is to use the language model to understand the full context of the book, and then use that broader understanding to guide the translation of each individual chapter. This allows the translation to be more coherent and fit better with the overall story, rather than just translating each chapter in isolation.
A Novel Paradigm for Boosting Translation Capabilities of Large Language and Escaping the Sentence-Level Paradigm in Machine Translation provide relevant background on using language models for more contextual translation.
The authors propose a specific technical approach to implement this idea, which involves encoding the full book context using the language model and then using that to guide the translation of each chapter. This allows the translation to be more sensitive to the overall narrative.
Technical Explanation
The paper proposes a novel approach for context-aware literary translation using large language models. The key idea is to leverage the ability of these models to capture the overall context and narrative of a full book, and then use that context to guide the translation of individual chapters.
GentransLATE: Large Language Models Are Generative, Multilingual has explored using language models for multilingual generation, which is relevant here.
Specifically, the authors first use the language model to encode the full book context, generating a representation that captures the high-level narrative, themes, and relationships between characters and events. They then use this encoded context to guide the translation of each individual chapter, allowing the translation to be more coherent and sensitive to the broader story.
The technical approach involves fine-tuning the language model on the full book to capture the overall context, then using that context representation as an additional input to the chapter-level translation model. This allows the translation to draw upon the broader understanding of the narrative, rather than translating each chapter in isolation.
The authors evaluate their approach on a dataset of literary works, comparing it to standard sentence-level translation baselines as well as other document-level approaches. Their results show significant improvements in translation quality, as measured by both automatic metrics and human evaluations.
Critical Analysis
The paper presents a compelling approach for leveraging large language models to improve the coherence and quality of literary translation. The key insight of using the models to capture the full book context and then applying that to guide chapter-level translation is a novel and promising direction.
That said, the paper does acknowledge some limitations and areas for future work. For example, the authors note that their approach relies on having access to the full book text during translation, which may not always be feasible in real-world scenarios. Efficiently Exploring Large Language Models for Document-Level discusses some techniques for working with partial document context.
Additionally, while the results show significant improvements, there is still room for further refinement and optimization of the technical approach. The authors suggest exploring alternative ways of incorporating the book-level context, as well as investigating the impact of different language model architectures and fine-tuning strategies.
Another potential area for further research would be to examine the generalization of this approach beyond literary works, to see if it can be applied effectively to other types of long-form, narrative-driven content, such as screenplays or historical documents. Adapting Large Language Models for Document-Level Machine discusses some of the broader applications of document-level language models.
Overall, this paper presents a novel and promising direction for improving literary translation using large language models, and the authors have identified several interesting avenues for future work in this area.
Conclusion
This paper introduces a novel approach for context-aware literary translation using large language models. By leveraging the models' ability to capture the broader narrative and thematic context of a full book, the authors demonstrate significant improvements in the coherence and quality of chapter-level translations.
The key innovation is the idea of using the language model to encode the overall book context, and then using that contextual information to guide the translation of individual chapters. This allows the translations to be more sensitive to the broader story and characters, rather than just translating each chapter in isolation.
While the paper acknowledges some limitations and areas for further refinement, the results suggest this is a promising direction for improving literary translation, with potential applications beyond just books to other long-form, narrative-driven content. The authors have identified several interesting avenues for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Chapter-to-Chapter Context-Aware Literary Translation via Large Language Models
Linghao Jin, Li An, Xuezhe Ma
Discourse phenomena in existing document-level translation datasets are sparse, which has been a fundamental obstacle in the development of context-aware machine translation models. Moreover, most existing document-level corpora and context-aware machine translation methods rely on an unrealistic assumption on sentence-level alignments. To mitigate these issues, we first curate a novel dataset of Chinese-English literature, which consists of 160 books with intricate discourse structures. Then, we propose a more pragmatic and challenging setting for context-aware translation, termed chapter-to-chapter (Ch2Ch) translation, and investigate the performance of commonly-used machine translation models under this setting. Furthermore, we introduce a potential approach of finetuning large language models (LLMs) within the domain of Ch2Ch literary translation, yielding impressive improvements over baselines. Through our comprehensive analysis, we unveil that literary translation under the Ch2Ch setting is challenging in nature, with respect to both model learning methods and translation decoding algorithms.
Read more7/15/2024
0
Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Menglong Cui, Jiangcun Du, Shaolin Zhu, Deyi Xiong
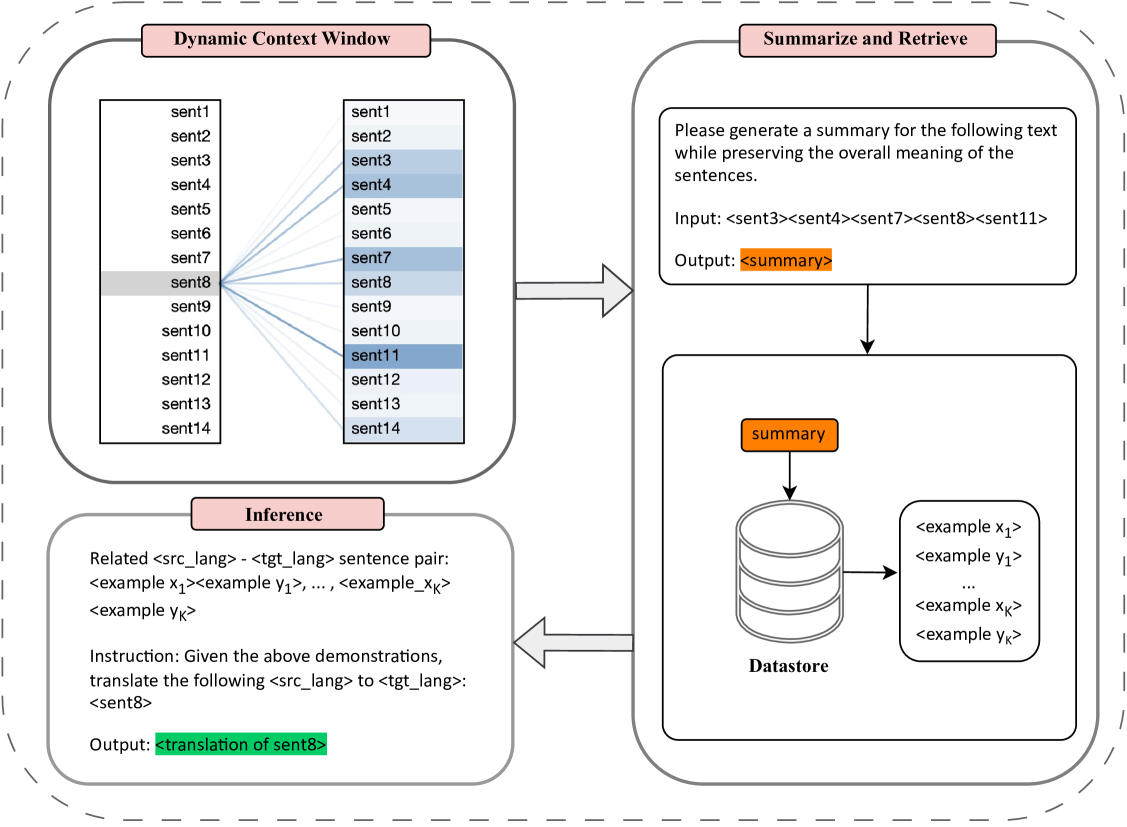
Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
Read more6/12/2024

0
Adapting Large Language Models for Document-Level Machine Translation
Minghao Wu, Thuy-Trang Vu, Lizhen Qu, George Foster, Gholamreza Haffari
Large language models (LLMs) have significantly advanced various natural language processing (NLP) tasks. Recent research indicates that moderately-sized LLMs often outperform larger ones after task-specific fine-tuning. This study focuses on adapting LLMs for document-level machine translation (DocMT) for specific language pairs. We first investigate the impact of prompt strategies on translation performance and then conduct extensive experiments using two fine-tuning methods, three LLM backbones, and 18 translation tasks across nine language pairs. Our results show that specialized models can sometimes surpass GPT-4 in translation performance but still face issues like off-target translation due to error propagation in decoding. We provide an in-depth analysis of these LLMs tailored for DocMT, examining translation errors, discourse phenomena, training strategies, the scaling law of parallel documents, recent test set evaluations, and zero-shot crosslingual transfer. Our findings highlight the strengths and limitations of LLM-based DocMT models and provide a foundation for future research.
Read more6/11/2024

0
A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
Read more4/16/2024