Towards Information Theory-Based Discovery of Equivariances
2310.16555
0
0
⚙️
Abstract
The presence of symmetries imposes a stringent set of constraints on a system. This constrained structure allows intelligent agents interacting with such a system to drastically improve the efficiency of learning and generalization, through the internalisation of the system's symmetries into their information-processing. In parallel, principled models of complexity-constrained learning and behaviour make increasing use of information-theoretic methods. Here, we wish to marry these two perspectives and understand whether and in which form the information-theoretic lens can see the effect of symmetries of a system. For this purpose, we propose a novel variant of the Information Bottleneck principle, which has served as a productive basis for many principled studies of learning and information-constrained adaptive behaviour. We show (in the discrete case and under a specific technical assumption) that our approach formalises a certain duality between symmetry and information parsimony: namely, channel equivariances can be characterised by the optimal mutual information-preserving joint compression of the channel's input and output. This information-theoretic treatment furthermore suggests a principled notion of soft equivariance, whose coarseness is measured by the amount of input-output mutual information preserved by the corresponding optimal compression. This new notion offers a bridge between the field of bounded rationality and the study of symmetries in neural representations. The framework may also allow (exact and soft) equivariances to be automatically discovered.
Create account to get full access
Overview
- This paper explores the use of information theory to discover equivariances in machine learning models.
- Equivariances are transformations that leave certain properties of a system unchanged, and are important for building efficient and robust models.
- The paper introduces a new framework called the Intertwining Information Bottleneck (IIB) that can automatically discover equivariances from data.
Plain English Explanation
In machine learning, models often need to be able to recognize patterns and relationships that remain the same even when the input data is transformed in certain ways. For example, an image recognition model should be able to identify the same object no matter how it is rotated or translated in the image. These types of transformations that leave the important properties of the system unchanged are called "equivariances."
Discovering equivariances in data can help machine learning models become more efficient and robust. However, it's not always easy to identify these equivariances, especially when dealing with complex, high-dimensional data.
This paper presents a new approach called the Intertwining Information Bottleneck (IIB) that uses information theory to automatically discover equivariances in data. The key idea is to find a compressed representation of the data that still preserves the information necessary to predict the output, while also being equivariant to certain transformations.
By using information-theoretic principles, the IIB framework can uncover equivariances without needing to specify them in advance. This makes it a powerful tool for building more efficient and generalizable machine learning models, with applications in areas like atomistic machine learning, equivariant quantum neural networks, and governing equation discovery.
Technical Explanation
The key insight of the Intertwining Information Bottleneck (IIB) framework is to jointly optimize for two objectives: (1) compressing the input data into a low-dimensional representation that still captures the information necessary to predict the output, and (2) ensuring that this compressed representation is equivariant to certain transformations of the input.
Formally, the IIB objective can be expressed as:
min I(X; Z) - βI(Y; Z) + γI(X; Z|T(X))
Where:
- X is the input data
- Y is the output to be predicted
- Z is the compressed representation
- T(X) are the transformations applied to the input
- I(·;·) denotes the mutual information between two variables
The first term encourages compression of the input, the second term encourages predictive accuracy, and the third term ensures equivariance to the transformations T(X). The trade-offs between these objectives are controlled by the hyperparameters β and γ.
The IIB framework can be applied to a variety of machine learning tasks, including canonization of invariant and equivariant learning and deriving generalization bounds for deep neural networks. The authors demonstrate its effectiveness on tasks like image classification, particle physics, and dynamical systems.
Critical Analysis
The Intertwining Information Bottleneck (IIB) framework presented in this paper is a novel and promising approach for discovering equivariances in machine learning models. By formulating the problem in information-theoretic terms, the authors are able to derive a principled objective function that can be optimized to find compressed representations that are both predictive and equivariant.
One potential limitation of the IIB framework is that it relies on the choice of transformations T(X) to be specified a priori. While the authors show that the framework can be applied to a range of different transformations, in practice it may not always be clear which transformations are most relevant for a given problem. Automating the discovery of the appropriate transformations could be an area for future research.
Additionally, the information-theoretic formulation of the IIB objective function relies on the estimation of mutual information, which can be challenging in high-dimensional settings. The authors discuss some techniques for addressing this, but further research may be needed to improve the scalability and robustness of the approach.
Overall, the Intertwining Information Bottleneck framework represents an innovative and principled approach to the discovery of equivariances in machine learning models. Further development and application of this framework could lead to significant advancements in the efficiency and generalization capabilities of a wide range of machine learning systems.
Conclusion
This paper introduces a novel information-theoretic framework called the Intertwining Information Bottleneck (IIB) for automatically discovering equivariances in machine learning models. By jointly optimizing for compression, predictive accuracy, and equivariance, the IIB framework can find low-dimensional representations of data that preserve the essential information while being invariant to certain transformations.
The IIB approach has the potential to significantly improve the efficiency and robustness of machine learning models across a variety of domains, from atomistic machine learning to equivariant quantum neural networks and governing equation discovery. By leveraging the principles of information theory, the IIB framework represents an important step towards the canonization of invariant and equivariant learning and deriving tighter generalization bounds for deep neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
Universal evaluation and design of imaging systems using information estimation
Henry Pinkard, Leyla Kabuli, Eric Markley, Tiffany Chien, Jiantao Jiao, Laura Waller
0
0
Information theory, which describes the transmission of signals in the presence of noise, has enabled the development of reliable communication systems that underlie the modern world. Imaging systems can also be viewed as a form of communication, in which information about the object is transmitted through images. However, the application of information theory to imaging systems has been limited by the challenges of accounting for their physical constraints. Here, we introduce a framework that addresses these limitations by modeling the probabilistic relationship between objects and their measurements. Using this framework, we develop a method to estimate information using only a dataset of noisy measurements, without making any assumptions about the image formation process. We demonstrate that these estimates comprehensively quantify measurement quality across a diverse range of imaging systems and applications. Furthermore, we introduce Information-Driven Encoder Analysis Learning (IDEAL), a technique to optimize the design of imaging hardware for maximum information capture. This work provides new insights into the fundamental performance limits of imaging systems and offers powerful new tools for their analysis and design.
6/3/2024
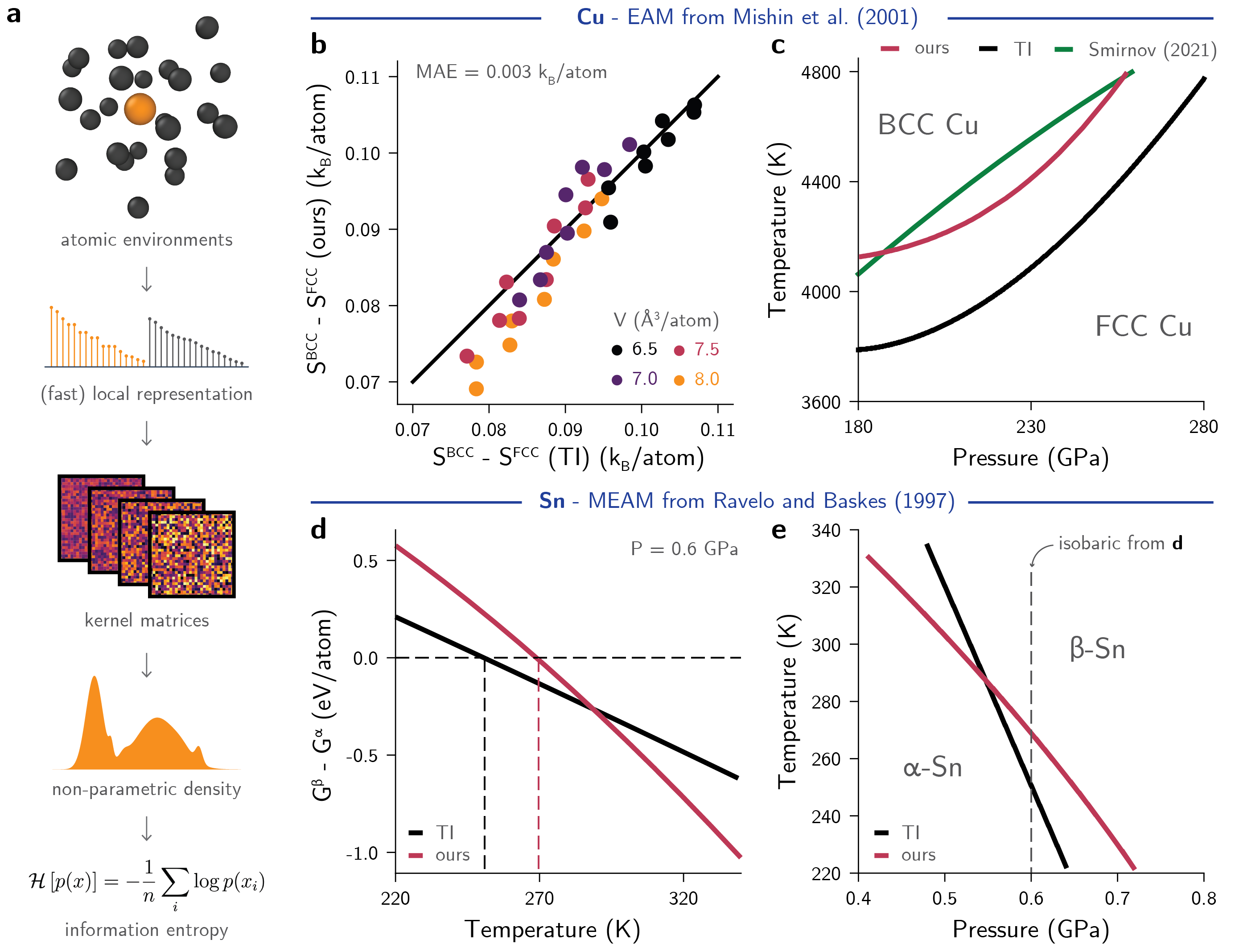
Information theory unifies atomistic machine learning, uncertainty quantification, and materials thermodynamics
Daniel Schwalbe-Koda, Sebastien Hamel, Babak Sadigh, Fei Zhou, Vincenzo Lordi
0
0
An accurate description of information is relevant for a range of problems in atomistic modeling, such as sampling methods, detecting rare events, analyzing datasets, or performing uncertainty quantification (UQ) in machine learning (ML)-driven simulations. Although individual methods have been proposed for each of these tasks, they lack a common theoretical background integrating their solutions. Here, we introduce an information theoretical framework that unifies predictions of phase transformations, kinetic events, dataset optimality, and model-free UQ from atomistic simulations, thus bridging materials modeling, ML, and statistical mechanics. We first demonstrate that, for a proposed representation, the information entropy of a distribution of atom-centered environments is a surrogate value for thermodynamic entropy. Using molecular dynamics (MD) simulations, we show that information entropy differences from trajectories can be used to build phase diagrams, identify rare events, and recover classical theories of nucleation. Building on these results, we use this general concept of entropy to quantify information in datasets for ML interatomic potentials (IPs), informing compression, explaining trends in testing errors, and evaluating the efficiency of active learning strategies. Finally, we propose a model-free UQ method for MLIPs using information entropy, showing it reliably detects extrapolation regimes, scales to millions of atoms, and goes beyond model errors. This method is made available as the package QUESTS: Quick Uncertainty and Entropy via STructural Similarity, providing a new unifying theory for data-driven atomistic modeling and combining efforts in ML, first-principles thermodynamics, and simulations.
4/19/2024
🧠
Theory for Equivariant Quantum Neural Networks
Quynh T. Nguyen, Louis Schatzki, Paolo Braccia, Michael Ragone, Patrick J. Coles, Frederic Sauvage, Martin Larocca, M. Cerezo
0
0
Quantum neural network architectures that have little-to-no inductive biases are known to face trainability and generalization issues. Inspired by a similar problem, recent breakthroughs in machine learning address this challenge by creating models encoding the symmetries of the learning task. This is materialized through the usage of equivariant neural networks whose action commutes with that of the symmetry. In this work, we import these ideas to the quantum realm by presenting a comprehensive theoretical framework to design equivariant quantum neural networks (EQNN) for essentially any relevant symmetry group. We develop multiple methods to construct equivariant layers for EQNNs and analyze their advantages and drawbacks. Our methods can find unitary or general equivariant quantum channels efficiently even when the symmetry group is exponentially large or continuous. As a special implementation, we show how standard quantum convolutional neural networks (QCNN) can be generalized to group-equivariant QCNNs where both the convolution and pooling layers are equivariant to the symmetry group. We then numerically demonstrate the effectiveness of a SU(2)-equivariant QCNN over symmetry-agnostic QCNN on a classification task of phases of matter in the bond-alternating Heisenberg model. Our framework can be readily applied to virtually all areas of quantum machine learning. Lastly, we discuss about how symmetry-informed models such as EQNNs provide hopes to alleviate central challenges such as barren plateaus, poor local minima, and sample complexity.
5/14/2024

Symmetry-Informed Governing Equation Discovery
Jianke Yang, Wang Rao, Nima Dehmamy, Robin Walters, Rose Yu
0
0
Despite the advancements in learning governing differential equations from observations of dynamical systems, data-driven methods are often unaware of fundamental physical laws, such as frame invariance. As a result, these algorithms may search an unnecessarily large space and discover equations that are less accurate or overly complex. In this paper, we propose to leverage symmetry in automated equation discovery to compress the equation search space and improve the accuracy and simplicity of the learned equations. Specifically, we derive equivariance constraints from the time-independent symmetries of ODEs. Depending on the types of symmetries, we develop a pipeline for incorporating symmetry constraints into various equation discovery algorithms, including sparse regression and genetic programming. In experiments across a diverse range of dynamical systems, our approach demonstrates better robustness against noise and recovers governing equations with significantly higher probability than baselines without symmetry.
5/28/2024