Towards more realistic human motion prediction with attention to motion coordination
2404.03584
0
0

Abstract
Joint relation modeling is a curial component in human motion prediction. Most existing methods rely on skeletal-based graphs to build the joint relations, where local interactive relations between joint pairs are well learned. However, the motion coordination, a global joint relation reflecting the simultaneous cooperation of all joints, is usually weakened because it is learned from part to whole progressively and asynchronously. Thus, the final predicted motions usually appear unrealistic. To tackle this issue, we learn a medium, called coordination attractor (CA), from the spatiotemporal features of motion to characterize the global motion features, which is subsequently used to build new relative joint relations. Through the CA, all joints are related simultaneously, and thus the motion coordination of all joints can be better learned. Based on this, we further propose a novel joint relation modeling module, Comprehensive Joint Relation Extractor (CJRE), to combine this motion coordination with the local interactions between joint pairs in a unified manner. Additionally, we also present a Multi-timescale Dynamics Extractor (MTDE) to extract enriched dynamics from the raw position information for effective prediction. Extensive experiments show that the proposed framework outperforms state-of-the-art methods in both short- and long-term predictions on H3.6M, CMU-Mocap, and 3DPW.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a new approach for more realistic human motion prediction, focusing on modeling the coordination between different body joints.
- The key idea is to capture the complex dependencies and dynamics within the human body during motion by learning an "enriched" representation of the motion.
- The proposed model outperforms previous state-of-the-art methods on standard human motion prediction benchmarks.
Plain English Explanation
Predicting how people will move and what they will do next is an important task in fields like robotics, animation, and human-computer interaction. Towards more realistic human motion prediction with attention to motion coordination tackles this challenge by focusing on the coordination between different parts of the body.
When we move, our various body parts don't act independently - they work together in complex ways. For example, the movement of our arms is closely tied to the movement of our torso and legs. Previous motion prediction models have often overlooked these intricate relationships.
The key insight of this paper is that by explicitly modeling the dependencies between joints and body parts, we can generate more realistic and natural-looking motion predictions. The authors develop a neural network architecture that learns an "enriched" representation of human motion, capturing both the individual movement of each joint as well as how the joints coordinate with each other.
Tested on standard benchmarks, this approach outperforms previous state-of-the-art methods at forecasting future human poses and movements. The authors argue that this enhanced motion coordination modeling is a crucial step towards building AI systems that can better understand and anticipate human behavior.
Technical Explanation
Towards more realistic human motion prediction with attention to motion coordination introduces a novel neural network architecture for human motion prediction that focuses on modeling the complex coordination between different body joints.
The key components of their approach are:
-
Joint Relation Modeling: The model learns to capture the dependencies and interactions between different joints by applying attention mechanisms to model the pairwise relationships.
-
Enriched Dynamics Modeling: In addition to predicting the future poses of individual joints, the model also predicts the velocities and accelerations of the joints. This "enriched" representation allows the model to better capture the underlying dynamics of human motion.
-
Motion Coordination Modeling: The model fuses the joint relation and enriched dynamics representations to produce the final motion prediction, allowing it to jointly reason about the coordination between different body parts.
Experiments on standard human motion prediction benchmarks demonstrate that this approach outperforms previous state-of-the-art methods. The authors attribute the performance gains to the model's ability to better capture the intricate coordination that occurs during natural human movement.
Critical Analysis
The paper presents a compelling approach to human motion prediction that takes an important step towards more realistic and natural-looking motion forecasting. By explicitly modeling the coordination between body joints, the proposed model is able to generate more accurate predictions compared to prior work.
However, the paper does not address some potential limitations of the approach. For example, the model may struggle to generalize to highly dynamic or unpredictable motions, or to handle unusual or atypical human movements that deviate from the coordination patterns seen in the training data.
Additionally, the paper does not provide a thorough analysis of the model's failure cases or discuss potential biases that may be introduced by the dataset or the model architecture. Further research would be needed to better understand the strengths, weaknesses, and broader applicability of this motion prediction approach.
Overall, this work represents an important step forward in human motion forecasting, but there remains ample room for continued research and improvement, particularly in ensuring the robustness and generalizability of such models. Expressive forecasting of 3D whole-body human motions and Recursive joint cross-modal attention for multimodal fusion are two other recent papers that have also explored novel approaches to this challenge.
Conclusion
This paper presents a new method for human motion prediction that focuses on modeling the coordination between different body joints. By learning an "enriched" representation of human motion that captures both individual joint dynamics and their interactions, the proposed model is able to generate more realistic and natural-looking motion forecasts.
The key innovation is the explicit modeling of joint relations and motion coordination, which allows the model to better capture the complex, interdependent nature of human movement. Tested on standard benchmarks, this approach outperforms previous state-of-the-art methods, demonstrating its potential to improve AI systems that need to understand and anticipate human behavior, such as in GEARS: Local Geometry-Aware Hand-Object Interaction or Co-speech gesture video generation via motion.
While more research is needed to fully understand the capabilities and limitations of this technique, this work represents an important advance in the field of human motion prediction and highlights the value of explicitly modeling the coordination and relationships within the human body.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
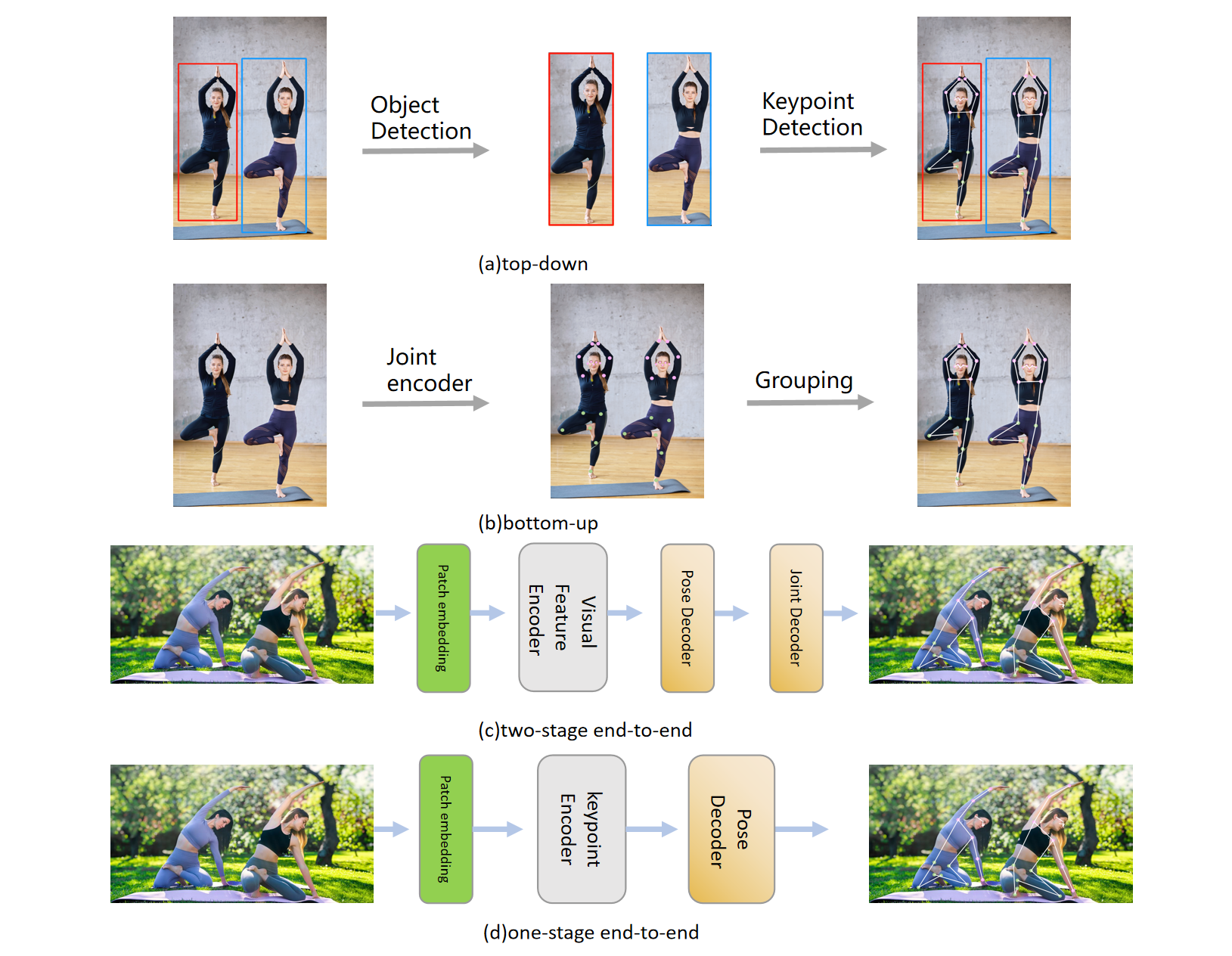
Joint Coordinate Regression and Association For Multi-Person Pose Estimation, A Pure Neural Network Approach
Dongyang Yu, Yunshi Xie, Wangpeng An, Li Zhang, Yufeng Yao
0
0
We introduce a novel one-stage end-to-end multi-person 2D pose estimation algorithm, known as Joint Coordinate Regression and Association (JCRA), that produces human pose joints and associations without requiring any post-processing. The proposed algorithm is fast, accurate, effective, and simple. The one-stage end-to-end network architecture significantly improves the inference speed of JCRA. Meanwhile, we devised a symmetric network structure for both the encoder and decoder, which ensures high accuracy in identifying keypoints. It follows an architecture that directly outputs part positions via a transformer network, resulting in a significant improvement in performance. Extensive experiments on the MS COCO and CrowdPose benchmarks demonstrate that JCRA outperforms state-of-the-art approaches in both accuracy and efficiency. Moreover, JCRA demonstrates 69.2 mAP and is 78% faster at inference acceleration than previous state-of-the-art bottom-up algorithms. The code for this algorithm will be publicly available.
4/22/2024
🔮
Multimodal Sense-Informed Prediction of 3D Human Motions
Zhenyu Lou, Qiongjie Cui, Haofan Wang, Xu Tang, Hong Zhou
0
0
Predicting future human pose is a fundamental application for machine intelligence, which drives robots to plan their behavior and paths ahead of time to seamlessly accomplish human-robot collaboration in real-world 3D scenarios. Despite encouraging results, existing approaches rarely consider the effects of the external scene on the motion sequence, leading to pronounced artifacts and physical implausibilities in the predictions. To address this limitation, this work introduces a novel multi-modal sense-informed motion prediction approach, which conditions high-fidelity generation on two modal information: external 3D scene, and internal human gaze, and is able to recognize their salience for future human activity. Furthermore, the gaze information is regarded as the human intention, and combined with both motion and scene features, we construct a ternary intention-aware attention to supervise the generation to match where the human wants to reach. Meanwhile, we introduce semantic coherence-aware attention to explicitly distinguish the salient point clouds and the underlying ones, to ensure a reasonable interaction of the generated sequence with the 3D scene. On two real-world benchmarks, the proposed method achieves state-of-the-art performance both in 3D human pose and trajectory prediction.
5/7/2024
A Mixture of Experts Approach to 3D Human Motion Prediction
Edmund Shieh, Joshua Lee Franco, Kang Min Bae, Tej Lalvani
0
0
This project addresses the challenge of human motion prediction, a critical area for applications such as au- tonomous vehicle movement detection. Previous works have emphasized the need for low inference times to provide real time performance for applications like these. Our primary objective is to critically evaluate existing model ar- chitectures, identifying their advantages and opportunities for improvement by replicating the state-of-the-art (SOTA) Spatio-Temporal Transformer model as best as possible given computational con- straints. These models have surpassed the limitations of RNN-based models and have demonstrated the ability to generate plausible motion sequences over both short and long term horizons through the use of spatio-temporal rep- resentations. We also propose a novel architecture to ad- dress challenges of real time inference speed by incorpo- rating a Mixture of Experts (MoE) block within the Spatial- Temporal (ST) attention layer. The particular variation that is used is Soft MoE, a fully-differentiable sparse Transformer that has shown promising ability to enable larger model capacity at lower inference cost. We make out code publicly available at https://github.com/edshieh/motionprediction
5/13/2024

TrajPRed: Trajectory Prediction with Region-based Relation Learning
Chen Zhou, Ghassan AlRegib, Armin Parchami, Kunjan Singh
0
0
Forecasting human trajectories in traffic scenes is critical for safety within mixed or fully autonomous systems. Human future trajectories are driven by two major stimuli, social interactions, and stochastic goals. Thus, reliable forecasting needs to capture these two stimuli. Edge-based relation modeling represents social interactions using pairwise correlations from precise individual states. Nevertheless, edge-based relations can be vulnerable under perturbations. To alleviate these issues, we propose a region-based relation learning paradigm that models social interactions via region-wise dynamics of joint states, i.e., the changes in the density of crowds. In particular, region-wise agent joint information is encoded within convolutional feature grids. Social relations are modeled by relating the temporal changes of local joint information from a global perspective. We show that region-based relations are less susceptible to perturbations. In order to account for the stochastic individual goals, we exploit a conditional variational autoencoder to realize multi-goal estimation and diverse future prediction. Specifically, we perform variational inference via the latent distribution, which is conditioned on the correlation between input states and associated target goals. Sampling from the latent distribution enables the framework to reliably capture the stochastic behavior in test data. We integrate multi-goal estimation and region-based relation learning to model the two stimuli, social interactions, and stochastic goals, in a prediction framework. We evaluate our framework on the ETH-UCY dataset and Stanford Drone Dataset (SDD). We show that the diverse prediction better fits the ground truth when incorporating the relation module. Our framework outperforms the state-of-the-art models on SDD by $27.61%$/$18.20%$ of ADE/FDE metrics.
4/11/2024